Thursday, 14 May 2009
Alpha3 ready to rumble!
So I’ve just tagged and cut Infinispan 4.0.0.ALPHA3. (Why are we starting with release 4.0.0? Read our FAQs!)
As I mentioned recently, I’ve implemented an uber-cool new asynchronous API for the cache and am dying to show it off/get some feedback on it. Yes, Alpha3 contains the async APIs. Why is this so important? Because it allows you to get the best of both worlds when it comes to synchronous and asynchronous network communications, and harnesses the parallelism and scalability you’d naturally expect from a halfway-decent data grid. And, as far as I know, we’re the first distributed cache - open or closed source - to offer such an API.
The release also contains other fixes, performance and stability improvements, and better javadocs throughout. One step closer to a full release.
Enjoy the release - available on our download page - and please do post feedback on the Infinispan User Forums.
Cheers Manik
Tags: release asynchronous
Wednesday, 13 May 2009
What's so cool about an asynchronous API?
Inspired by some thoughts from a recent conversation with JBoss Messaging’s Tim Fox, I’ve decided to go ahead and implement a new, asynchronous API for Infinispan.
To sum things up, this new API - additional methods on Cache - allow for asynchronous versions of put(), putIfAbsent(), putAll(), remove(), replace(), clear() and their various overloaded forms. Unimaginatively called putAsync(), putIfAbsentAsync(), etc., these new methods return a Future rather than the expected return type. E.g.,
V put(K key, V value);
Future<V> putAsync(K key, V value);
boolean remove(K key, V value);
Future<Boolean> removeAsync(K key, V value);
void clear();
Future<Void> clearAsync();
// ... etc ...You guessed it, these methods do not block. They return immediately, and how cool is that! If you care about return values - or indeed simply want to wait until the operation completes - you do a Future.get(), which will block until the call completes. Why is this useful? Mainly because, in the case of clustered caches, it allows you to get the best of both worlds when it comes to synchronous and asynchronous mode transports.
Synchronous transports are normally recommended because of the guarantees they offer - the caller always knows that a call has properly propagated across the network, and is aware of any potential exceptions. However, asynchronous transports give you greater parallelism. You can start on the next operation even before the first one has made it across the network. But this is at a cost: losing out on the knowledge that a call has safely completed.
With this powerful new API though, you can have your cake and eat it too. Consider:
Cache<String, String> cache = getCache();
Future<String> f1 = cache.putAsync(k1, v1);
Future<String> f2 = cache.putAsync(k2, v2);
Future<String> f3 = cache.putAsync(k3, v3);
f1.get();
f2.get();
f3.get();The network calls - possibly the most expensive part of a clustered write - involved for the 3 put calls can now happen in parallel. This is even more useful if the cache is distributed, and k1, k2 and k3 map to different nodes in the cluster - the processing required to handle the put operation on the remote nodes can happen simultaneously, on different nodes. And all the same, when calling Future.get(), we block until the calls have completed successfully. And we are aware of any exceptions thrown. With this approach, elapsed time taken to process all 3 puts should - theoretically, anyway - only be as slow as the single, slowest put().
This new API is now in Infinispan’s trunk and yours to enjoy. It will be a main feature of my next release, which should be out in a few days. Please do give it a spin - I’d love to hear your thoughts and experiences.
Tags: asynchronous future API
Tuesday, 12 May 2009
Implementing a performant, thread-safe ordered data container
To achieve efficient ordering of entries in the DataContainer interface for configurations that support eviction, there was a need for a linked HashMap implementation that was thread-safe and performant. Below, I specifically discuss the implementations of the FIFODataContainer and LRUDataContainer in Infinispan 4.0.x. Wherever this document references FIFODataContainer, this also applies to LRUDataContainer - which extends FIFODataContainer. The only difference is that LRUDataContainer updates links whenever an entry is visited as well as added.
After analysing and considering a few different approaches, the one I settled on is a subset of the algorithms described by H. Sundell and P. Tsigas in their 2008 paper titled Lock-Free Deques and Doubly Linked Lists, combined with the approach used by Sun’s JDK6 for reference marking in ConcurrentSkipListMap's implementation.
Reference marking? What’s that?
Compare-and-swap (CAS) is a common technique today for atomically updating a variable or a reference without the use of a mutual exclusion mechanism like a lock. But this only works when you modify a single memory location at a time, be it a reference or a primitive. Sometimes you need to atomically update two separate bits of information in a single go, such as a reference, as well as some information about that reference. Hence reference marking. In C, this is sometimes done by making use of the assumption that an entire word in memory is not needed to store a pointer to another memory location, and some bits of this word can be used to store additional flags via bitmasking. This allows for atomic updates of both the reference and this extra information using a single CAS operation.
This is possible in Java too using AtomicMarkableReference, but is usually considered overly complex, slow and space-inefficient. Instead, what we do is borrow a technique from ConcurrentSkipListMap and use an intermediate, delegating entry. While this adds a little more complexity in traversal (you need to be aware of the presence of these marker entries when traversing the linked list), this performs better than an AtomicMarkableReference.
In this specific implementation, the 'extra information' stored in a reference is the fact that the entry holding the reference is in the process of being deleted. It is a common problem with lock-free linked lists when you have concurrent insert and delete operations that the newly inserted entry gets deleted as well, since it attaches itself to the entry being concurrently deleted. When the entry to be removed marks its references, however, this makes other threads aware of the fact and cause CAS operations on the reference to fail and retry.
Performance
Aside from maintaining order of entries and being thread-safe, performance was one of the other goals. The target is to achieve constant-time performance - O(1) - for all operations on DataContainer.
The clhttp://3.bp.blogspot.com/_ca0W9t-Ryos/SgGwA2iw_vI/AAAAAAAAAKA/TpVMWo2Rq9U/s1600-h/FIFODataContainer.jpeg[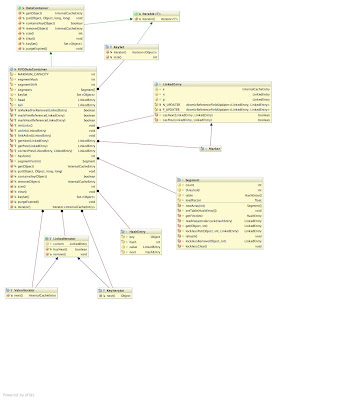 ]ass diagram (click to view in full-size) depicts the FIFODataContainer class. At its heart the FIFODataContainer mimics a JDK ConcurrentHashMap (CHM), making use of hashtable-like lockable segments. Unlike the segments in CHM, however, these segments are simpler as they support a much smaller set of operations.
]ass diagram (click to view in full-size) depicts the FIFODataContainer class. At its heart the FIFODataContainer mimics a JDK ConcurrentHashMap (CHM), making use of hashtable-like lockable segments. Unlike the segments in CHM, however, these segments are simpler as they support a much smaller set of operations.
Retrieving data from the container The use of segments allow for constant-time thread-safe get() and containsKey() operations. Iterators obtained from the DataContainer - which implements Iterable, and hence usable in for-each loops - and keySet() are immutable, thread-safe and efficient, using traversal of the linked list - making use of getNext() and getPrev() helpers. See below for details. Traversal is efficient and constant-time.
Updating the container When removing an entry, remove() locks the segment in question, removes the entry, and unlinks the entry. Both operations are thread-safe and constant-time. Locking the segment and removing the entry is pretty straightforward. Unlinking involves marking references, and then an attempt at CAS’ing next and previous references to bypass the removed entry. Order here is important - updates to the next reference needs to happen first, read on for more details as to why.
When performing a put(), the entry is created, segment locked and entry inserted into the segment. The entry is then inserted at the tail of the linked list. Again, both operations are thread-safe and constant-time. Linking at the tail involves careful CAS’ing of references on the new entry, the tail dummy entry and the former last entry in the list.
Maintaining a lock-free, concurrent doubly linked list It is important to note that the entries in this implementation are doubly linked. This is critical since, unlike the JDK’s ConcurrentSkipListMap, we use a hashtable to look up entries to be removed, to achieve constant time performance in lookup. Locating the parent entry to update a reference needs to be constant-time as well, and hence the need for a previous reference. Doubly-linked lists make things much trickier though, as there two references to update atomically (yes, that sounds wrong!)
Crucially, what we do not care about - and do not support - is reverse-order traversal. This means that we only really care about maintaining accuracy in the forward direction of the linked list, and treat the previous reference as an approximation to an entry somewhere behind the current entry. Previous references can then be corrected - using the correctPrev() helper method described below - to locate the precise entry behind the current entry. By placing greater importance on the forward direction of the list, this allows us to reliably CAS the forward reference even if the previous reference CAS fails. It is hence critical that whenever any references are updated, the next reference is CAS’d first, and only on this success the previous reference CAS is attempted. The same order applies with marking references. Also, it is important that any process that touches an entry that observes that the next pointer is marked but the previous pointer is not, attempts to mark the previous pointer before attempting any further steps.
The specific functions we need to expose, to support DataContainer operations, are:
void linkAtEnd(LinkedEntry entry);
void unlink(LinkedEntry entry);
LinkedEntry correctPrev(LinkedEntry suggestedPrev, LinkedEntry current);
LinkedEntry getNext(LinkedEntry current);
LinkedEntry getPrev(LinkedEntry current);These are exposed as protected final methods, usable by FIFODataContainer and its subclasses. The implementations themselves use a combination of CAS’s on a LinkedEntry’s next and previous pointers, marking references, and helper correction of previous pointers when using getNext() and getPrevious() to traverse the list. Note that it is important that only the last two methods are used when traversing rather than directly accessing a LinkedEntry’s references - since markers need to be stepped over and links corrected.
Please refer to Lock-Free Deques and Doubly Linked Lists for details of the algorithm steps.
Tags: algorithms eviction concurrency data structures
Sunday, 10 May 2009
jclouds-s3 beta released
![]()
jclouds-s3 is the glue between Infinispan and Amazon S3. jclouds provides a cachestore plugin that allows you to persist your infinispan cluster to S3.
Over the last few months, jclouds has evolved with Infinispan’s concurrent context.
Under the hood, jclouds is made for infinispan. Its non-blocking engine and FutureCommand design were crafted to meet the challenge of Infinispan’s grueling integration tests.
jclouds-s3 is also quite user-friendly, exposing services to S3 in a simple Map interface.
As we are now in beta, please do try out jclouds-s3 and let us know where we can improve. If you have some spare cycles, feel free to lend a hand :)
Regardless, we hope you enjoy the product.
Tags: jclouds s3
Saturday, 02 May 2009
Keep it in the cloud
Corporate slaves often spend months of paper work only to find their machine obsolete before its powered on. Forward thinking individuals need playgrounds to try out new ideas. Enterprise 2.0 projects have to scale with their user base. In short, there’s a lot of demand for flexible infrastructure. Cloud infrastructure is one way to fill that order.
One popular cloud infrastructure provider is Amazon EC2. EC2 is basically a pay-as-you-go datacenter. You pay for CPU, storage, and network resources. Using the open-source Infinispan data grid, you have a good chance of linear performance as your application needs change. Using EC2, you can instantly bring on hosts to support that need. Great match, right? What’s next?
Assuming your data is important, you will need to persist your Infinispan cluster somewhere. That said, Amazon charges you for traffic that goes in and out of their network… this could get expensive. So, the next bit is controlling these costs.
Amazon offers a storage service called S3. Transferring data between EC2 and S3 is free; you only pay for data parking. In short, there is a way to control these I/O costs: S3.
Infinispan will save your cluster to S3 when configured with its high-performance JClouds plug-in. You specify the S3 Bucket and your AWS credentials and Infinispan does the rest.
In summary, not only does Infinispan shred your license costs, but we also help cut your persistence costs, too!
So, go ahead: Keep it in the cloud!
Tags: data grids jclouds ec2 s3 aws