1. Infinispan Operator
Infinispan Operator provides operational intelligence and reduces management complexity for deploying Infinispan on Kubernetes and Red Hat OpenShift.
1.1. Supported versions
Since version 2.3.0 Infinispan Operator supports multiple Infinispan Server versions. You can upgrade the version of your cluster between supported Infinispan versions:
| Infinispan Operator version | Infinispan Server versions |
|---|---|
2.5.12 |
|
Older versions
| Infinispan Operator version | Infinispan Server versions |
|---|---|
2.5.11 |
|
2.5.10 |
|
2.5.9 |
|
2.5.8 |
|
2.5.7 |
|
2.5.6 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 16.0.1 16.0.2 16.0.3 16.0.4 16.0.5 16.0.7 16.0.8 16.0.9 16.1.1 16.1.2 16.1.3 |
2.5.5 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 16.0.1 16.0.2 16.0.3 16.0.4 16.0.5 16.0.7 16.0.8 16.1.1 16.1.2 |
2.5.4 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 16.0.1 16.0.2 16.0.3 16.0.4 16.0.5 16.0.7 16.0.8 16.1.1 |
2.5.3 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 16.0.1 16.0.2 16.0.3 16.0.4 16.0.5 16.0.7 16.0.8 |
2.5.2 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 16.0.1 16.0.2 16.0.3 16.0.4 16.0.5 16.0.7 |
2.5.1 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 16.0.1 16.0.2 16.0.3 16.0.4 16.0.5 |
2.5.0 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 16.0.1 |
2.4.18 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 |
2.4.17 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.0.20 15.0.21 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 15.2.6 |
2.4.16 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.0.19 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 |
2.4.15 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.0.18 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 15.2.5 |
2.4.14 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.0.16 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 15.2.4 |
2.4.13 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.0.15 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 15.2.2 |
2.4.12 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 15.2.1 |
2.4.11 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.0.14 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 15.1.7 |
2.4.10 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.0.13 15.1.0 15.1.1 15.1.3 15.1.4 15.1.5 |
2.4.9 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.1.0 15.1.1 15.1.3 |
2.4.8 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.1.0 15.1.1 |
2.4.7 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 15.1.0 |
2.4.6 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 15.0.11 |
2.4.5 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.5 15.0.8 15.0.10 |
2.4.4 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 14.0.32 15.0.0 15.0.3 15.0.4 15.0.8 |
2.4.3 |
14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 15.0.0 15.0.3 15.0.4 15.0.5 |
2.4.2 |
13.0.10 14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 15.0.0 15.0.3 15.0.4 |
2.4.1 |
13.0.10 14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 = 15.0.0 |
2.4.0 |
13.0.10 14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 15.0.0 |
2.3.7 |
13.0.10 14.0.1 14.0.6 14.0.9 14.0.13 14.0.17 14.0.19 14.0.20 14.0.21 14.0.24 14.0.27 |
|
Operand versions |
1.2. Infinispan Operator deployments
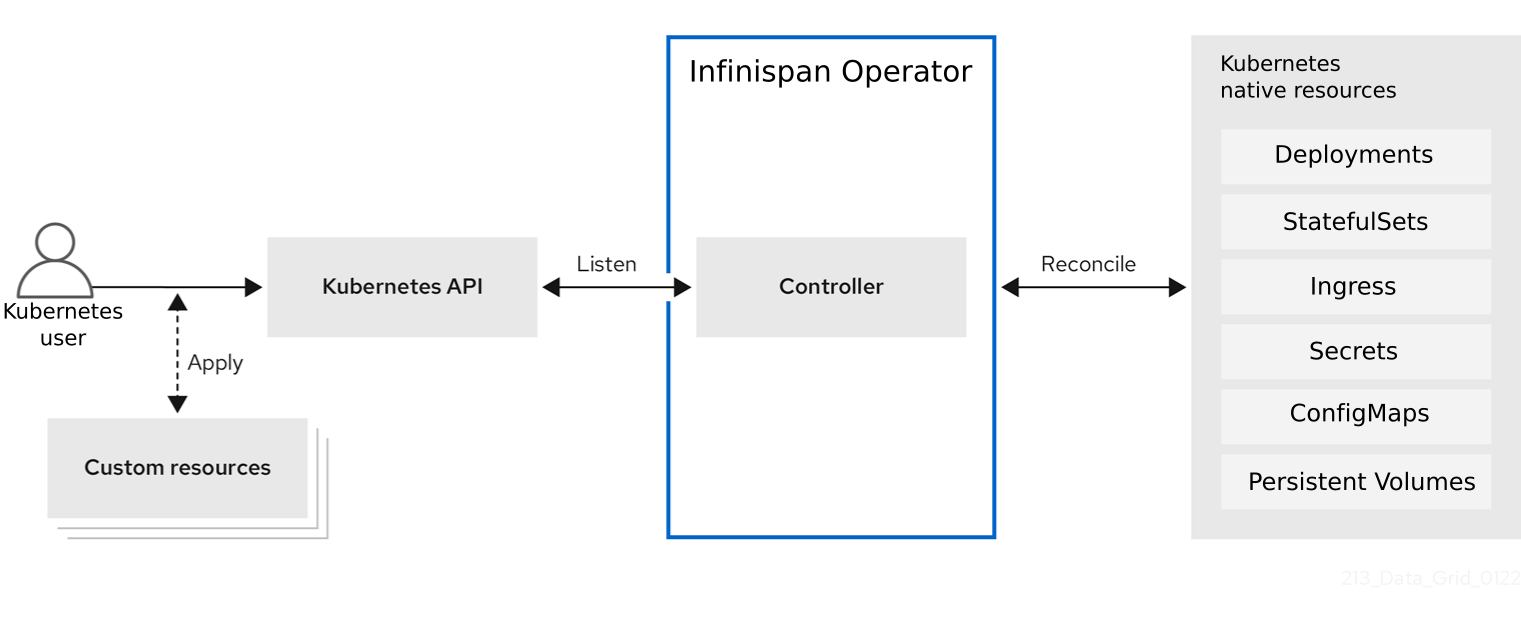
When you install Infinispan Operator, it extends the Kubernetes API with Custom Resource Definitions (CRDs) for deploying and managing Infinispan clusters on Red Hat OpenShift.
To interact with Infinispan Operator, Kubernetes users apply Custom Resources (CRs) through the Kubernetes Dashboard or kubectl client.
Infinispan Operator listens for Infinispan CRs and automatically provisions native resources, such as StatefulSets and Secrets, that your Infinispan deployment requires.
Infinispan Operator also configures Infinispan services according to the specifications in Infinispan CRs, including the number of pods for the cluster and backup locations for cross-site replication.
1.3. Cluster management
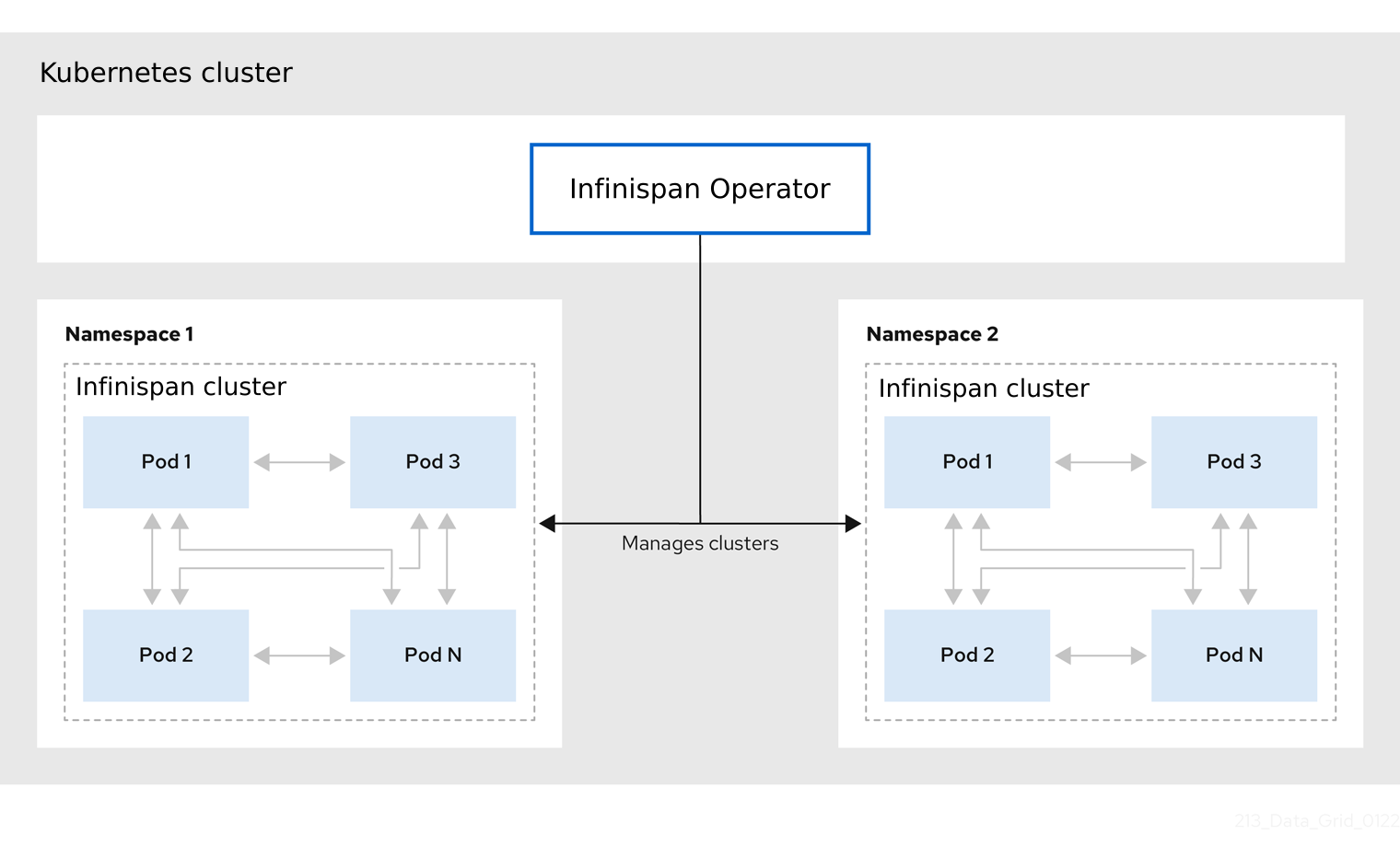
A single Infinispan Operator installation can manage multiple clusters with different Infinispan versions in separate namespaces. Each time a user applies CRs to modify the deployment, Infinispan Operator applies the changes globally to all Infinispan clusters.
1.4. Resource reconciliation
Infinispan Operator reconciles custom resources such as the Cache CR with resources on your Infinispan cluster.
Bidirectional reconciliation synchronizes your CRs with changes that you make to Infinispan resources through the Infinispan Console, command line interface (CLI), or other client application and vice versa. For example if you create a cache through the Infinispan Console then Infinispan Operator adds a declarative Kubernetes representation.
To perform reconciliation Infinispan Operator creates a listener pod for each Infinispan cluster that detects modifications for Infinispan resources.
-
When you create a cache through the Infinispan Console, CLI, or other client application, Infinispan Operator creates a corresponding
CacheCR with a unique name that conforms to the Kubernetes naming policy. -
Declarative Kubernetes representations of Infinispan resources that Infinispan Operator creates with the
listenerpod are linked toInfinispanCRs.
DeletingInfinispanCRs removes any associated resource declarations.
2. Installing the native Infinispan CLI as a client plugin
Infinispan provides a command line interface (CLI) compiled to a native executable that you can install as a plugin for kubectl clients.
You can then use your kubectl client to:
-
Create Infinispan Operator subscriptions and remove Infinispan Operator installations.
-
Set up Infinispan clusters and configure services.
-
Work with Infinispan resources via remote shells.
2.1. Installing the native Infinispan CLI plugin
Install the native Infinispan Command Line Interface (CLI) as a plugin for kubectl clients.
-
Have a
kubectlorocclient. -
Download the native Infinispan CLI distribution from infinispan-quarkus releases.
-
Extract the
.ziparchive for the native Infinispan CLI distribution. -
Copy the native executable, or create a hard link, to a file named "kubectl-infinispan", for example:
cp infinispan-cli kubectl-infinispan -
Add
kubectl-infinispanto yourPATH. -
Verify that the CLI is installed.
kubectl plugin list The following compatible plugins are available: /path/to/kubectl-infinispan -
Use the
infinispan --helpcommand to view available commands.kubectl infinispan --help
2.2. kubectl-infinispan command reference
This topic provides some details about the kubectl-infinispan plugin for clients.
|
Use the For example, |
Command |
Description |
|
Creates Infinispan Operator subscriptions and installs into the global namespace by default. |
|
Creates Infinispan clusters. |
|
Displays running Infinispan clusters. |
|
Starts an interactive remote shell session on a Infinispan cluster. |
|
Removes Infinispan clusters. |
|
Removes Infinispan Operator installations and all managed resources. |
3. Installing Infinispan Operator
Install Infinispan Operator into a Kubernetes namespace to create and manage Infinispan clusters.
|
Because Custom Resource Definitions (CRDs) are deployed cluster-wide, you cannot run multiple versions of the Infinispan Operator on the same cluster. To avoid issues, deploy the Operator cluster-wide and use the |
3.1. Installing Infinispan Operator on Red Hat OpenShift
Create subscriptions to Infinispan Operator on OpenShift so you can install different Infinispan versions and receive automatic updates.
Automatic updates apply to Infinispan Operator first and then for each Infinispan node. Infinispan Operator updates clusters one node at a time, gracefully shutting down each node and then bringing it back online with the updated version before going on to the next node.
-
Access to OperatorHub running on OpenShift. Some OpenShift environments, such as OpenShift Container Platform, can require administrator credentials.
-
Ensure the Operator Lifecycle Manager (OLM) is installed.
-
Have an OpenShift project for Infinispan Operator if you plan to install it into a specific namespace.
-
Log in to the Kubernetes Dashboard.
-
Navigate to OperatorHub.
-
Find and select Infinispan Operator.
-
Select Install and continue to Create Operator Subscription.
-
Specify options for your subscription.
- Installation Mode
-
You can install Infinispan Operator into a Specific namespace or All namespaces.
- Update Channel
-
Subscribe to updates for Infinispan Operator versions.
- Approval Strategies
-
When new Infinispan versions become available, you can install updates manually or let Infinispan Operator install them automatically.
-
Select Subscribe to install Infinispan Operator.
-
Navigate to Installed Operators to verify the Infinispan Operator installation.
3.2. Installing Infinispan Operator with the native CLI plugin
Install Infinispan Operator with the native Infinispan CLI plugin, kubectl-infinispan.
-
Have
kubectl-infinispanon yourPATH. -
Ensure the Operator Lifecycle Manager (OLM) is installed.
-
Run the
oc infinispan installcommand to create Infinispan Operator subscriptions, for example:kubectl infinispan install --channel=stable --source=redhat-operators --source-namespace=openshift-marketplace -
Verify the installation.
kubectl get pods -n openshift-operators | grep infinispan-operator NAME READY STATUS infinispan-operator-<id> 1/1 Running
|
Use |
3.3. Installing Infinispan Operator from OperatorHub.io
Use the command line to install Infinispan Operator from OperatorHub.io.
-
OKD 3.11 or later.
-
Kubernetes 1.11 or later.
-
Ensure the Operator Lifecycle Manager (OLM) is installed.
-
Have administrator access on the Kubernetes cluster.
-
Have a
kubectlorocclient.
-
Navigate to the Infinispan Operator entry on OperatorHub.io.
-
Follow the instructions to install Infinispan Operator into your Kubernetes cluster.
3.4. Building and installing Infinispan Operator manually
Manually build and install Infinispan Operator from the GitHub repository.
-
Follow the appropriate instructions in the Infinispan Operator README.
4. Configuring Infinispan Operator
4.1. Configure Operator logging
Configure the Infinispan Operator to output logs in JSON format for improved machine processing and log aggregation. You can also adjust the logging level to increase verbosity for debugging reconciliation issues.
INFINISPAN_OPERATOR_LOG_FORMATvariable-
Specifies the output format.
-
console(default): Human-readable text. -
json: Structured JSON format for log aggregators.
-
INFINISPAN_OPERATOR_LOG_LEVELvariable-
Sets the verbosity of logs.
-
Valid values are
debug,info(default),warn, orerror.
-
|
In production environments, it is highly recommended to set |
-
Open your Infinispan Operator Subscription for editing
-
Add the logging environment variables under the spec.config.env field:
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: infinispan namespace: operators spec: channel: stable installPlanApproval: Automatic name: infinispan source: operatorhubio-catalog sourceNamespace: olm config: env: - name: INFINISPAN_OPERATOR_LOG_FORMAT value: json - name: INFINISPAN_OPERATOR_LOG_LEVEL value: warn -
Apply the changes.OLM will automatically restart the Operator pod to apply the new configuration.
-
Retrieve logs from Operator pod as required.
kubectl logs -f deployment/infinispan-operator-controller-manager
Logging format comparison
2026-04-14T09:28:48.546Z INFO controllers.Infinispan Triggering StatefulSet Rolling upgrade {"infinispan": "infinispan/infinispan"}{"level":"info","ts":"2026-04-14T09:33:53.960Z","logger":"controllers.Infinispan","msg":"Triggering StatefulSet Rolling upgrade","infinispan":"infinispan/infinispan"}5. Creating Infinispan clusters
Create Infinispan clusters running on Kubernetes with the Infinispan CR or with the native Infinispan CLI plugin for kubectl clients.
5.1. Infinispan custom resource (CR)
Infinispan Operator adds a new Custom Resource (CR) of type Infinispan that lets you handle Infinispan clusters as complex units on Kubernetes.
Infinispan Operator listens for Infinispan Custom Resources (CR) that you use to instantiate and configure Infinispan clusters and manage Kubernetes resources, such as StatefulSets and Services.
Infinispan CRapiVersion: infinispan.org/v1
kind: Infinispan
metadata:
name: infinispan
spec:
replicas: 2
version: <Infinispan_version>
service:
type: DataGrid| Field | Description |
|---|---|
|
Declares the version of the |
|
Declares the |
|
Specifies a name for your Infinispan cluster. |
|
Specifies the number of pods in your Infinispan cluster. |
|
Specifies the type of Infinispan service to create. |
|
Specifies the Infinispan Server version of your cluster. |
5.2. Creating Infinispan clusters
Create Infinispan clusters with the native CLI plugin, kubectl-infinispan.
-
Install Infinispan Operator.
-
Have
kubectl-infinispanon yourPATH.
-
Run the
infinispan create clustercommand.For example, create a Infinispan cluster with two pods as follows:
kubectl infinispan create cluster --replicas=3 -Pservice.type=DataGrid infinispanAdd the
--versionargument to control the Infinispan version of your cluster. For example,--version=16.2.1. If you don’t specify the version, Infinispan Operator creates cluster with the latest supported Infinispan version. -
Watch Infinispan Operator create the Infinispan pods.
kubectl get pods -w
After you create a Infinispan cluster, use the kubectl to apply changes to Infinispan CR and configure your Infinispan service.
You can also delete Infinispan clusters with kubectl-infinispan and re-create them as required.
kubectl infinispan delete cluster infinispan5.3. Verifying Infinispan cluster views
Confirm that Infinispan pods have successfully formed clusters.
-
Create at least one Infinispan cluster.
-
Retrieve the
InfinispanCR for Infinispan Operator.kubectl get infinispan -o yamlThe response indicates that Infinispan pods have received clustered views, as in the following example:
conditions: - message: 'View: [infinispan-0, infinispan-1]' status: "True" type: wellFormed
|
Do the following for automated scripts: |
Retrieving cluster view from logs
You can also get the cluster view from Infinispan logs as follows:
kubectl logs infinispan-0 | grep ISPN000094INFO [org.infinispan.CLUSTER] (MSC service thread 1-2) \
ISPN000094: Received new cluster view for channel infinispan: \
[infinispan-0|0] (1) [infinispan-0]
INFO [org.infinispan.CLUSTER] (jgroups-3,infinispan-0) \
ISPN000094: Received new cluster view for channel infinispan: \
[infinispan-0|1] (2) [infinispan-0, infinispan-1]5.4. Modifying Infinispan clusters
Configure Infinispan clusters by providing Infinispan Operator with a custom Infinispan CR.
-
Install Infinispan Operator.
-
Create at least one Infinispan cluster.
-
Have an
ocor akubectlclient.
-
Create a YAML file that defines your
InfinispanCR.For example, create a
my_infinispan.yamlfile that changes the number of Infinispan pods to two:cat > cr_minimal.yaml<<EOF apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 2 version: <Infinispan_version> service: type: DataGrid EOF -
Apply your
InfinispanCR.kubectl apply -f my_infinispan.yaml -
Watch Infinispan Operator scale the Infinispan pods.
kubectl get pods -w
5.5. Stopping and starting Infinispan clusters
Stop and start Infinispan pods in a graceful, ordered fashion to correctly preserve cluster state.
Clusters of Data Grid Service pods must restart with the same number of pods that existed before shutdown. This allows Infinispan to restore the distribution of data across the cluster. After Infinispan Operator fully restarts the cluster you can safely add and remove pods.
-
Change the
spec.replicasfield to0to stop the Infinispan cluster.spec: replicas: 0 -
Ensure you have the correct number of pods before you restart the cluster.
kubectl get infinispan infinispan -o=jsonpath='{.status.replicasWantedAtRestart}' -
Change the
spec.replicasfield to the same number of pods to restart the Infinispan cluster.spec: replicas: 6
6. Configuring Infinispan clusters
Apply custom Infinispan configuration to clusters that Infinispan Operator manages.
6.1. Applying custom configuration to Infinispan clusters
Add Infinispan configuration to a ConfigMap and make it available to Infinispan Operator.
Infinispan Operator can then apply the custom configuration to your Infinispan cluster.
|
Infinispan Operator applies default configuration on top of your custom configuration to ensure it can continue to manage your Infinispan clusters. Be careful when applying custom configuration outside the |
|
Use the Infinispan Helm chart to deploy clusters of fully configurable Infinispan Server instances on OpenShift. |
-
Have valid Infinispan configuration in XML, YAML, or JSON format.
-
Add Infinispan configuration to a
infinispan-config.[xml|yaml|json]key in thedatafield of yourConfigMap.XMLapiVersion: v1 kind: ConfigMap metadata: name: cluster-config namespace: ispn-namespace data: infinispan-config.xml: > <infinispan> <!-- Custom configuration goes here. --> </infinispan>YAMLapiVersion: v1 kind: ConfigMap metadata: name: cluster-config namespace: ispn-namespace data: infinispan-config.yaml: > infinispan: # Custom configuration goes here.JSONapiVersion: v1 kind: ConfigMap metadata: name: cluster-config namespace: ispn-namespace data: infinispan-config.json: > { "infinispan": { } } -
Create the
ConfigMapfrom your YAML file.kubectl apply -f cluster-config.yaml -
Specify the name of the
ConfigMapwith thespec.configMapNamefield in yourInfinispanCR and then apply the changes.spec: configMapName: "cluster-config"
If your cluster is already running Infinispan Operator restarts it to apply the configuration.
Each time you modify the Infinispan configuration in the ConfigMap, Infinispan Operator detects the updates and restarts the cluster to apply the changes.
6.2. Custom Infinispan configuration
You can add Infinispan configuration to a ConfigMap in XML, YAML, or JSON format.
6.2.1. Cache template
<infinispan>
<cache-container>
<distributed-cache-configuration name="base-template">
<expiration lifespan="5000"/>
</distributed-cache-configuration>
<distributed-cache-configuration name="extended-template"
configuration="base-template">
<encoding media-type="application/x-protostream"/>
<expiration lifespan="10000"
max-idle="1000"/>
</distributed-cache-configuration>
</cache-container>
</infinispan>infinispan:
cacheContainer:
caches:
base-template:
distributedCacheConfiguration:
expiration:
lifespan: "5000"
extended-template:
distributedCacheConfiguration:
configuration: "base-template"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "10000"
maxIdle: "1000"{
"infinispan" : {
"cache-container" : {
"caches" : {
"base-template" : {
"distributed-cache-configuration" : {
"expiration" : {
"lifespan" : "5000"
}
}
},
"extended-template" : {
"distributed-cache-configuration" : {
"configuration" : "base-template",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "10000",
"max-idle" : "1000"
}
}
}
}
}
}
}6.2.2. Logging configuration
You can also include Apache Log4j configuration in XML format as part of your ConfigMap.
|
Use the |
apiVersion: v1
kind: ConfigMap
metadata:
name: logging-config
namespace: ispn-namespace
data:
infinispan-config.xml: >
<infinispan>
<!-- Add custom Infinispan configuration if required. -->
<!-- You can provide either Infinispan configuration, logging configuration, or both. -->
</infinispan>
log4j.xml: >
<?xml version="1.0" encoding="UTF-8"?>
<Configuration name="ServerConfig" monitorInterval="60" shutdownHook="disable">
<Appenders>
<!-- Colored output on the console -->
<Console name="STDOUT">
<PatternLayout pattern="%d{HH:mm:ss,SSS} %-5p (%t) [%c] %m%throwable%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="STDOUT" level="TRACE"/>
</Root>
<Logger name="org.infinispan" level="TRACE"/>
</Loggers>
</Configuration>6.3. Securing custom Infinispan configuration
Securely define and store custom Infinispan Server configuration. To protect sensitive text strings such as passwords, add the entries in a credential store rather than directly in the Infinispan Server configuration.
-
Have a valid Infinispan configuration in XML, YAML, or JSON format.
-
Create a
CredentialStore Secretfile. -
Use the
datafield to specify the credentials and its aliases.user-secret.yamlapiVersion: v1 kind: Secret metadata: name: user-secret type: Opaque data: postgres_cred: sensitive-value mysql_cred: sensitive-value2 -
Apply your Secret file.
kubectl apply -f user-secret.yaml -
Open the
InfinispanCR for editing. -
In the
spec.security.credentialStoreSecretNamefield, specify the name of the credential store secret.Infinispan CRspec: security: credentialStoreSecretName: user-secret -
Apply the changes.
-
Open your Infinispan Server configuration for editing.
-
Add a
credential-referenceto your configuration where required.-
Specify the
credentialsas the name of thestore. -
Specify the
aliasattribute as one of the keys defined in your credential secret.Infinispan.xml<data-source name="postgres" jndi-name="jdbc/postgres"> <connection-factory driver="org.postgresql.Driver" username="dbuser" url="${org.infinispan.server.test.postgres.jdbcUrl}"> <!-- Credential 'postgres_cred' defined in the 'user-secret' Secret is used here as the database password --> <credential-reference store="credentials" alias="postgres_cred"/> </connection-factory> <connection-pool /> </data-source>
-
7. Upgrading Infinispan clusters
Infinispan Operator lets you upgrade Infinispan clusters from one version to another without downtime or data loss.
|
Infinispan Operator requires the Operator Lifecycle Manager to perform cluster upgrades. |
7.1. Infinispan cluster upgrades
The spec.upgrades.type field controls how Infinispan Operator upgrades your Infinispan cluster when new versions become available.
There are three types of cluster upgrade:
Shutdown-
Upgrades Infinispan clusters, with service downtime, by bringing down the original cluster and bringing up a new one in its place. This is the default upgrade type.
InPlaceRolling-
Upgrades Infinispan cluster pods to new patch releases individually, using a StatefulSet RollingUpdate.
HotRodRolling-
Upgrades Infinispan versions, without service downtime, by deploying a new cluster in parallel to the original and transitioning all traffic to it.
The Operator does not automatically upgrade clusters to a new Infinispan server version. In order to trigger an upgrade, you must explicitly change the
spec.versionelement to a new version.
Shutdown upgrades
To perform a shutdown upgrade, Infinispan Operator does the following:
-
Gracefully shuts down the existing cluster.
-
Removes the existing cluster.
-
Creates a new cluster with the target version.
InPlaceRolling upgrades
To perform a rolling upgrade, Infinispan Operator does the following:
-
Checks if the Infinispan version supports rolling upgrades.
-
Checks whether the current version and target version have matching major and minor versions.
-
If the conditions above are met, the Operator will upgrade server pods one by one using a StatefulSet RollingUpdate.
| === When upgrading between different major or minor versions of the server, the "Shutdown" or "HotRodRolling" upgrade type is required. This must be configured in the CR spec at the the same time as the new version. === |
HotRodRolling upgrades
To perform a Hot Rod rolling upgrade, Infinispan Operator does the following:
-
Creates a new Infinispan cluster with the target version that runs alongside your existing cluster.
-
Creates a remote cache store to transfer data from the existing cluster to the new cluster.
-
Redirects all clients to the new cluster.
-
Removes the existing cluster when all data and client connections are transferred to the new cluster.
|
You should not perform Hot Rod rolling upgrades with caches that enable passivation with persistent cache stores. In the event that the upgrade does not complete successfully, passivation can result in data loss when Infinispan Operator rolls back the target cluster. If your cache configuration enables passivation you should perform a shutdown upgrade. |
7.2. Upgrading Infinispan clusters with downtime
Upgrading Infinispan clusters with downtime results in service disruption but does not require any additional capacity.
-
If required, configure a persistent cache store to preserve your data during the upgrade.
At the start of the upgrade process Infinispan Operator shuts down your existing cluster. This results in data loss if you do not configure a persistent cache store.
-
Specify the Infinispan version number in the
spec.versionfield. -
Ensure that
Shutdownis set as the value for thespec.upgrades.typefield, which is the default.spec: version: 16.2.1 upgrades: type: Shutdown -
Apply your changes, if necessary.
7.3. Upgrading Infinispan clusters using InPlace rolling strategy
Upgrading Infinispan clusters using InPlace rolling strategy with no service downtime.
-
Upgrading to a new Infinispan server patch release
-
Specify the Infinispan version number in the
spec.versionfield. -
Ensure that
InPlaceRollingis set as the value for thespec.upgrades.typefield.spec: version: 16.2.1 upgrades: type: InPlaceRolling -
Apply your changes, if necessary.
7.4. Performing Hot Rod rolling upgrades for Infinispan clusters
Performing Hot Rod rolling upgrades lets you move to a new Infinispan version without service disruption. However, this upgrade type requires additional capacity and temporarily results in two Infinispan clusters with different versions running concurrently.
-
The Infinispan Operator version you have installed supports the Infinispan target version.
-
Specify the Infinispan version number in the
spec.versionfield. -
Specify
HotRodRollingas the value for thespec.upgrades.typefield.spec: version: 16.2.1 upgrades: type: HotRodRolling -
Apply your changes.
7.4.1. Recovering from a failed Hot Rod rolling upgrade
You can roll back a failed Hot Rod rolling upgrade to the previous version if the original cluster is still present.
-
Hot Rod rolling upgrade is in progress and the initial Infinispan cluster is present.
-
Ensure the Hot Rod rolling upgrade is in progress.
kubectl get infinispan <cr_name> -o yamlThe
status.hotRodRollingUpgradeStatusfield must be present. -
Update
spec.versionfield of yourInfinispan CRto the original cluster version defined in thestatus.hotRodRollingUpgradeStatus.Infinispan Operator deletes the newly created cluster.
8. Setting up Infinispan services
Use Infinispan Operator to create clusters of Data Grid Service pods.
8.1. Service types
Services are stateful applications, based on the Infinispan Server image, that provide flexible and robust in-memory data storage.
Infinispan operator supports only DataGrid service type which deploys Infinispan clusters with full configuration and capabilities. Cache service type is no longer supported.
DataGrid` service type for clusters lets you:
-
Back up data across global clusters with cross-site replication.
-
Create caches with any valid configuration.
-
Add file-based cache stores to save data in a persistent volume.
-
Query values across caches using the Infinispan Query API.
-
Use advanced Infinispan features and capabilities.
8.2. Creating Data Grid Service pods
To use custom cache definitions along with Infinispan capabilities such as cross-site replication, create clusters of Data Grid Service pods.
-
Create an
InfinispanCR that setsspec.service.type: DataGridand configures any other Data Grid Service resources.apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 2 version: <Infinispan_version> service: type: DataGridYou cannot change the
spec.service.typefield after you create pods. To change the service type, you must delete the existing pods and create new ones. -
Apply your
InfinispanCR to create the cluster.
8.2.1. Data Grid Service CR
This topic describes the Infinispan CR for Data Grid Service pods.
apiVersion: infinispan.org/v1
kind: Infinispan
metadata:
name: infinispan
annotations:
infinispan.org/monitoring: 'true'
spec:
replicas: 6
version: 16.2.1
upgrades:
type: Shutdown
service:
type: DataGrid
container:
storage: 2Gi
# The ephemeralStorage and storageClassName fields are mutually exclusive.
ephemeralStorage: false
storageClassName: my-storage-class
sites:
local:
name: azure
expose:
type: LoadBalancer
locations:
- name: azure
url: openshift://api.azure.host:6443
secretName: azure-token
- name: aws
clusterName: infinispan
namespace: ispn-namespace
url: openshift://api.aws.host:6443
secretName: aws-token
security:
endpointSecretName: endpoint-identities
endpointEncryption:
type: Secret
certSecretName: tls-secret
container:
extraJvmOpts: "-XX:NativeMemoryTracking=summary"
cpu: "2000m:1000m"
memory: "2Gi:1Gi"
logging:
categories:
org.infinispan: debug
org.jgroups: debug
org.jgroups.protocols.TCP: error
org.jgroups.protocols.relay.RELAY2: error
expose:
type: LoadBalancer
configMapName: "my-cluster-config"
configListener:
enabled: true
scheduling:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app: infinispan-pod
clusterName: infinispan
infinispan_cr: infinispan
topologyKey: "kubernetes.io/hostname"| Field | Description |
|---|---|
|
Names your Infinispan cluster. |
|
Automatically creates a |
|
Specifies the number of pods in your cluster. |
|
Specifies the Infinispan Server version of your cluster. |
|
Controls how Infinispan Operator upgrades your Infinispan cluster when new versions become available. |
|
Configures the type Infinispan service. A value of |
|
Configures the storage resources for Data Grid Service pods. |
|
Configures cross-site replication. |
|
Specifies an authentication secret that contains Infinispan user credentials. |
|
Specifies TLS certificates and keystores to encrypt client connections. |
|
Specifies JVM, CPU, and memory resources for Infinispan pods. |
|
Configures Infinispan logging categories. |
|
Controls how Infinispan endpoints are exposed on the network. |
|
Specifies a |
|
Creates a The |
|
Configures the logging level for the |
|
Configures anti-affinity strategies that guarantee Infinispan availability. |
8.3. Allocating storage resources
By default, Infinispan Operator allocates 1Gi for the persistent volume claim.
However you should adjust the amount of storage available to Data Grid Service pods so that Infinispan can preserve cluster state during shutdown.
|
If available container storage is less than the amount of available memory, data loss can occur. |
-
Allocate storage resources with the
spec.service.container.storagefield. -
Configure either the
ephemeralStoragefield or thestorageClassNamefield as required.These fields are mutually exclusive. Add only one of them to your
InfinispanCR. -
Apply the changes.
spec:
service:
type: DataGrid
container:
storage: 2Gi
ephemeralStorage: trueStorageClass objectspec:
service:
type: DataGrid
container:
storage: 2Gi
storageClassName: my-storage-class| Field | Description |
|---|---|
|
Specifies the amount of storage for Data Grid Service pods. |
|
Defines whether storage is ephemeral or permanent. Set the value to |
|
Specifies the name of a |
8.3.1. Persistent volume claims
Infinispan Operator creates a persistent volume claim (PVC) and mounts container storage at:
/opt/infinispan/server/data
When you create caches, Infinispan permanently stores their configuration so your caches are available after cluster restarts.
Use a file-based cache store, by adding the <file-store/> element to your Infinispan cache configuration, if you want Data Grid Service pods to persist data during cluster shutdown.
8.4. Allocating CPU and memory
Allocate CPU and memory resources to Infinispan pods with the Infinispan CR.
|
Infinispan Operator requests 1Gi of memory from the Kubernetes scheduler when creating Infinispan pods. CPU requests are unbounded by default. |
-
Allocate the number of CPU units with the
spec.container.cpufield. -
Allocate the amount of memory, in bytes, with the
spec.container.memoryfield.The
cpuandmemoryfields have values in the format of<limit>:<requests>. For example,cpu: "2000m:1000m"limits pods to a maximum of2000mof CPU and requests1000mof CPU for each pod at startup. Specifying a single value sets both the limit and request. -
Apply your
InfinispanCR.If your cluster is running, Infinispan Operator restarts the Infinispan pods so changes take effect.
spec:
container:
cpu: "2000m:1000m"
memory: "2Gi:1Gi"8.5. Setting JVM options
Pass additional JVM options to Infinispan pods at startup.
-
Configure JVM options with the
spec.containerfiled in yourInfinispanCR. -
Apply your
InfinispanCR.If your cluster is running, Infinispan Operator restarts the Infinispan pods so changes take effect.
spec:
container:
extraJvmOpts: "-<option>=<value>"
routerExtraJvmOpts: "-<option>=<value>"
cliExtraJvmOpts: "-<option>=<value>"| Field | Description |
|---|---|
|
Specifies additional JVM options for the Infinispan Server. |
|
Specifies additional JVM options for the Gossip router. |
|
Specifies additional JVM options for the Infinispan CLI. |
8.6. Configuring pod probes
Optionally configure the values of the Liveness, Readiness and Startup probes used by Infinispan pods.
The Infinispan Operator automatically configures the probe values to sensible defaults. We only recommend providing your own values once you have determined that the default values do not match your requirements.
-
Configure probe values using the
spec.service.container.*Probefields:spec: service: container: readinessProbe: failureThreshold: 1 initialDelaySeconds: 1 periodSeconds: 1 successThreshold: 1 timeoutSeconds: 1 livenessProbe: failureThreshold: 1 initialDelaySeconds: 1 periodSeconds: 1 successThreshold: 1 timeoutSeconds: 1 startupProbe: failureThreshold: 1 initialDelaySeconds: 1 periodSeconds: 1 successThreshold: 1 timeoutSeconds: 1If no value is specified for a given probe value, then the Infinispan Operator default is used.
-
Apply your
InfinispanCR.If your cluster is running, Infinispan Operator restarts the Infinispan pods in order for the changes to take effect.
8.7. Configuring pod priority
Create one or more priority classes to indicate the importance of a pod relative to other pods. Pods with higher priority are scheduled ahead of pods with lower priority, ensuring prioritization of pods running critical workloads, especially when resources become constrained.
-
Have
cluster-adminaccess to Kubernetes.
-
Define a
PriorityClassobject by specifying its name and value.high-priority.yamlapiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000 globalDefault: false description: "Use this priority class for high priority service pods only." -
Create the priority class.
kubectl create -f high-priority.yaml -
Reference the priority class name in the pod configuration.
Infinispan CRkind: Infinispan ... spec: scheduling: affinity: ... priorityClassName: "high-priority" ...You must reference an existing priority class name, otherwise the pod is rejected.
-
Apply the changes.
8.8. Configuring pod termination grace period
Optionally configure the TerminationGracePeriodSeconds of the Infinispan pods.
The Infinispan Operator relies on the Kubernetes default TerminationGracePeriodSeconds unless a value is explicitly provided.
We only recommend providing your own value once you have determined that the default value do not match your requirements.
-
Configure probe values using the
spec.service.container.terminationGracePeriodSecondsfield:spec: service: container: terminationGracePeriodSeconds: 60 -
Apply your
InfinispanCR.If your cluster is running, Infinispan Operator restarts the Infinispan pods in order for the changes to take effect.
8.9. Adjusting log pattern
To customize the log display for Infinispan log traces, update the log pattern.
If no custom pattern is set, the default format is:
%d{HH:mm:ss,SSS} %-5p (%t) [%c] %m%throwable%n
-
Configure Infinispan logging with the
spec.logging.patternfield in yourInfinispanCR.spec: logging: pattern: %X{address} %X{user} [%d{dd/MMM/yyyy:HH:mm:ss Z}] -
Apply the changes.
-
Retrieve logs from Infinispan pods as required.
kubectl logs -f $POD_NAME
8.10. Adjusting log levels
Change levels for different Infinispan logging categories when you need to debug issues. You can also adjust log levels to reduce the number of messages for certain categories to minimize the use of container resources.
-
Configure Infinispan logging with the
spec.logging.categoriesfield in yourInfinispanCR.spec: logging: categories: org.infinispan: debug org.jgroups: debug -
Apply the changes.
-
Retrieve logs from Infinispan pods as required.
kubectl logs -f $POD_NAME
8.10.1. Logging reference
Find information about log categories and levels.
| Root category | Description | Default level |
|---|---|---|
|
Infinispan messages |
|
|
Cluster transport messages |
|
| Log level | Description |
|---|---|
|
Provides detailed information about running state of applications. This is the most verbose log level. |
|
Indicates the progress of individual requests or activities. |
|
Indicates overall progress of applications, including lifecycle events. |
|
Indicates circumstances that can lead to error or degrade performance. |
|
Indicates error conditions that might prevent operations or activities from being successful but do not prevent applications from running. |
Infinispan Operator does not log GC messages by default.
You can direct GC messages to stdout with the following JVM options:
extraJvmOpts: "-Xlog:gc*:stdout:time,level,tags"8.11. Specifying Infinispan Server images
Specify which Infinispan Server image Infinispan Operator should use to create pods with the spec.image field.
spec:
image: quay.io/infinispan/server:latest
===
When using custom image, specify spec.version of the server within the image as well. Different declared and deployed versions may result in unpredictable behavior.
===
|
8.12. Adding labels and annotations to Infinispan resources
Attach key/value labels and annotations to pods and services that Infinispan Operator creates and manages. Labels help you identify relationships between objects to better organize and monitor Infinispan resources. Annotations are arbitrary non-identifying metadata for client applications or deployment and management tooling.
-
Open your
InfinispanCR for editing. -
Attach labels and annotations to Infinispan resources in the
metadata.annotationssection.-
Define values for annotations directly in the
metadata.annotationssection. -
Define values for labels with the
metadata.labelsfield.
-
-
Apply your
InfinispanCR.
apiVersion: infinispan.org/v1
kind: Infinispan
metadata:
annotations:
infinispan.org/targetAnnotations: service-annotation1, service-annotation2
infinispan.org/podTargetAnnotations: pod-annotation1, pod-annotation2
infinispan.org/routerAnnotations: router-annotation1, router-annotation2
service-annotation1: value
service-annotation2: value
pod-annotation1: value
pod-annotation2: value
router-annotation1: value
router-annotation2: valueapiVersion: infinispan.org/v1
kind: Infinispan
metadata:
annotations:
infinispan.org/targetLabels: service-label1, service-label2
infinispan.org/podTargetLabels: pod-label1, pod-label2
labels:
service-label1: value
service-label2: value
pod-label1: value
pod-label2: value
# The operator does not attach these labels to resources.
my-label: my-value
environment: development8.13. Adding labels and annotations with environment variables
Set environment variables for Infinispan Operator to add labels and annotations that automatically propagate to all Infinispan pods and services.
Add labels and annotations to your Infinispan Operator subscription with the spec.config.env field in one of the following ways:
-
Use the
kubectl edit subscriptioncommand.kubectl edit subscription infinispan -n operators -
Use the Red Hat OpenShift Console.
-
Navigate to Operators > Installed Operators > Infinispan Operator.
-
From the Actions menu, select Edit Subscription.
-
spec:
config:
env:
- name: INFINISPAN_OPERATOR_TARGET_LABELS
value: |
{"service-label1":"value",
service-label1":"value"}
- name: INFINISPAN_OPERATOR_POD_TARGET_LABELS
value: |
{"pod-label1":"value",
"pod-label2":"value"}
- name: INFINISPAN_OPERATOR_TARGET_ANNOTATIONS
value: |
{"service-annotation1":"value",
"service-annotation2":"value"}
- name: INFINISPAN_OPERATOR_POD_TARGET_ANNOTATIONS
value: |
{"pod-annotation1":"value",
"pod-annotation2":"value"}8.14. Adding environment variables to Infinispan pods
Configure custom environment variables for the Infinispan nodes managed by the Infinispan Operator.
You can use literal values to tune behavior, such as JAVA_OPTS, or reference values from Secrets and ConfigMaps for sensitive data like credentials. To get more information on valid environment variables accepted by a
-
Open your
InfinispanCR for editing. -
Define environment variables in the
spec.container.envsection.Adding or modifying environment variables triggers a rolling update of the Infinispan cluster to apply the changes to all pods.
Custom environment variablesspec: container: env: - name: JAVA_OPTIONS value: "-Dkey=value" - name: DB_PASSWORD valueFrom: secretKeyRef: name: my-database-secret key: password -
Apply your
InfinispanCR.
Confirm the environment variables are present in the pods:
kubectl exec <pod-name> -- printenv | grep JAVA_OPTIONS|
Defining |
8.15. Defining environment variables in the Infinispan Operator subscription
You can define environment variables in your Infinispan Operator subscription either when you create or edit the subscription.
spec.config.envfield-
Includes the
nameandvaluefields to define environment variables. ADDITIONAL_VARSvariable-
Includes the names of environment variables in a format of JSON array. Environment variables within the
valueof theADDITIONAL_VARSvariable automatically propagate to each Infinispan Server pod managed by the associated Operator.
-
Ensure the Operator Lifecycle Manager (OLM) is installed.
-
Have an
ocor akubectlclient.
-
Create a subscription definition YAML for your Infinispan Operator:
-
Use the
spec.config.envfield to define environment variables. -
Within the
ADDITIONAL_VARSvariable, include environment variable names in a JSON array.subscription-infinispan.yamlapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: infinispan namespace: operators spec: channel: stable installPlanApproval: Automatic name: infinispan source: operatorhubio-catalog sourceNamespace: olm config: env: - name: ADDITIONAL_VARS value: "[\"VAR_NAME\", \"ANOTHER_VAR\"]" - name: VAR_NAME value: $(VAR_NAME_VALUE) - name: ANOTHER_VAR value: $(ANOTHER_VAR_VALUE)For example, use the environment variables to set the local time zone:
subscription-infinispan.yamlkind: Subscription spec: ... config: env: - name: ADDITIONAL_VARS value: "[\"TZ\"]" - name: TZ value: "JST-9"
-
-
Create a subscription for Infinispan Operator:
kubectl apply -f subscription-infinispan.yaml
-
Retrieve the environment variables from the
subscription-infinispan.yaml:kubectl get subscription infinispan -n operators -o jsonpath='{.spec.config.env[*].name}'
-
Use the
kubectl edit subscriptioncommand to modify the environment variable:kubectl edit subscription infinispan -n operators -
To ensure the changes take effect on your Infinispan clusters, you must recreate the existing clusters. Terminate the pods by deleting the
StatefulSetassociated with the existingInfinispanCRs.
9. Configuring authentication
Application users need credentials to access Infinispan clusters. You can use default, generated credentials or add your own.
9.1. Default credentials
Infinispan Operator generates base64-encoded credentials for the following users:
| User | Secret name | Description |
|---|---|---|
|
|
Credentials for the default application user. |
|
|
Credentials that Infinispan Operator uses to interact with Infinispan resources. |
9.2. Retrieving credentials
Get credentials from authentication secrets to access Infinispan clusters.
-
Retrieve credentials from authentication secrets.
kubectl get secret infinispan-generated-secretBase64-decode credentials.
kubectl get secret infinispan-generated-secret -o jsonpath="{.data.identities\.yaml}" | base64 --decode
9.3. Adding custom user credentials
Configure access to Infinispan cluster endpoints with custom credentials.
|
Modifying |
-
Create an
identities.yamlfile with the credentials that you want to add.credentials: - username: myfirstusername password: changeme-one - username: mysecondusername password: changeme-two -
Create an authentication secret from
identities.yaml.kubectl create secret generic --from-file=identities.yaml connect-secret -
Specify the authentication secret with
spec.security.endpointSecretNamein yourInfinispanCR and then apply the changes.spec: security: endpointSecretName: connect-secret
9.4. Changing the operator password
You can change the password for the operator user if you do not want to use the automatically generated password.
-
Update the
passwordkey in theinfinispan-generated-operator-secretsecret as follows:kubectl patch secret infinispan-generated-operator-secret -p='{"stringData":{"password": "supersecretoperatorpassword"}}'You should update only the
passwordkey in thegenerated-operator-secretsecret. When you update the password, Infinispan Operator automatically refreshes other keys in that secret.
9.5. Disabling user authentication
Allow users to access Infinispan clusters and manipulate data without providing credentials.
|
Do not disable authentication if endpoints are accessible from outside the Kubernetes cluster via |
-
Set
falseas the value for thespec.security.endpointAuthenticationfield in yourInfinispanCR.spec: security: endpointAuthentication: false -
Apply the changes.
10. Configuring client certificate authentication
Add client trust stores to your project and configure Infinispan to allow connections only from clients that present valid certificates. This increases security of your deployment by ensuring that clients are trusted by a public certificate authority (CA).
10.1. Client certificate authentication
Client certificate authentication restricts in-bound connections based on the certificates that clients present.
You can configure Infinispan to use trust stores with either of the following strategies:
To validate client certificates, Infinispan requires a trust store that contains any part of the certificate chain for the signing authority, typically the root CA certificate. Any client that presents a certificate signed by the CA can connect to Infinispan.
If you use the Validate strategy for verifying client certificates, you must also configure clients to provide valid Infinispan credentials if you enable authentication.
Requires a trust store that contains all public client certificates in addition to the root CA certificate. Only clients that present a signed certificate can connect to Infinispan.
If you use the Authenticate strategy for verifying client certificates, you must ensure that certificates contain valid Infinispan credentials as part of the distinguished name (DN).
10.2. Enabling client certificate authentication
To enable client certificate authentication, you configure Infinispan to use trust stores with either the Validate or Authenticate strategy.
-
Set either
ValidateorAuthenticateas the value for thespec.security.endpointEncryption.clientCertfield in yourInfinispanCR.The default value is
None. -
Specify the secret that contains the client trust store with the
spec.security.endpointEncryption.clientCertSecretNamefield.By default Infinispan Operator expects a trust store secret named
<cluster-name>-client-cert-secret.The secret must be unique to each
InfinispanCR instance in the Kubernetes cluster. When you delete theInfinispanCR, Kubernetes also automatically deletes the associated secret.spec: security: endpointEncryption: type: Secret certSecretName: tls-secret clientCert: Validate clientCertSecretName: infinispan-client-cert-secret -
Apply the changes.
Provide Infinispan Operator with a trust store that contains all client certificates. Alternatively you can provide certificates in PEM format and let Infinispan generate a client trust store.
10.3. Providing client truststores
If you have a trust store that contains the required certificates you can make it available to Infinispan Operator.
Infinispan supports trust stores in PKCS12 format only.
-
Specify the name of the secret that contains the client trust store as the value of the
metadata.namefield.The name must match the value of the
spec.security.endpointEncryption.clientCertSecretNamefield. -
Provide the password for the trust store with the
stringData.truststore-passwordfield. -
Specify the trust store with the
data.truststore.p12field.apiVersion: v1 kind: Secret metadata: name: infinispan-client-cert-secret type: Opaque stringData: truststore-password: changme data: truststore.p12: "<base64_encoded_PKCS12_trust_store>" -
Apply the changes.
10.4. Providing client certificates
Infinispan Operator can generate a trust store from certificates in PEM format.
-
Specify the name of the secret that contains the client trust store as the value of the
metadata.namefield.The name must match the value of the
spec.security.endpointEncryption.clientCertSecretNamefield. -
Specify the signing certificate, or CA certificate bundle, as the value of the
data.trust.cafield. -
If you use the
Authenticatestrategy to verify client identities, add the certificate for each client that can connect to Infinispan endpoints with thedata.trust.cert.<name>field.Infinispan Operator uses the
<name>value as the alias for the certificate when it generates the trust store. -
Optionally provide a password for the trust store with the
stringData.truststore-passwordfield.If you do not provide one, Infinispan Operator sets "password" as the trust store password.
apiVersion: v1 kind: Secret metadata: name: infinispan-client-cert-secret type: Opaque stringData: truststore-password: changme data: trust.ca: "<base64_encoded_CA_certificate>" trust.cert.client1: "<base64_encoded_client_certificate>" trust.cert.client2: "<base64_encoded_client_certificate>" -
Apply the changes.
11. Configuring encryption
Encrypt connections between clients and Infinispan pods with Red Hat OpenShift service certificates or custom TLS certificates.
11.1. Encryption with Red Hat OpenShift service certificates
Infinispan Operator automatically generates TLS certificates that are signed by the Red Hat OpenShift service CA. Infinispan Operator then stores the certificates and keys in a secret so you can retrieve them and use with remote clients.
If the Red Hat OpenShift service CA is available, Infinispan Operator adds the following spec.security.endpointEncryption configuration to the Infinispan CR:
spec:
security:
endpointEncryption:
type: Service
certServiceName: service.beta.openshift.io
certSecretName: infinispan-cert-secret| Field | Description |
|---|---|
|
Specifies the service that provides TLS certificates. |
|
Specifies a secret with a service certificate and key in PEM format. Defaults to |
|
Service certificates use the internal DNS name of the Infinispan cluster as the common name (CN), for example:
For this reason, service certificates can be fully trusted only inside OpenShift. If you want to encrypt connections with clients running outside OpenShift, you should use custom TLS certificates. Service certificates are valid for one year and are automatically replaced before they expire. |
11.2. Retrieving TLS certificates
Get TLS certificates from encryption secrets to create client trust stores.
-
Retrieve
tls.crtfrom encryption secrets as follows:kubectl get secret infinispan-cert-secret -o jsonpath='{.data.tls\.crt}' | base64 --decode > tls.crt
11.3. Disabling encryption
You can disable encryption so clients do not need TLS certificates to establish connections with Infinispan.
|
Do not disable encryption if endpoints are accessible from outside the Kubernetes cluster via |
-
Set
Noneas the value for thespec.security.endpointEncryption.typefield in yourInfinispanCR.spec: security: endpointEncryption: type: None -
Apply the changes.
11.4. Using custom TLS certificates
Use custom PKCS12 keystore or TLS certificate/key pairs to encrypt connections between clients and Infinispan clusters.
-
Create either a keystore or certificate secret.
The secret must be unique to each
InfinispanCR instance in the Kubernetes cluster. When you delete theInfinispanCR, Kubernetes also automatically deletes the associated secret.
-
Add the encryption secret to your OpenShift namespace, for example:
kubectl apply -f tls_secret.yaml -
Specify the encryption secret with the
spec.security.endpointEncryption.certSecretNamefield in yourInfinispanCR.spec: security: endpointEncryption: type: Secret certSecretName: tls-secret -
Apply the changes.
11.4.1. Custom encryption secrets
Custom encryption secrets that add keystores or certificate/key pairs to secure Infinispan connections must contain specific fields.
apiVersion: v1
kind: Secret
metadata:
name: tls-secret
type: Opaque
stringData:
alias: server
password: changeme
data:
keystore.p12: "MIIKDgIBAzCCCdQGCSqGSIb3DQEHA..."| Field | Description |
|---|---|
|
Specifies an alias for the keystore. |
|
Specifies the keystore password. |
|
Adds a base64-encoded keystore. |
apiVersion: v1
kind: Secret
metadata:
name: tls-secret
type: Opaque
data:
tls.key: "LS0tLS1CRUdJTiBQUk ..."
tls.crt: "LS0tLS1CRUdJTiBDRVl ..."| Field | Description |
|---|---|
|
Adds a base64-encoded TLS key. |
|
Adds a base64-encoded TLS certificate. |
12. Configuring user roles and permissions
Secure access to Infinispan services by configuring role-based access control (RBAC) for users. This requires you to assign roles to users so that they have permission to access caches and Infinispan resources.
12.1. Enabling security authorization
By default authorization is disabled to ensure backwards compatibility with Infinispan CR instances.
Complete the following procedure to enable authorization and use role-based access control (RBAC) for Infinispan users.
-
Set
trueas the value for thespec.security.authorization.enabledfield in yourInfinispanCR.spec: security: authorization: enabled: true -
Apply the changes.
12.2. User roles and permissions
Infinispan Operator provides a set of default roles that are associated with different permissions.
| Role | Permissions | Description |
|---|---|---|
|
ALL |
Superuser with all permissions including control of the Cache Manager lifecycle. |
|
ALL_READ, ALL_WRITE, LISTEN, EXEC, MONITOR, CREATE |
Can create and delete Infinispan resources in addition to |
|
ALL_READ, ALL_WRITE, LISTEN, EXEC, MONITOR |
Has read and write access to Infinispan resources in addition to |
|
ALL_READ, MONITOR |
Has read access to Infinispan resources in addition to |
|
MONITOR |
Can view statistics for Infinispan clusters. |
Infinispan Operator credentials
Infinispan Operator generates credentials that it uses to authenticate with Infinispan clusters to perform internal operations.
By default Infinispan Operator credentials are automatically assigned the admin role when you enable security authorization.
-
How security authorization works (Infinispan Security Guide).
12.3. Assigning roles and permissions to users
Assign users with roles that control whether users are authorized to access Infinispan cluster resources. Roles can have different permission levels, from read-only to unrestricted access.
|
Users gain authorization implicitly.
For example, "admin" gets |
-
Create an
identities.yamlfile that assigns roles to users.credentials: - username: admin password: changeme - username: my-user-1 password: changeme roles: - admin - username: my-user-2 password: changeme roles: - monitor -
Create an authentication secret from
identities.yaml.If necessary, delete the existing secret first.
kubectl delete secret connect-secret --ignore-not-found kubectl create secret generic --from-file=identities.yaml connect-secret -
Specify the authentication secret with
spec.security.endpointSecretNamein yourInfinispanCR and then apply the changes.spec: security: endpointSecretName: connect-secret
12.4. Adding custom roles and permissions
You can define custom roles with different combinations of permissions.
-
Open your
InfinispanCR for editing. -
Specify custom roles and their associated permissions with the
spec.security.authorization.rolesfield.spec: security: authorization: enabled: true roles: - name: my-role-1 permissions: - ALL - name: my-role-2 permissions: - READ - WRITE -
Apply the changes.
13. Configuring network access to Infinispan
Expose Infinispan clusters so you can access Infinispan Console, the Infinispan command line interface (CLI), REST API, and Hot Rod endpoint.
13.1. Getting the service for internal connections
By default, Infinispan Operator creates a service that provides access to Infinispan clusters from clients running on Kubernetes.
This internal service has the same name as your Infinispan cluster, for example:
metadata:
name: infinispan-
Check that the internal service is available as follows:
kubectl get services
13.2. Exposing Infinispan through a LoadBalancer service
Use a LoadBalancer service to make Infinispan clusters available to clients running outside Kubernetes.
|
To access Infinispan with unencrypted Hot Rod client connections you must use
a |
-
Include
spec.exposein yourInfinispanCR. -
Specify
LoadBalanceras the service type with thespec.expose.typefield. -
Optionally specify the network port where the service is exposed with the
spec.expose.portfield.spec: expose: type: LoadBalancer port: 65535 -
Apply the changes.
-
Verify that the
-externalservice is available.kubectl get services | grep external
13.3. Exposing Infinispan through a NodePort service
Use a NodePort service to expose Infinispan clusters on the network.
-
Include
spec.exposein yourInfinispanCR. -
Specify
NodePortas the service type with thespec.expose.typefield. -
Configure the port where Infinispan is exposed with the
spec.expose.nodePortfield.spec: expose: type: NodePort nodePort: 30000 -
Apply the changes.
-
Verify that the
-externalservice is available.kubectl get services | grep external
13.4. Exposing Infinispan through a Route
Use a Kubernetes Ingress or an OpenShift Route with passthrough encryption to make Infinispan clusters available on the network.
| To access Infinispan with Hot Rod client, you must configure TLS with SNI. |
-
Include
spec.exposein yourInfinispanCR. -
Specify
Routeas the service type with thespec.expose.typefield. -
Optionally add a hostname with the
spec.expose.hostfield.spec: expose: type: Route host: www.example.org -
Apply the changes.
-
Verify that the route is available.
kubectl get ingress
Route portsWhen you create a Route, it exposes a port on the network that accepts client connections and redirects traffic to Infinispan services that listen on port 11222.
The port where the Route is available depends on whether you use encryption or not.
| Port | Description |
|---|---|
|
Encryption is disabled. |
|
Encryption is enabled. |
13.5. Network services
Reference information for network services that Infinispan Operator creates and manages.
| Service | Port | Protocol | Description |
|---|---|---|---|
|
|
TCP |
Access to Infinispan endpoints within the Kubernetes cluster or from an OpenShift |
|
|
TCP |
Access to Infinispan endpoints within the Kubernetes cluster for internal Infinispan Operator use. This port utilises a different security-realm to port 11222 and should not be accessed by user applications. |
|
|
TCP |
Cluster discovery for Infinispan pods. |
|
|
TCP |
Access to Infinispan endpoints from a |
|
|
TCP |
JGroups RELAY2 channel for cross-site communication. |
The Infinispan Console should only be accessed via Kubernetes services or an OpenShift Route exposing port 11222.
|
14. Setting up cross-site replication
Ensure availability with Infinispan Operator by configuring geographically distributed clusters as a unified service.
You can configure clusters to perform cross-site replication with:
-
Connections that Infinispan Operator manages.
-
Connections that you configure and manage.
|
You can use both managed and manual connections for Infinispan clusters in the same |
14.1. Cross-site replication expose types
You can use a NodePort service, a LoadBalancer service, or an OpenShift Route to handle network traffic for backup operations between Infinispan clusters.
Before you start setting up cross-site replication you should determine what expose type is available for your Red Hat OpenShift cluster.
In some cases you may require an administrator to provision services before you can configure an expose type.
NodePortA NodePort is a service that accepts network traffic at a static port, in the 30000 to 32767 range, on an IP address that is available externally to the OpenShift cluster.
To use a NodePort as the expose type for cross-site replication, an administrator must provision external IP addresses for each OpenShift node.
In most cases, an administrator must also configure DNS routing for those external IP addresses.
LoadBalancerA LoadBalancer is a service that directs network traffic to the correct node in the OpenShift cluster.
Whether you can use a LoadBalancer as the expose type for cross-site replication depends on the host platform.
AWS supports network load balancers (NLB) while some other cloud platforms do not.
To use a LoadBalancer service, an administrator must first create an ingress controller backed by an NLB.
RouteAn OpenShift Route allows Infinispan clusters to connect with each other through a public secure URL.
Infinispan uses TLS with the SNI header to send backup requests between clusters through an OpenShift Route.
To do this you must add a keystore with TLS certificates so that Infinispan can encrypt network traffic for cross-site replication.
When you specify Route as the expose type for cross-site replication, Infinispan Operator creates a route with TLS passthrough encryption for each Infinispan cluster that it manages.
You can specify a hostname for the Route but you cannot specify a Route that you have already created.
Likewise it is not possible to use an ingress instead of a route because Kubernetes does not support TLS+SNI.
14.2. Managed cross-site replication
Infinispan Operator can discover Infinispan clusters running in different data centers to form global clusters.
When you configure managed cross-site connections, Infinispan Operator creates router pods in each Infinispan cluster.
Infinispan pods use the <cluster_name>-site service to connect to these router pods and send backup requests.
Router pods maintain a record of all pod IP addresses and parse RELAY message headers to forward backup requests to the correct Infinispan cluster. If a router pod crashes then all Infinispan pods start using any other available router pod until Kubernetes restores it.
|
To manage cross-site connections, Infinispan Operator uses the Kubernetes API. Each OpenShift cluster must have network access to the remote Kubernetes API and a service account token for each backup cluster. |
|
Infinispan clusters do not start running until Infinispan Operator discovers all backup locations that you configure. |
14.2.1. Creating service account tokens for managed cross-site connections
Generate service account tokens on OpenShift clusters that allow Infinispan Operator to automatically discover Infinispan clusters and manage cross-site connections.
This procedure is specific to OpenShift clusters. If you are using another Kubernetes distribution, you should create site access secrets instead.
-
Ensure all OpenShift clusters have access to the Kubernetes API.
Infinispan Operator uses this API to manage cross-site connections.Infinispan Operator does not modify remote Infinispan clusters. The service account tokens provide read-only access through the Kubernetes API.
-
Log in to an OpenShift cluster.
-
Create a service account.
For example, create a service account at LON:
oc create sa -n <namespace> lon -
Add the view role to the service account with the following command:
oc policy add-role-to-user view -n <namespace> -z lon -
If you use a
NodePortservice to expose Infinispan clusters on the network, you must also add thecluster-readerrole to the service account:oc adm policy add-cluster-role-to-user cluster-reader -z lon -n <namespace> -
Repeat the preceding steps on your other OpenShift clusters.
-
Exchange service account tokens on each OpenShift cluster.
14.2.2. Exchanging service account tokens
Generate service account tokens on your OpenShift clusters and add them into secrets at each backup location. The tokens that you generate in this procedure do not expire. For bound service account tokens, see Exchanging bound service account tokens.
-
You have created a service account.
-
Log in to your OpenShift cluster.
-
Create a service account token secret file as follows:
sa-token.yamlapiVersion: v1 kind: Secret metadata: name: ispn-xsite-sa-token (1) annotations: kubernetes.io/service-account.name: "<service-account>" (2) type: kubernetes.io/service-account-token1 Specifies the name of the secret. 2 Specifies the service account name. -
Create the secret in your OpenShift cluster:
oc -n <namespace> create -f sa-token.yaml -
Retrieve the service account token:
oc -n <namespace> get secrets ispn-xsite-sa-token -o jsonpath="{.data.token}" | base64 -dThe command prints the token in the terminal.
-
Copy the token for deployment in the backup OpenShift cluster.
-
Log in to the backup OpenShift cluster.
-
Add the service account token for a backup location:
oc -n <namespace> create secret generic <token-secret> --from-literal=token=<token>The
<token-secret>is the name of the secret configured in theInfinispanCR.
-
Repeat the preceding steps on your other OpenShift clusters.
14.2.3. Exchanging bound service account tokens
Create service account tokens with a limited lifespan and add them into secrets at each backup location. You must refresh the token periodically to prevent Infinispan Operator from losing access to the remote OpenShift cluster. For non-expiring tokens, see Exchanging service account tokens.
-
You have created a service account.
-
Log in to your OpenShift cluster.
-
Create a bound token for the service account:
oc -n <namespace> create token <service-account>By default, service account tokens are valid for one hour. Use the command option
--durationto specify the lifespan in seconds..The command prints the token in the terminal.
-
Copy the token for deployment in the backup OpenShift cluster(s).
-
Log in to the backup OpenShift cluster.
-
Add the service account token for a backup location:
oc -n <namespace> create secret generic <token-secret> --from-literal=token=<token>The
<token-secret>is the name of the secret configured in theInfinispanCR. -
Repeat the steps on other OpenShift clusters.
Deleting expired tokens
When a token expires, delete the expired token secret, and then repeat the procedure to generate and exchange a new one.
-
Log in to the backup OpenShift cluster.
-
Delete the expired secret
<token-secret>:oc -n <namespace> delete secrets <token-secret> -
Repeat the procedure to create a new token and generate a new
<token-secret>.
14.2.4. Setting up Kubernetes for managed cross-site connections
Apply cluster roles and create site access secrets on Kubernetes to use cross-site replication capabilities.
-
Install
role.yamlandrole_binding.yamlif you install Infinispan Operator manually.During OLM installation, Infinispan Operator sets up cluster roles required for cross-site replication.
kubectl apply -f config/rbac/role.yaml kubectl apply -f config/rbac/role_binding.yaml -
If you run Infinispan Operator in any Kubernetes deployment (Minikube, Kind, and so on), you should create secrets that contain the files that allow Kubernetes clusters to authenticate with each other.
Do one of the following:
-
Retrieve service account tokens from each site and then add them to secrets on each backup location, for example:
kubectl create serviceaccount site-a -n ns-site-a kubectl create clusterrole xsite-cluster-role --verb=get,list,watch --resource=nodes,services kubectl create clusterrolebinding xsite-cluster-role-binding --clusterrole=xsite-cluster-role --serviceaccount=ns-site-a:site-a TOKENNAME=kubectl get serviceaccount/site-a -o jsonpath='{.secrets[0].name}' -n ns-site-a TOKEN=kubectl get secret $TOKENNAME -o jsonpath='{.data.token}' -n ns-site-a | base64 --decode kubectl create secret generic site-a-secret -n ns-site-a --from-literal=token=$TOKEN -
Create secrets on each site that contain
ca.crt,client.crt, andclient.keyfrom your Kubernetes installation.For example, for Minikube do the following on LON:
kubectl create secret generic site-a-secret \ --from-file=certificate-authority=/opt/minikube/.minikube/ca.crt \ --from-file=client-certificate=/opt/minikube/.minikube/client.crt \ --from-file=client-key=/opt/minikube/.minikube/client.key
-
14.2.5. Configuring managed cross-site connections
Configure Infinispan Operator to establish cross-site views with Infinispan clusters.
-
Determine a suitable expose type for cross-site replication.
If you use an OpenShiftRouteyou must add a keystore with TLS certificates and secure cross-site connections. -
Create and exchange Red Hat OpenShift service account tokens for each Infinispan cluster.
Or, if you are using Kubernetes, apply cluster roles and create site access secrets.
-
Create an
InfinispanCR for each Infinispan cluster. -
Specify the name of the local site with
spec.service.sites.local.name. -
Configure the expose type for cross-site replication.
-
Set the value of the
spec.service.sites.local.expose.typefield to one of the following:-
NodePort -
LoadBalancer -
Route
-
-
Optionally specify a port or custom hostname with the following fields:
-
spec.service.sites.local.expose.nodePortif you use aNodePortservice. -
spec.service.sites.local.expose.portif you use aLoadBalancerservice. -
spec.service.sites.local.expose.routeHostNameif you use an OpenShiftRoute.
-
-
-
Specify the number of pods that can send RELAY messages with the
service.sites.local.maxRelayNodesfield.Configure all pods in your cluster to send
RELAYmessages for better performance. If all pods send backup requests directly, then no pods need to forward backup requests. -
Provide the name, URL, and secret for each Infinispan cluster that acts as a backup location with
spec.service.sites.locations. -
If Infinispan cluster names or namespaces at the remote site do not match the local site, specify those values with the
clusterNameandnamespacefields.The following are example
InfinispanCR definitions for LON and NYC:-
LON
apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 3 version: <Infinispan_version> service: type: DataGrid sites: local: name: LON expose: type: LoadBalancer port: 65535 maxRelayNodes: 1 locations: - name: NYC clusterName: <nyc_cluster_name> namespace: <nyc_cluster_namespace> url: openshift://api.rhdg-nyc.openshift-aws.myhost.com:6443 secretName: nyc-token logging: categories: org.jgroups.protocols.TCP: error org.jgroups.protocols.relay.RELAY2: error -
NYC
apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: nyc-cluster spec: replicas: 2 version: <Infinispan_version> service: type: DataGrid sites: local: name: NYC expose: type: LoadBalancer port: 65535 maxRelayNodes: 1 locations: - name: LON clusterName: infinispan namespace: ispn-namespace url: openshift://api.rhdg-lon.openshift-aws.myhost.com:6443 secretName: lon-token logging: categories: org.jgroups.protocols.TCP: error org.jgroups.protocols.relay.RELAY2: errorBe sure to adjust logging categories in your
InfinispanCR to decrease log levels for JGroups TCP and RELAY2 protocols. This prevents a large number of log files from uses container storage.spec: logging: categories: org.jgroups.protocols.TCP: error org.jgroups.protocols.relay.RELAY2: error
-
-
Configure your
InfinispanCRs with any other Data Grid Service resources and then apply the changes. -
Verify that Infinispan clusters form a cross-site view.
-
Retrieve the
InfinispanCR.kubectl get infinispan -o yaml -
Check for the
type: CrossSiteViewFormedcondition.
-
If your clusters have formed a cross-site view, you can start adding backup locations to caches.
14.3. Manually configuring cross-site connections
You can specify static network connection details to perform cross-site replication with Infinispan clusters running outside Kubernetes. Manual cross-site connections are necessary in any scenario where access to the Kubernetes API is not available outside the Kubernetes cluster where Infinispan runs.
-
Determine a suitable expose type for cross-site replication.
If you use an OpenShiftRouteyou must add a keystore with TLS certificates and secure cross-site connections. -
Ensure you have the correct host names and ports for each Infinispan cluster and each
<cluster-name>-siteservice.Manually connecting Infinispan clusters to form cross-site views requires predictable network locations for Infinispan services, which means you need to know the network locations before they are created.
-
Create an
InfinispanCR for each Infinispan cluster. -
Specify the name of the local site with
spec.service.sites.local.name. -
Configure the expose type for cross-site replication.
-
Set the value of the
spec.service.sites.local.expose.typefield to one of the following:-
NodePort -
LoadBalancer -
Route
-
-
Optionally specify a port or custom hostname with the following fields:
-
spec.service.sites.local.expose.nodePortif you use aNodePortservice. -
spec.service.sites.local.expose.portif you use aLoadBalancerservice. -
spec.service.sites.local.expose.routeHostNameif you use an OpenShiftRoute.
-
-
-
Provide the name and static URL for each Infinispan cluster that acts as a backup location with
spec.service.sites.locations, for example:-
LON
apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 3 version: <Infinispan_version> service: type: DataGrid sites: local: name: LON expose: type: LoadBalancer port: 65535 maxRelayNodes: 1 locations: - name: NYC url: infinispan+xsite://infinispan-nyc.myhost.com:7900 logging: categories: org.jgroups.protocols.TCP: error org.jgroups.protocols.relay.RELAY2: error -
NYC
apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 2 version: <Infinispan_version> service: type: DataGrid sites: local: name: NYC expose: type: LoadBalancer port: 65535 maxRelayNodes: 1 locations: - name: LON url: infinispan+xsite://infinispan-lon.myhost.com logging: categories: org.jgroups.protocols.TCP: error org.jgroups.protocols.relay.RELAY2: errorBe sure to adjust logging categories in your
InfinispanCR to decrease log levels for JGroups TCP and RELAY2 protocols. This prevents a large number of log files from uses container storage.spec: logging: categories: org.jgroups.protocols.TCP: error org.jgroups.protocols.relay.RELAY2: error
-
-
Configure your
InfinispanCRs with any other Data Grid Service resources and then apply the changes. -
Verify that Infinispan clusters form a cross-site view.
-
Retrieve the
InfinispanCR.kubectl get infinispan -o yaml -
Check for the
type: CrossSiteViewFormedcondition.
-
If your clusters have formed a cross-site view, you can start adding backup locations to caches.
14.4. Allocating CPU and memory for Gossip router pod
Allocate CPU and memory resources to Infinispan Gossip router.
-
Have Gossip router enabled. The
service.sites.local.discovery.launchGossipRouterproperty must be set totrue, which is the default value.
-
Allocate the number of CPU units using the
service.sites.local.discovery.cpufield. -
Allocate the amount of memory, in bytes, using the
service.sites.local.discovery.memoryfield.The
cpuandmemoryfields have values in the format of<limit>:<requests>. For example,cpu: "2000m:1000m"limits pods to a maximum of2000mof CPU and requests1000mof CPU for each pod at startup. Specifying a single value sets both the limit and request. -
Apply your
InfinispanCR.
spec:
service:
type: DataGrid
sites:
local:
name: LON
discovery:
launchGossipRouter: true
memory: "2Gi:1Gi"
cpu: "2000m:1000m"14.5. Disabling local Gossip router and service
The Infinispan Operator starts a Gossip router on each site, but you only need a single Gossip router to manage traffic between the Infinispan cluster members. You can disable the additional Gossip routers to save resources.
For example, you have Infinispan clusters in LON and NYC sites. The following procedure shows how you can disable Gossip router in LON site and connect to NYC that has the Gossip router enabled.
-
Create an
InfinispanCR for each Infinispan cluster. -
Specify the name of the local site with the
spec.service.sites.local.namefield. -
For the LON cluster, set
falseas the value for thespec.service.sites.local.discovery.launchGossipRouterfield. -
For the LON cluster, specify the
urlwith thespec.service.sites.locations.urlto connect to the NYC. -
In the NYC configuration, do not specify the
spec.service.sites.locations.url.LONapiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 3 service: type: DataGrid sites: local: name: LON discovery: launchGossipRouter: false locations: - name: NYC url: infinispan+xsite://infinispan-nyc.myhost.com:7900NYCapiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 3 service: type: DataGrid sites: local: name: NYC locations: - name: LON
|
If you have three or more sites, Infinispan recommends to keep the Gossip router enabled on all the remote sites. When you have multiple Gossip routers and one of them becomes unavailable, the remaining routers continue exchanging messages. If a single Gossip router is defined, and it becomes unavailable, the connection between the remote sites breaks. |
If your clusters have formed a cross-site view, you can start adding backup locations to caches.
14.6. Resources for configuring cross-site replication
The following tables provides fields and descriptions for cross-site resources.
| Field | Description |
|---|---|
|
Infinispan supports cross-site replication with Data Grid Service clusters only. |
| Field | Description |
|---|---|
|
Names the local site where a Infinispan cluster runs. |
|
Specifies the maximum number of pods that can send RELAY messages for cross-site replication. The default value is |
|
If |
|
Allocates the amount of memory in bytes. It uses the following format |
|
Allocates the number of CPU units. It uses the following format |
|
Specifies the network service for cross-site replication. Infinispan clusters use this service to communicate and perform backup operations. You can set the value to |
|
Specifies a static port within the default range of |
|
Specifies the network port for the service if you expose Infinispan through a |
|
Specifies a custom hostname if you expose Infinispan through an OpenShift |
| Field | Description |
|---|---|
|
Provides connection information for all backup locations. |
|
Specifies a backup location that matches |
|
Specifies the URL of the Kubernetes API for managed connections or a static URL for manual connections. Use Use Note that the Use the |
|
Specifies the secret that contains the service account token for the backup site. If you set up cross-site on Kubernetes this field specifies the access secret for a site which can be any appropriate authentication object. |
|
Specifies the cluster name at the backup location if it is different to the cluster name at the local site. |
|
Specifies the namespace of the Infinispan cluster at the backup location if it does not match the namespace at the local site. |
Managed cross-site connections
spec:
service:
type: DataGrid
sites:
local:
name: LON
expose:
type: LoadBalancer
maxRelayNodes: 1
locations:
- name: NYC
clusterName: <nyc_cluster_name>
namespace: <nyc_cluster_namespace>
url: openshift://api.site-b.devcluster.openshift.com:6443
secretName: nyc-tokenManual cross-site connections
spec:
service:
type: DataGrid
sites:
local:
name: LON
expose:
type: LoadBalancer
port: 65535
maxRelayNodes: 1
locations:
- name: NYC
url: infinispan+xsite://infinispan-nyc.myhost.com:790014.7. Securing cross-site connections
Add keystores and trust stores so that Infinispan clusters can secure cross-site replication traffic.
You must add a keystore to use an OpenShift Route as the expose type for cross-site replication.
Securing cross-site connections is optional if you use a NodePort or LoadBalancer as the expose type.
|
Cross-site replication does not support the Kubernetes CA service. You must provide your own certificates. |
-
Create the key store and trust store using Keytool (certificate management utility included with Java).
-
Generate a self-signed certificate.
keytool -genkey -alias server -keyalg RSA -storetype PKCS12 -keystore ./keystore.p12 -validity <days> -storepass <password> -
Export the certificate from the key store, so that it can be present in the trust store
keytool -export -alias server -keystore ./keystore.p12 -storetype PKCS12 -rfc -file ~/server_cert.pem -storepass <password> -
Create the trust store and import the certificate
keytool -importcert -alias server -keystore ./truststore.p12 -storetype PKCS12 -file ~/server_cert.pem -storepass <password> -noprompt
-
-
Create cross-site encryption secret for each Infinispan cluster.
-
Create keystore secrets.
oc create secret generic keystore-tls-secret \ --from-file=keystore.p12=./keystore.p12 \ --from-literal=password=<password> \ --from-literal=type=pkcs12 -
Create trust store secrets.
oc create secret generic truststore-tls-secret \ --from-file=truststore.p12=./truststore.p12 \ --from-literal=password=<password> \ --from-literal=type=pkcs12
-
-
Modify the Infinispan CR for each Infinispan cluster to specify the secret name for the
encryption.transportKeyStore.secretNameandencryption.routerKeyStore.secretNamefields.apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 2 version: <Infinispan_version> expose: type: LoadBalancer service: type: DataGrid sites: local: name: SiteA # ... encryption: protocol: TLSv1.3 transportKeyStore: secretName: keystore-tls-secret alias: server filename: keystore.p12 routerKeyStore: secretName: keystore-tls-secret alias: server filename: keystore.p12 trustStore: secretName: truststore-tls-secret filename: truststore.p12 locations: # ...
|
The procedure describes the easier way to encrypt the communication. More complex setups are possible in the CR, for example, by setting different certificates for Infinispan Pod and Gossip Router Pod. Ensure the truststore contains all the required certificate chain for mutual TLS authentication. |
14.7.1. Resources for configuring cross-site encryption
The following tables provides fields and descriptions for encrypting cross-site connections.
| Field | Description |
|---|---|
|
Specifies the TLS protocol to use for cross-site connections. The default value is |
|
Configures a keystore secret for relay pods. |
|
Configures a keystore secret for router pods. |
|
Configures a trust store secret for relay pods and router pods. |
| Field | Description |
|---|---|
|
Specifies the secret that contains a keystore that relay pods can use to encrypt and decrypt RELAY messages. This field is required. |
|
Optionally specifies the alias of the certificate in the keystore.
The default value is |
|
Optionally specifies the filename of the keystore.
The default value is |
| Field | Description |
|---|---|
|
Specifies the secret that contains a keystore that router pods can use to encrypt and decrypt RELAY messages. This field is required. |
|
Optionally specifies the alias of the certificate in the keystore.
The default value is |
|
Optionally specifies the filename of the keystore.
The default value is |
| Field | Description |
|---|---|
|
Specifies the secret that contains a trust store to verify public certificates for relay pods and router pods. This field is required. |
|
Optionally specifies the filename of the trust store.
The default value is |
14.7.2. Cross-site encryption secrets
Cross-site replication encryption secrets add keystores and trust store for securing cross-site connections.
apiVersion: v1
kind: Secret
metadata:
name: tls-secret
type: Opaque
stringData:
password: changeme
type: pkcs12
data:
<file-name>: "MIIKDgIBAzCCCdQGCSqGSIb3DQEHA..."| Field | Description |
|---|---|
|
Specifies the password for the keystore or trust store. |
|
Optionally specifies the keystore or trust store type. The default value is |
|
Adds a base64-encoded keystore or trust store. |
14.8. Configuring sites in the same Kubernetes cluster
For evaluation and demonstration purposes, you can configure Infinispan to back up between pods in the same Kubernetes cluster.
|
Using |
-
Create an
InfinispanCR for each Infinispan cluster. -
Specify the name of the local site with
spec.service.sites.local.name. -
Set
ClusterIPas the value of thespec.service.sites.local.expose.typefield. -
Provide the name of the Infinispan cluster that acts as a backup location with
spec.service.sites.locations.clusterName. -
If both Infinispan clusters have the same name, specify the namespace of the backup location with
spec.service.sites.locations.namespace.apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: example-clustera spec: replicas: 1 expose: type: LoadBalancer service: type: DataGrid sites: local: name: SiteA expose: type: ClusterIP maxRelayNodes: 1 locations: - name: SiteB clusterName: example-clusterb namespace: cluster-namespace -
Configure your
InfinispanCRs with any other Data Grid Service resources and then apply the changes. -
Verify that Infinispan clusters form a cross-site view.
-
Retrieve the
InfinispanCR.kubectl get infinispan -o yaml -
Check for the
type: CrossSiteViewFormedcondition.
-
15. Monitoring Infinispan services
Infinispan exposes metrics that can be used by Prometheus for monitoring and visualizing the cluster state.
|
This documentation explains how to set up monitoring on OpenShift Container Platform. If you’re working with community Prometheus deployments, you might find these instructions useful as a general guide. However you should refer to the Prometheus documentation for installation and usage instructions. See the Prometheus Operator documentation. |
15.1. Creating a Prometheus service monitor
Infinispan Operator automatically creates a Prometheus ServiceMonitor that scrapes metrics from your Infinispan cluster.
Enable monitoring for user-defined projects on OpenShift Container Platform.
When the Operator detects an Infinispan CR with the monitoring annotation set to true, which is the default, Infinispan Operator does the following:
-
Creates a
ServiceMonitornamed<cluster_name>-monitor. -
Adds the
infinispan.org/monitoring: 'true'annotation to yourInfinispanCR metadata, if the value is not already explicitly set:apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan annotations: infinispan.org/monitoring: 'true'
|
To authenticate with Infinispan, Prometheus uses the |
You can check that Prometheus is scraping Infinispan metrics as follows:
-
In the Kubernetes Dashboard, select the </> Developer perspective and then select Monitoring.
-
Open the Dashboard tab for the namespace where your Infinispan cluster runs.
-
Open the Metrics tab and confirm that you can query Infinispan metrics such as:
vendor_cache_manager_default_cluster_size
15.1.1. Disabling the Prometheus service monitor
You can disable the ServiceMonitor if you do not want Prometheus to scrape metrics for your Infinispan cluster.
-
Set
'false'as the value for theinfinispan.org/monitoringannotation in yourInfinispanCR.apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan annotations: infinispan.org/monitoring: 'false' -
Apply the changes.
15.1.2. Configuring Service Monitor Target Labels
You can configure the generated ServiceMonitor to propagate Service labels to the underlying metrics using the ServiceMonitor spec.targetLabels field.
Use the Service labels to filter and aggregate the metrics collected from the monitored endpoints.
-
Define labels to apply to your service by setting the
infinispan.org/targetLabelsannotation in yourInfinispanCR. -
Specify a comma-separated list of the labels required in your metrics using the
infinispan.org/serviceMonitorTargetLabelsannotation on yourInfinispanCR.apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan annotations: infinispan.org/targetLabels: "label1,label2,label3" infinispan.org/serviceMonitorTargetLabels: "label1,label2" -
Apply the changes.
15.2. Enabling JMX remote ports for Infinispan clusters
Enable JMX remote ports to expose Infinispan MBeans and to integrate Infinispan with external monitoring systems such as Cryostat.
When you enable JMX for Infinispan cluster, the following occurs:
-
Each Infinispan server pod exposes an authenticated JMX endpoint on port
9999utilizing the "admin" security-realm, which includes the Operator user credentials. -
The
<cluster-name>-adminService exposes port9999.
You can enable or disable JMX only during the creation of the Infinispan CR. Once the CR instance is created, you cannot modify the JMX settings.
|
-
Enable JMX in your
InfinispanCR.apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: jmx: enabled: true -
Retrieve the Operator user credentials to authenticate client JMX connections.
kubectl get secret infinispan-generated-operator-secret -o jsonpath="{.data.identities\.yaml}" | base64 --decode
15.3. Setting up JFR recordings with Cryostat
Enable JDK Flight Recorder (JFR) monitoring for your Infinispan clusters that run on Kubernetes.
JFR provides insights into various aspects of JVM performance to ease cluster inspection and debugging. Depending on your requirements, you can store and analyze your recordings using the integrated tools provided by Cryostat or export the recordings to an external monitoring application.
-
Install the Cryostat Operator. You can install the Cryostat Operator in your Kubernetes project by using Operator Lifecycle Manager (OLM).
-
Have JMX enabled on your Infinispan cluster. You must enable JMX before deploying the cluster, as JMX settings cannot be modified after deployment.
-
Create a Cryostat CR in the same namespace as your
InfinispanCR.apiVersion: operator.cryostat.io/v1beta1 kind: Cryostat metadata: name: cryostat-sample spec: minimal: false enableCertManager: trueThe Cryostat Operator requires cert-manager for traffic encryption. If the cert-manager is enabled but not installed, the deployment fails. For details, see the Installing Cryostat Operator guide.
-
Wait for the
CryostatCR to be ready.kubectl wait -n <namespace> --for=condition=MainDeploymentAvailable cryostat/cryostat-sample -
Open the Cryostat
status.applicationUrl.kubectl -n <namespace> get cryostat cryostat-sample -
Retrieve the Operator user credentials to authenticate client JMX connections in the Cryostat UI.
kubectl get secret infinispan-generated-operator-secret -o jsonpath="{.data.identities\.yaml}" | base64 --decode -
In the Cryostat UI, navigate to the Security menu.
-
In the Store Credentials window, click the Add button. The Store Credentials window opens.
-
In the Match Expression filed, enter match expression details in the following format:
target.labels['infinispan_cr'] == '<cluster_name>'
16. Guaranteeing availability with anti-affinity
Kubernetes includes anti-affinity capabilities that protect workloads from single points of failure.
16.1. Anti-affinity strategies
Each Infinispan node in a cluster runs in a pod that runs on an Kubernetes node in a cluster. Each Red Hat OpenShift node runs on a physical host system. Anti-affinity works by distributing Infinispan nodes across Kubernetes nodes, ensuring that your Infinispan clusters remain available even if hardware failures occur.
Infinispan Operator offers two anti-affinity strategies:
kubernetes.io/hostname-
Infinispan replica pods are scheduled on different Kubernetes nodes.
topology.kubernetes.io/zone-
Infinispan replica pods are scheduled across multiple zones.
Fault tolerance
Anti-affinity strategies guarantee cluster availability in different ways.
|
The equations in the following section apply only if the number of Kubernetes nodes or zones is greater than the number of Infinispan nodes. |
Provides tolerance of x node failures for the following types of cache:
-
Replicated:
x = spec.replicas - 1 -
Distributed:
x = num_owners - 1
Provides tolerance of x zone failures when x zones exist for the following types of cache:
-
Replicated:
x = spec.replicas - 1 -
Distributed:
x = num_owners - 1
|
16.2. Configuring anti-affinity
Specify where Kubernetes schedules pods for your Infinispan clusters to ensure availability.
-
Add the
spec.scheduling.affinityblock to yourInfinispanCR. -
Configure anti-affinity strategies as necessary.
-
Apply your
InfinispanCR.
16.2.1. Anti-affinity strategy configurations
Configure anti-affinity strategies in your Infinispan CR to control where Kubernetes schedules Infinispan replica pods.
| Topology keys | Description |
|---|---|
|
Schedules Infinispan replica pods across multiple zones. |
|
Schedules Infinispan replica pods on different Kubernetes nodes. |
Schedule pods on different Kubernetes nodes
The following is the anti-affinity strategy that Infinispan Operator uses if you do not configure the spec.scheduling.affinity field in your Infinispan CR:
spec:
scheduling:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app: infinispan-pod
clusterName: <cluster_name>
infinispan_cr: <cluster_name>
topologyKey: "kubernetes.io/hostname"Requiring different nodes
In the following example, Kubernetes does not schedule Infinispan pods if different nodes are not available:
spec:
scheduling:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: infinispan-pod
clusterName: <cluster_name>
infinispan_cr: <cluster_name>
topologyKey: "topology.kubernetes.io/hostname"|
To ensure that you can schedule Infinispan replica pods on different Kubernetes nodes, the number of Kubernetes nodes available must be greater than the value of |
Schedule pods across multiple Kubernetes zones
The following example prefers multiple zones when scheduling pods but schedules Infinispan replica pods on different Kubernetes nodes if it is not possible to schedule across zones:
spec:
scheduling:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app: infinispan-pod
clusterName: <cluster_name>
infinispan_cr: <cluster_name>
topologyKey: "topology.kubernetes.io/zone"
- weight: 90
podAffinityTerm:
labelSelector:
matchLabels:
app: infinispan-pod
clusterName: <cluster_name>
infinispan_cr: <cluster_name>
topologyKey: "kubernetes.io/hostname"Requiring multiple zones
The following example uses the zone strategy only when scheduling Infinispan replica pods:
spec:
scheduling:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: infinispan-pod
clusterName: <cluster_name>
infinispan_cr: <cluster_name>
topologyKey: "topology.kubernetes.io/zone"17. Auto Scaling
Kubernetes includes the HorizontalPodAutoscaler which allows StatefulSets or Deployments to be automatically scaled up or
down based upon specified metrics. The Infinispan CR exposes the .status.scale sub-resource, which enables HorizontalPodAutoscaler
resources to target the Infinispan CR.
Before defining a HorizontalPodAutoscaler configuration, consider the types of Infinispan caches that you define. Distributed
and Replicated caches have very different scaling requirements, so defining a HorizontalPodAutoscaler for server’s running
a combination of these cache types may not be advantageous. For example, defining a HorizontalPodAutoscaler that scales
when memory usage reaches a certain percentage will allow overall cache capacity to be increased when defining Distributed
caches as cache entries are spread across pods, however it will not work with replicated cache as every pod hosts all cache
entries. Conversely, configuring a HorizontalPodAutoscaler based upon CPU usage will be more beneficial for clusters
with replicated cache as every pod contains all cache entries and so distributing read requests across additional nodes
will allow a greater number of requests to be processed simultaneously.
17.1. Configuring HorizontalPodAutoscaler
Create a HorizontalPodAutoScaler resource that targets your Infinispan CR.
-
Define a
HorizontalPodAutoscalerresource in the same namespace as yourInfinispanCRapiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: infinispan-auto spec: scaleTargetRef: apiVersion: infinispan.org/v1 kind: Infinispan name: example (1) minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 501 The name of your InfinispanCR
If using metric resource of type cpu or memory, you must configure request/limits for this resource in your Infinispan CR.
|
| HorizontalPodAutoscaler should be removed when upgrading a Infinispan cluster, as the automatic scaling will cause the upgrade process to enter unexpected state, as the Operator needs to scale the cluster down to 0 pods. |
18. Creating caches with Infinispan Operator
Use Cache CRs to add cache configuration with Infinispan Operator and control how Infinispan stores your data.
18.1. Infinispan caches
Cache configuration defines the characteristics and features of the data store and must be valid with the Infinispan schema. Infinispan recommends creating standalone files in XML or JSON format that define your cache configuration. You should separate Infinispan configuration from application code for easier validation and to avoid the situation where you need to maintain XML snippets in Java or some other client language.
To create caches with Infinispan clusters running on Kubernetes, you should:
-
Use
CacheCR as the mechanism for creating caches through the Kubernetes front end. -
Use
BatchCR to create multiple caches at a time from standalone configuration files. -
Access Infinispan Console and create caches in XML or JSON format.
You can use Hot Rod or HTTP clients but Infinispan recommends Cache CR or Batch CR unless your specific use case requires programmatic remote cache creation.
Cache CRs
-
CacheCRs apply to Data Grid Service pods only. -
Each
CacheCR corresponds to a single cache on the Infinispan cluster.
18.2. Creating caches with the Cache CR
Complete the following steps to create caches on Data Grid Service clusters using valid configuration in XML or YAML format.
-
Create a
CacheCR with a unique value in themetadata.namefield. -
Specify the target Infinispan cluster with the
spec.clusterNamefield. -
Name your cache with the
spec.namefield.The
nameattribute in the cache configuration does not take effect. If you do not specify a name with thespec.namefield then the cache uses the value of themetadata.namefield. -
Add a cache configuration with the
spec.templatefield. -
Apply the
CacheCR, for example:kubectl apply -f mycache.yaml cache.infinispan.org/mycachedefinition created
Cache CR examples
apiVersion: infinispan.org/v2alpha1
kind: Cache
metadata:
name: mycachedefinition
spec:
clusterName: infinispan
name: myXMLcache
template: <distributed-cache mode="SYNC" statistics="true"><encoding media-type="application/x-protostream"/><persistence><file-store/></persistence></distributed-cache>apiVersion: infinispan.org/v2alpha1
kind: Cache
metadata:
name: mycachedefinition
spec:
clusterName: infinispan
name: myYAMLcache
template: |-
distributedCache:
mode: "SYNC"
owners: "2"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
persistence:
fileStore: ~18.3. Updating caches with the Cache CR
You can control how Infinispan Operator handles modifications to the cache configuration in the Cache CR.
Infinispan Operator attempts to update the cache configuration on the Infinispan Server at runtime. If the update fails, Infinispan Operator uses one of the following strategies:
- retain strategy
-
The Operator updates the status of the
CacheCR toReady=False. You can manually delete theCacheCR and create a new cache configuration. This is the default strategy. - recreate strategy
-
The Operator deletes the cache from the Infinispan cluster and creates a new cache with the latest
spec.templatevalue from theCacheCR.Configure the recreatestrategy only if your deployment can tolerate data loss.
-
Have a valid
CacheCR.
-
Use the
spec.updates.strategyfield to set theCacheCR strategy.mycache.yamlspec: updates: strategy: recreate -
Apply changes to the
CacheCR, for example:oc apply -f mycache.yaml
18.4. Adding persistent cache stores
You can add persistent cache stores to Data Grid Service pods to save data to the persistent volume.
Infinispan creates a Single File cache store, .dat file, in the /opt/infinispan/server/data directory.
-
Add the
<file-store/>element to thepersistenceconfiguration in your Infinispan cache, as in the following example:<distributed-cache name="persistent-cache" mode="SYNC"> <encoding media-type="application/x-protostream"/> <persistence> <file-store/> </persistence> </distributed-cache>
19. Running batch operations
Infinispan Operator provides a Batch CR that lets you create Infinispan resources in bulk.
Batch CR uses the Infinispan command line interface (CLI) in batch mode to carry out sequences of operations.
|
Modifying a |
19.1. Running inline batch operations
Include your batch operations directly in a Batch CR if they do not require separate configuration artifacts.
-
Create a
BatchCR.-
Specify the name of the Infinispan cluster where you want the batch operations to run as the value of the
spec.clusterfield. -
Add each CLI command to run on a line in the
spec.configfield.apiVersion: infinispan.org/v2alpha1 kind: Batch metadata: name: mybatch spec: cluster: infinispan config: | create counter --concurrency-level=1 --initial-value=5 --storage=VOLATILE --type=weak batch-counter
-
-
Apply your
BatchCR.kubectl apply -f mybatch.yaml -
Wait for the
BatchCR to succeed.kubectl wait --for=jsonpath='{.status.phase}'=Succeeded Batch/mybatch
19.2. Creating ConfigMaps for batch operations
Create a ConfigMap so that additional files, such as Infinispan cache configuration, are available for batch operations.
For demonstration purposes, you should add some configuration artifacts to your host filesystem before you start the procedure:
-
Create a
/tmp/mybatchdirectory where you can add some files.mkdir -p /tmp/mybatch -
Create a Infinispan cache configuration.
cat > /tmp/mybatch/mycache.xml<<EOF <distributed-cache name="mycache" mode="SYNC"> <encoding media-type="application/x-protostream"/> <memory max-count="1000000" when-full="REMOVE"/> </distributed-cache> EOF
-
Create a
batchfile that contains all commands you want to run.For example, the following
batchfile creates a cache named "mycache" and adds two entries to it:create cache mycache --file=/etc/batch/mycache.xml put --cache=mycache hello world put --cache=mycache hola mundoThe
ConfigMapis mounted in Infinispan pods at/etc/batch. You must prepend all--file=directives in your batch operations with that path. -
Ensure all configuration artifacts that your batch operations require are in the same directory as the
batchfile.ls /tmp/mybatch batch mycache.xml -
Create a
ConfigMapfrom the directory.kubectl create configmap mybatch-config-map --from-file=/tmp/mybatch
19.3. Running batch operations with ConfigMaps
Run batch operations that include configuration artifacts.
-
Create a
ConfigMapthat contains any files your batch operations require.
-
Create a
BatchCR that specifies the name of a Infinispan cluster as the value of thespec.clusterfield. -
Set the name of the
ConfigMapthat contains yourbatchfile and configuration artifacts with thespec.configMapfield.cat > mybatch.yaml<<EOF apiVersion: infinispan.org/v2alpha1 kind: Batch metadata: name: mybatch spec: cluster: infinispan configMap: mybatch-config-map EOF -
Apply your
BatchCR.kubectl apply -f mybatch.yaml -
Wait for the
BatchCR to succeed.kubectl wait --for=jsonpath='{.status.phase}'=Succeeded Batch/mybatch
19.4. Batch status messages
Verify and troubleshoot batch operations with the status.Phase field in the Batch CR.
| Phase | Description |
|---|---|
|
All batch operations have completed successfully. |
|
Batch operations are queued and resources are initializing. |
|
Batch operations are ready to start. |
|
Batch operations are in progress. |
|
One or more batch operations were not successful. |
Batch operations are not atomic. If a command in a batch script fails, it does not affect the other operations or cause them to rollback.
|
If your batch operations have any server or syntax errors, you can view log messages in the |
19.5. Example batch operations
Use these example batch operations as starting points for creating and modifying Infinispan resources with the Batch CR.
|
You can pass configuration files to Infinispan Operator only via a The |
19.5.1. Caches
-
Create multiple caches from configuration files.
echo "creating caches..."
create cache sessions --file=/etc/batch/infinispan-prod-sessions.xml
create cache tokens --file=/etc/batch/infinispan-prod-tokens.xml
create cache people --file=/etc/batch/infinispan-prod-people.xml
create cache books --file=/etc/batch/infinispan-prod-books.xml
create cache authors --file=/etc/batch/infinispan-prod-authors.xml
echo "list caches in the cluster"
ls caches-
Create a template from a file and then create caches from the template.
echo "creating caches..."
create cache mytemplate --file=/etc/batch/mycache.xml
create cache sessions --template=mytemplate
create cache tokens --template=mytemplate
echo "list caches in the cluster"
ls caches19.5.2. Counters
Use the Batch CR to create multiple counters that can increment and decrement to record the count of objects.
You can use counters to generate identifiers, act as rate limiters, or track the number of times a resource is accessed.
echo "creating counters..."
create counter --concurrency-level=1 --initial-value=5 --storage=PERSISTENT --type=weak mycounter1
create counter --initial-value=3 --storage=PERSISTENT --type=strong mycounter2
create counter --initial-value=13 --storage=PERSISTENT --type=strong --upper-bound=10 mycounter3
echo "list counters in the cluster"
ls counters19.5.3. Protobuf schema
Register Protobuf schema to query values in caches.
Protobuf schema (.proto files) provide metadata about custom entities and controls field indexing.
echo "creating schema..."
schema --upload=person.proto person.proto
schema --upload=book.proto book.proto
schema --upload=author.proto book.proto
echo "list Protobuf schema"
ls schemas19.5.4. Tasks
Upload tasks that implement org.infinispan.tasks.ServerTask or scripts that are compatible with the javax.script scripting API.
echo "creating tasks..."
task upload --file=/etc/batch/myfirstscript.js myfirstscript
task upload --file=/etc/batch/mysecondscript.js mysecondscript
task upload --file=/etc/batch/mythirdscript.js mythirdscript
echo "list tasks"
ls tasks20. Backing up and restoring Infinispan clusters
Infinispan Operator lets you back up and restore Infinispan cluster state for disaster recovery and to migrate Infinispan resources between clusters.
20.1. Backup and Restore CRs
Backup and Restore CRs save in-memory data at runtime so you can easily recreate Infinispan clusters.
Applying a Backup or Restore CR creates a new pod that joins the Infinispan cluster as a zero-capacity member, which means it does not require cluster rebalancing or state transfer to join.
For backup operations, the pod iterates over cache entries and other resources and creates an archive, a .zip file, in the /opt/infinispan/backups directory on the persistent volume (PV).
|
Performing backups does not significantly impact performance because the other pods in the Infinispan cluster only need to respond to the backup pod as it iterates over cache entries. |
For restore operations, the pod retrieves Infinispan resources from the archive on the PV and applies them to the Infinispan cluster.
When either the backup or restore operation completes, the pod leaves the cluster and is terminated.
Infinispan Operator does not reconcile Backup and Restore CRs which mean that backup and restore operations are "one-time" events.
Modifying an existing Backup or Restore CR instance does not perform an operation or have any effect.
If you want to update .spec fields, you must create a new instance of the Backup or Restore CR.
20.2. Backing up Infinispan clusters
Create a backup file that stores Infinispan cluster state to a persistent volume.
-
Create an
InfinispanCR withspec.service.type: DataGrid. -
Ensure there are no active client connections to the Infinispan cluster.
Infinispan backups do not provide snapshot isolation and data modifications are not written to the archive after the cache is backed up.
To archive the exact state of the cluster, you should always disconnect any clients before you back it up.
-
Name the
BackupCR with themetadata.namefield. -
Specify the Infinispan cluster to backup with the
spec.clusterfield. -
Configure the persistent volume claim (PVC) that adds the backup archive to the persistent volume (PV) with the
spec.volume.storageandspec.volume.storage.storageClassNamefields.apiVersion: infinispan.org/v2alpha1 kind: Backup metadata: name: my-backup spec: cluster: source-cluster volume: storage: 1Gi storageClassName: my-storage-class -
Optionally include
spec.resourcesfields to specify which Infinispan resources you want to back up.If you do not include any
spec.resourcesfields, theBackupCR creates an archive that contains all Infinispan resources. If you do specifyspec.resourcesfields, theBackupCR creates an archive that contains those resources only.spec: ... resources: templates: - distributed-sync-prod - distributed-sync-dev caches: - cache-one - cache-two counters: - counter-name protoSchemas: - authors.proto - books.proto tasks: - wordStream.jsYou can also use the
*wildcard character as in the following example:spec: ... resources: caches: - "*" protoSchemas: - "*" -
Apply your
BackupCR.kubectl apply -f my-backup.yaml
-
Check that the
status.phasefield has a status ofSucceededin theBackupCR and that Infinispan logs have the following message:ISPN005044: Backup file created 'my-backup.zip' -
Run the following command to check that the backup is successfully created:
kubectl describe Backup my-backup -n namespace
20.3. Restoring Infinispan clusters
Restore Infinispan cluster state from a backup archive.
-
Create a
BackupCR on a source cluster. -
Create a target Infinispan cluster of Data Grid Service pods.
If you restore an existing cache, the operation overwrites the data in the cache but not the cache configuration.
For example, you back up a distributed cache named
mycacheon the source cluster. You then restoremycacheon a target cluster where it already exists as a replicated cache. In this case, the data from the source cluster is restored andmycachecontinues to have a replicated configuration on the target cluster. -
Ensure there are no active client connections to the target Infinispan cluster you want to restore.
Cache entries that you restore from a backup can overwrite more recent cache entries.
For example, a client performs acache.put(k=2)operation and you then restore a backup that containsk=1.
-
Name the
RestoreCR with themetadata.namefield. -
Specify a
BackupCR to use with thespec.backupfield. -
Specify the Infinispan cluster to restore with the
spec.clusterfield.apiVersion: infinispan.org/v2alpha1 kind: Restore metadata: name: my-restore spec: backup: my-backup cluster: target-cluster -
Optionally add the
spec.resourcesfield to restore specific resources only.spec: ... resources: templates: - distributed-sync-prod - distributed-sync-dev caches: - cache-one - cache-two counters: - counter-name protoSchemas: - authors.proto - books.proto tasks: - wordStream.js -
Apply your
RestoreCR.kubectl apply -f my-restore.yaml
-
Check that the
status.phasefield has a status ofSucceededin theRestoreCR and that Infinispan logs have the following message:ISPN005045: Restore 'my-backup' complete
You should then open the Infinispan Console or establish a CLI connection to verify data and Infinispan resources are restored as expected.
20.4. Backup and restore status
Backup and Restore CRs include a status.phase field that provides the status for each phase of the operation.
| Status | Description |
|---|---|
|
The system has accepted the request and the controller is preparing the underlying resources to create the pod. |
|
The controller has prepared all underlying resources successfully. |
|
The pod is created and the operation is in progress on the Infinispan cluster. |
|
The operation has completed successfully on the Infinispan cluster and the pod is terminated. |
|
The operation did not successfully complete and the pod is terminated. |
|
The controller cannot obtain the status of the pod or determine the state of the operation. This condition typically indicates a temporary communication error with the pod. |
20.4.1. Handling failed backup and restore operations
If the status.phase field of the Backup or Restore CR is Failed, you should examine pod logs to determine the root cause before you attempt the operation again.
-
Examine the logs for the pod that performed the failed operation.
Pods are terminated but remain available until you delete the
BackuporRestoreCR.kubectl logs <backup|restore_pod_name> -
Resolve any error conditions or other causes of failure as indicated by the pod logs.
-
Create a new instance of the
BackuporRestoreCR and attempt the operation again.
21. Deploying custom code to Infinispan
Add custom code, such as scripts and event listeners, to your Infinispan clusters.
Before you can deploy custom code to Infinispan clusters, you need to make it available. To do this you can copy artifacts from a persistent volume (PV), download artifacts from an HTTP or FTP server, or use both methods.
21.1. Copying code artifacts to Infinispan clusters
Adding your artifacts to a persistent volume (PV) and then copy them to Infinispan pods.
This procedure explains how to use a temporary pod that mounts a persistent volume claim (PVC) that:
-
Lets you add code artifacts to the PV (perform a write operation).
-
Allows Infinispan pods to load code artifacts from the PV (perform a read operation).
To perform these read and write operations, you need certain PV access modes. However, support for different PVC access modes is platform dependent.
It is beyond the scope of this document to provide instructions for creating PVCs with different platforms.
For simplicity, the following procedure shows a PVC with the ReadWriteMany access mode.
In some cases only the ReadOnlyMany or ReadWriteOnce access modes are available.
You can use a combination of those access modes by reclaiming and reusing PVCs with the same spec.volumeName.
|
Using |
-
Change to the namespace for your Infinispan cluster.
kubectl config set-context --current --namespace=ispn-namespace -
Create a PVC for your custom code artifacts, for example:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: datagrid-libs spec: accessModes: - ReadWriteMany resources: requests: storage: 100Mi -
Apply your PVC.
kubectl apply -f datagrid-libs.yaml -
Create a pod that mounts the PVC, for example:
apiVersion: v1 kind: Pod metadata: name: datagrid-libs-pod spec: securityContext: fsGroup: 2000 volumes: - name: lib-pv-storage persistentVolumeClaim: claimName: datagrid-libs containers: - name: lib-pv-container image: quay.io/infinispan/server:16.2.1 volumeMounts: - mountPath: /tmp/libs name: lib-pv-storage -
Add the pod to the Infinispan namespace and wait for it to be ready.
kubectl apply -f datagrid-libs-pod.yaml kubectl wait --for=condition=ready --timeout=2m pod/datagrid-libs-pod -
Copy your code artifacts to the pod so that they are loaded into the PVC.
For example to copy code artifacts from a local
libsdirectory, do the following:kubectl cp --no-preserve=true libs datagrid-libs-pod:/tmp/ -
Delete the pod.
kubectl delete pod datagrid-libs-podSpecify the persistent volume with
spec.dependencies.volumeClaimNamein yourInfinispanCR and then apply the changes.apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 2 dependencies: volumeClaimName: datagrid-libs service: type: DataGrid
|
If you update your custom code on the persistent volume, you must restart the Infinispan cluster so it can load the changes. |
21.2. Downloading code artifacts
Add your artifacts to an HTTP or FTP server so that Infinispan Operator downloads them to the /opt/infinispan/server/lib directory on each Infinispan node.
When downloading files, Infinispan Operator can automatically detect the file type.
Infinispan Operator also extracts archived files, such as zip or tgz, to the filesystem after the download completes.
You can also download Maven artifacts using the groupId:artifactId:version format, for example org.postgresql:postgresql:42.3.1.
|
Each time Infinispan Operator creates a Infinispan node it downloads the artifacts to the node. |
-
Host your code artifacts on an HTTP or FTP server or publish them to a maven repository.
-
Add the
spec.dependencies.artifactsfield to yourInfinispanCR. -
Do one of the following:
-
Specify the location of the file to download via
HTTPorFTPas the value of thespec.dependencies.artifacts.urlfield. -
Provide the Maven artifact to download with the
groupId:artifactId:versionformat as the value of thespec.dependencies.artifacts.mavenfield.
-
-
Optionally specify a checksum to verify the integrity of the download with the
spec.dependencies.artifacts.hashfield.The
hashfield requires a value is in the format of<algorithm>:<checksum>where<algorithm>issha1|sha224|sha256|sha384|sha512|md5.apiVersion: infinispan.org/v1 kind: Infinispan metadata: name: infinispan spec: replicas: 2 dependencies: artifacts: - url: http://example.com:8080/path hash: sha256:596408848b56b5a23096baa110cd8b633c9a9aef2edd6b38943ade5b4edcd686 service: type: DataGrid -
Apply the changes.
22. Establishing remote client connections
Connect to Infinispan clusters from the Infinispan Console, Command Line Interface (CLI), and remote clients.
22.1. Client connection details
Client connections to Infinispan require the following information:
-
Hostname
-
Port
-
Authentication credentials, if required
-
TLS certificate, if you use encryption
The hostname you use depends on whether clients are running on the same Kubernetes cluster as Infinispan.
Client applications running on the same Kubernetes cluster use the internal service name for the Infinispan cluster.
metadata:
name: infinispanClient applications running on a different Kubernetes, or outside Kubernetes, use a hostname that depends on how Infinispan is exposed on the network.
A LoadBalancer service uses the URL for the load balancer.
A NodePort service uses the node hostname.
An Red Hat OpenShift Route uses either a custom hostname that you define or a hostname that the system generates.
Client connections on Kubernetes and a through LoadBalancer service use port 11222.
NodePort services use a port in the range of 30000 to 60000.
Routes use either port 80 (unencrypted) or 443 (encrypted).
22.2. Connecting to Infinispan clusters with remote shells
Start a remote shell session to Infinispan clusters and use the command line interface (CLI) to work with Infinispan resources and perform administrative operations.
-
Have
kubectl-infinispanon yourPATH. -
Have valid Infinispan credentials.
-
Run the
infinispan shellcommand to connect to your Infinispan cluster.kubectl infinispan shell <cluster_name>If you have access to authentication secrets and there is only one Infinispan user the
kubectl-infinispanplugin automatically detects your credentials and authenticates to Infinispan. If your deployment has multiple Infinispan credentials, specify a user with the--usernameargument and enter the corresponding password when prompted. -
Perform CLI operations as required.
Press the tab key or use the
--helpargument to view available options and help text. -
Use the
quitcommand to end the remote shell session.
22.3. Accessing Infinispan Console
Access the console to create caches, perform adminstrative operations, and monitor your Infinispan clusters.
-
Expose Infinispan on the network so you can access the console through a browser.
For example, configure aLoadBalancerservice or create aRoute.
-
Access the console from any browser at
$HOSTNAME:$PORT.Replace
$HOSTNAME:$PORTwith the network location where Infinispan is available.
The Infinispan Console should only be accessed via Kubernetes services or an OpenShift Route exposing port 11222.
|
22.4. Hot Rod clients
Hot Rod is a binary TCP protocol that Infinispan provides for high-performance data transfer capabilities with remote clients.
Client intelligence
The Hot Rod protocol includes a mechanism that provides clients with an up-to-date view of the cache topology. Client intelligence improves performance by reducing the number of network hops for read and write operations.
Clients running in the same Kubernetes cluster can access internal IP addresses for Infinispan pods so you can use any client intelligence.
HASH_DISTRIBUTION_AWARE is the default intelligence mechanism and enables clients to route requests to primary owners, which provides the best performance for Hot Rod clients.
Clients running on a different Kubernetes, or outside Kubernetes, can access Infinispan by using a LoadBalancer, NodePort, or OpenShift Route.
|
Hot Rod client connections via Kubernetes For unencrypted Hot Rod client connections, you must use a |
Hot Rod clients must use BASIC intelligence in the following situations:
-
Connecting to Infinispan through a
LoadBalancerservice, aNodePortservice, or an OpenShiftRoute. -
Failing over to a different Kubernetes cluster when using cross-site replication.
Kubernetes cluster administrators can define network policies that restrict traffic to Infinispan.
In some cases network isolation policies can require you to use BASIC intelligence even when clients are running in the same Kubernetes cluster but a different namespace.
22.4.1. Hot Rod client configuration API
You can programmatically configure Hot Rod client connections with the ConfigurationBuilder interface.
|
Replace |
On Kubernetes
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
import org.infinispan.client.hotrod.configuration.SaslQop;
import org.infinispan.client.hotrod.impl.ConfigurationProperties;
...
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.addServer()
.host("$HOSTNAME")
.port(ConfigurationProperties.DEFAULT_HOTROD_PORT)
.security().authentication()
.username("username")
.password("changeme")
.realm("default")
.saslQop(SaslQop.AUTH)
.saslMechanism("SCRAM-SHA-512")
.ssl()
.sniHostName("$SERVICE_HOSTNAME")
.trustStoreFileName("/var/run/secrets/kubernetes.io/serviceaccount/service-ca.crt")
.trustStoreType("pem");# Connection
infinispan.client.hotrod.server_list=$HOSTNAME:$PORT
# Authentication
infinispan.client.hotrod.use_auth=true
infinispan.client.hotrod.auth_username=developer
infinispan.client.hotrod.auth_password=$PASSWORD
infinispan.client.hotrod.auth_server_name=$CLUSTER_NAME
infinispan.client.hotrod.sasl_properties.javax.security.sasl.qop=auth
infinispan.client.hotrod.sasl_mechanism=SCRAM-SHA-512
# Encryption
infinispan.client.hotrod.sni_host_name=$SERVICE_HOSTNAME
infinispan.client.hotrod.trust_store_file_name=/var/run/secrets/kubernetes.io/serviceaccount/service-ca.crt
infinispan.client.hotrod.trust_store_type=pemOutside Kubernetes
import org.infinispan.client.hotrod.configuration.ClientIntelligence;
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
import org.infinispan.client.hotrod.configuration.SaslQop;
...
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.addServer()
.host("$HOSTNAME")
.port("$PORT")
.security().authentication()
.username("username")
.password("changeme")
.realm("default")
.saslQop(SaslQop.AUTH)
.saslMechanism("SCRAM-SHA-512")
.ssl()
.sniHostName("$SERVICE_HOSTNAME")
//Create a client trust store with tls.crt from your project.
.trustStoreFileName("/path/to/truststore.pkcs12")
.trustStorePassword("trust_store_password")
.trustStoreType("PCKS12");
builder.clientIntelligence(ClientIntelligence.BASIC);# Connection
infinispan.client.hotrod.server_list=$HOSTNAME:$PORT
# Client intelligence
infinispan.client.hotrod.client_intelligence=BASIC
# Authentication
infinispan.client.hotrod.use_auth=true
infinispan.client.hotrod.auth_username=developer
infinispan.client.hotrod.auth_password=$PASSWORD
infinispan.client.hotrod.auth_server_name=$CLUSTER_NAME
infinispan.client.hotrod.sasl_properties.javax.security.sasl.qop=auth
infinispan.client.hotrod.sasl_mechanism=SCRAM-SHA-512
# Encryption
infinispan.client.hotrod.sni_host_name=$SERVICE_HOSTNAME
# Create a client trust store with tls.crt from your project.
infinispan.client.hotrod.trust_store_file_name=/path/to/truststore.pkcs12
infinispan.client.hotrod.trust_store_password=trust_store_password
infinispan.client.hotrod.trust_store_type=PCKS1222.4.2. Configuring Hot Rod clients for certificate authentication
If you enable client certificate authentication, clients must present valid certificates when negotiating connections with Infinispan.
If you use the Validate strategy, you must configure clients with a keystore so they can present signed certificates.
You must also configure clients with Infinispan credentials and any suitable authentication mechanism.
If you use the Authenticate strategy, you must configure clients with a keystore that contains signed certificates and valid Infinispan credentials as part of the distinguished name (DN).
Hot Rod clients must also use the EXTERNAL authentication mechanism.
|
If you enable security authorization, you should assign the Common Name (CN) from the client certificate a role with the appropriate permissions. |
The following example shows a Hot Rod client configuration for client certificate authentication with the Authenticate strategy:
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
...
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.security()
.authentication()
.saslMechanism("EXTERNAL")
.ssl()
.keyStoreFileName("/path/to/keystore")
.keyStorePassword("keystorepassword".toCharArray())
.keyStoreType("PCKS12");22.4.3. Creating caches from Hot Rod clients
You can remotely create caches on Infinispan clusters running on Kubernetes with Hot Rod clients.
However, Infinispan recommends that you create caches using Infinispan Console, the CLI, or with Cache CRs instead of with Hot Rod clients.
Programmatically creating caches
The following example shows how to add cache configurations to the ConfigurationBuilder and then create them with the RemoteCacheManager:
import org.infinispan.client.hotrod.DefaultTemplate;
import org.infinispan.client.hotrod.RemoteCache;
import org.infinispan.client.hotrod.RemoteCacheManager;
...
builder.remoteCache("my-cache")
.templateName(DefaultTemplate.DIST_SYNC);
builder.remoteCache("another-cache")
.configuration("<infinispan><cache-container><distributed-cache name=\"another-cache\"><encoding media-type=\"application/x-protostream\"/></distributed-cache></cache-container></infinispan>");
try (RemoteCacheManager cacheManager = new RemoteCacheManager(builder.build())) {
// Get a remote cache that does not exist.
// Rather than return null, create the cache from a template.
RemoteCache<String, String> cache = cacheManager.getCache("my-cache");
// Store a value.
cache.put("hello", "world");
// Retrieve the value and print it.
System.out.printf("key = %s\n", cache.get("hello"));This example shows how to create a cache named CacheWithXMLConfiguration using the XMLStringConfiguration() method to pass the cache configuration as XML:
import org.infinispan.client.hotrod.RemoteCacheManager;
import org.infinispan.commons.configuration.XMLStringConfiguration;
...
private void createCacheWithXMLConfiguration() {
String cacheName = "CacheWithXMLConfiguration";
String xml = String.format("<distributed-cache name=\"%s\">" +
"<encoding media-type=\"application/x-protostream\"/>" +
"<locking isolation=\"READ_COMMITTED\"/>" +
"<transaction mode=\"NON_XA\"/>" +
"<expiration lifespan=\"60000\" interval=\"20000\"/>" +
"</distributed-cache>"
, cacheName);
manager.administration().getOrCreateCache(cacheName, new XMLStringConfiguration(xml));
System.out.println("Cache with configuration exists or is created.");
}Using Hot Rod client properties
When you invoke cacheManager.getCache() calls for named caches that do not exist, Infinispan creates them from the Hot Rod client properties instead of returning null.
Add cache configuration to hotrod-client.properties as in the following example:
# Add cache configuration
infinispan.client.hotrod.cache.my-cache.configuration=<infinispan><cache-container><distributed-cache name=\"my-cache\"/></cache-container></infinispan>
infinispan.client.hotrod.cache.another-cache.configuration_uri=file:/path/to/configuration.xml22.5. Accessing the REST API
Infinispan provides a RESTful interface that you can interact with using HTTP clients.
-
Expose Infinispan on the network so you can access the REST API.
For example, configure aLoadBalancerservice or create aRoute.
-
Access the REST API with any HTTP client at
$HOSTNAME:$PORT/rest/v2.Replace
$HOSTNAME:$PORTwith the network location where Infinispan listens for client connections.