Map/Reduce improvements in Infinispan 5.2.0ALPHA2

As our MapReduce implementation grew out of the proof of concept phase (and especially after our users had already production tested it), we needed to remove the most prominent impediment to an industrial grade MapReduce solution that we strive for: distributing reduce phase execution.
Reduce phase prior to the Infinispan 5.2 release was done on a single Infinispan master task node. Therefore, the size of map reduce problems we could support (data size wise) was effectively shrunk to a working memory of a single Infinispan node. Starting with the Infinispan 5.2 release, we have removed this limitation, and reduce phase execution is distributed across the cluster as well. Of course, users still have an option to use MapReduceTask the old way, and we even recommend that particular approach for smaller sized input tasks. We have achieved distribution of reduce phase by relying on Infinispan’s consistent hashing and DeltaAware cache insertion. Here is how we distributed reduce phase execution:
Map phase
MapReduceTask, as it currently does, will hash task input keys and group them by execution node N they are hashed to*. After key node mapping, MapReduceTask sends map function and input keys to each node N. Map function is invoked using given keys and locally loaded corresponding values.
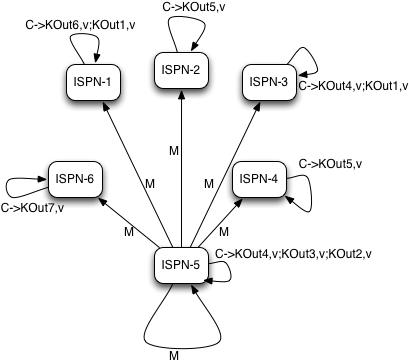 |
|---|
Map and Combine phase |
Results are collected with an Infinispan supplied Collector, and combine phase is initiated. A Combiner, if specified, takes KOut keys and immediately invokes reduce phase on keys. The result of mapping phase executed on each node is KOut/VOut map. There will be one resulting map per execution node N per launched MapReduceTask.
Intermediate KOut/VOut migration phase **
In order to proceed with reduce phase, all intermediate keys and values need to be grouped by intermediate KOut keys. More specifically, as map phases around the cluster can produce identical intermediate keys, all those identical intermediate keys and their values need to be grouped before reduce is executed on any particular intermediate key.
Therefore at the end of combine phase, instead of returning map with intermediate keys and values to the master task node, we instead hash each intermediate key KOut and migrate it with its VOut values to Infinispan node where keys KOut are hashed to. We achieve this using a temporary DIST cache and underlying consistent hashing mechanism. Using DeltaAware cache insertion we effectively collect all VOut values under each KOut for all executed map functions across the cluster.
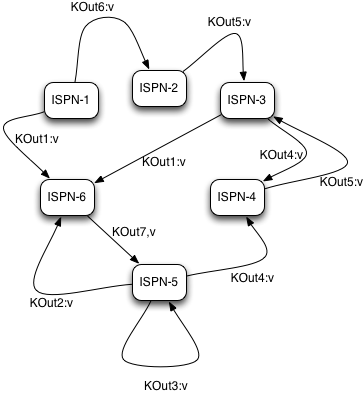 |
|---|
Intermediate KOut/VOut grouping phase |
At this point, map and combine phase have finished its execution; list of KOut keys is returned to a master node and its initiating MapReduceTask. We do not return VOut values as we do not need them at master task node. MapReduceTask is ready to start with reduce phase.
Reduce phase
Reduce phase is easy to accomplish now as Infinispan’s consistent hashing already finished all the hard lifting for us. To complete reduce phase, MapReduceTask groups KOut keys by execution node N they are hashed to. For each node N and its grouped input KOut keys, MapReduceTask sends a reduce command to a node N where KOut keys are hashed. Once reduce command arrives on target execution node, it looks up temporary cache belonging to MapReduce task - and for each KOut key, grabs a list of VOut values, wraps it with an Iterator and invokes reduce on it.
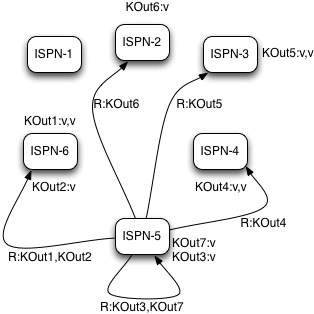 |
|---|
Reduce phase |
A result of each reduce is a map where each key is KOut and value is VOut. Each Infinispan execution node N returns one map with KOut/VOut result values. As all initiated reduce commands return to a calling node, MapReduceTask simply combines all resulting maps into map M and returns M as a result of MapReduceTask.
Distributed reduce phase is turned on by using a MapReduceTask constructor specifying cache to use as input data for the task and boolean parameter distributeReducePhase set to true. Map/Reduce API javadoc and demos are included in distribution.
Moving forward * * For Infinispan 5.2.0 final release we want to make sure the execution of intermediate migration key/value phase is as effective as possible and proven to be lock free for large input tasks as it was in our functional tests. We are also, as always, looking forward to your feedback and suggestions - especially if you have large data input sets ready for our latest MapReduceTask.
Cheers, Vladimir
*If no keys are specified, entire cache key set will be used as in input.
Get it, Use it, Ask us!
We’re hard at work on new features, improvements and fixes, so watch this space for more announcements!Please, download and test the latest release.
The source code is hosted on GitHub. If you need to report a bug or request a new feature, look for a similar one on our GitHub issues tracker. If you don’t find any, create a new issue.
If you have questions, are experiencing a bug or want advice on using Infinispan, you can use GitHub discussions. We will do our best to answer you as soon as we can.
The Infinispan community uses Zulip for real-time communications. Join us using either a web-browser or a dedicated application on the Infinispan chat.

