Infinispan 12.0.0.Final

Infinispan 12.0.0.Final
Dear Infinispan community,
we hope you, your families and colleagues are doing well in these trying times. We’ve been working hard over the last few months to bring you a brand-new release of Infinispan. Infinispan 12, aptly codenamed Lockdown comes loaded with a number of notable features as well as the usual slew of fixes and cleanups.
Indexing and Search
Our good friends over at Hibernate Search have been working hard on delivering an awesome new release and have also helped us integrate it in Infinispan. This is not just an upgrade: we have taken the opportunity to evolve our indexing configuration:
-
Upgraded to Hibernate Search 6, that brings support for Lucene 8 indexes
-
Better indexing performance out of the box
-
New statistics API, covering indexed, non-indexed and hybrid queries
-
Introduced strong typed indexing configuration that replaces the string key/value properties.
Head over to the much improved documentation.
Configuration
We introduced a couple of improvements to the configuration API:
-
Runtime creation of templates: the remote APIs now allow creating configuration templates.
-
Configuration Fragments: when creating caches and templates via the remote APIs, you no longer need to wrap their configuration in the
<infinispan><cache-container>…</cache-container></infinispan>elements, but you can simply use the cache definition directly, e.g.:<distributed-cache name=”mycache”/>
Marshalling
-
A new
@ProtoAdapterannotation has been added to ProtoStream for generating.protofiles and marshallers for third party classes -
SerializationContextInitializerimplementations are automatically discovered and configured via Java ServiceLoader. -
User types are now fully isolated from Infinispan internal context.
Cross Site Replication
Our work on improving asynchronous cross-site replication continues with the following improvements:
-
a new SPI for merging conflicting values: if two (or more) write operations happen simultaneously in different sites, the conflict is detected and the SPI is invoked to merge the values. Merge policies determine which action will be taken in case of conflict between updates of different sites. Some predefined merge policies can be found here.
-
Exponential back-off added for network failures: ff the network between the sites disconnects, Infinispan will retry less frequently before giving up. It helps reduce the CPU utilization.
-
Automatic disconnection if the cache configuration does not exist or is incorrect: if Infinispan tries to backup to a remote site and the remote site doesn’t have the cache defined, the remote site is automatically taken offline.
-
Internal code improvements: the code is now non-blocking to reduce the CPU usage.
See cross-site replication documentation for more information.
Server
Backup/Restore
A backup archive, that contains container resources (caches, cache templates, counters, Protobuf schemas, server tasks) currently stored in the cache manager, can now be created. The backup archive can then be used to restore Infinispan clusters content after a restart or migration. This feature is exposed via the REST endpoint, however backups can also be created via the Infinispan CLI or with Backup/Restore CRs when using the operator.
Credential Stores
To protect sensitive text strings, such as passwords, in the server configuration, you can add them to a credential keystore and reference them. You can then configure the server to decrypt passwords for establishing connections with services such as databases or LDAP directories.
<security>
<credential-stores>
<credential-store name="credentials" path="credentials.pfx">
<clear-text-credential clear-text="secret"/>
</credential-store>
</credential-stores>
</security>
<data-sources>
<data-source name="postgres" jndi-name="jdbc/postgres">
<connection-factory driver="org.postgresql.Driver"
username="dbuser"
url="jdbc:postgresql:database">
<credential-reference store="credentials" alias="dbpassword"/>
</connection-factory>
</data-source>
</data-sources>
Multiple endpoints
The server now allows definining multiple single-port endpoints, each one mapped to a separate socket binding and with its own security realm. This is useful if you want to expose an admin endpoint on an internal, management-only network as well as an endpoint for application uses.
Optional authentication for metrics endpoint
Previously, the Prometheus-compatible metrics endpoint, published at http://infinispan:11222/metrics, used the same security semantics as the single port endpoint. It’s now possible to allow anonymous connections to this endpoint, to simplify integration with your Prometheus scraper.
Custom server paths
It’s now possible to start the server by overriding each of the paths individually.
server.sh -Dinfinispan.server.config.path=... \
-Dinfinispan.server.log.path=... \
-Dinfinispan.server.data.path=... \
-Dinfinispan.server.lib.path=...
Moreover, the server library path now supports multiple directories which will be scanned recursively for both JARs and bare resources such as property files.
Near caches with bloom filter
The remote client has near caches that allow for values retrieved from the remote server to be cached locally on the client. This works great for workloads that are primarily read only. However, to provide consistency we have to listen to remote modification/removal events from the server, which can make work loads with a lot of writes not scale. As such we are introducing bloom filter assisted notifications that will reduce the amount of modification/removal events received from the server and thus would increase the scalability of write heavy applications using the near cache. This needs to be enabled in addition to near caching, which can be done via the client configuration xml or programmatic classes.
Distributed tracing
You can now integrate Infinispan’s server with OpenTracing to perform distributed tracing.
-
Only track Hot Rod cache write requests (i.e. no counters, multimap etc.)
-
Select the OpenTracing implementation via the
infinispan.opentracing.factory.classandinfinispan.opentracing.factory.methodsystem properties. -
An OpenTracing implementation (is not included: instead it must be added to the server/lib directory (for example: the Jaeger OpenTracing implementation).
CLI
Benchmark tool
The CLI now includes a small convenience benchmark tool which allows you to measure latency and throughput of an Infinispan server using a specific configuration. You can use this when sizing resources based on your requirements.
Native build
Kubernetes CLI
When installing the native CLI as kubectl-infinispan, the CLI gains additional functionality to control the Infinispan operator, simplifying many operations. This includes the ability to install and uninstall the operator, create and delete Infinispan clusters and obtain information about various resources.
Configuration improvements
The CLI can persist some configuration properties which you wish to apply to all your sessions:
-
autoconnect-url: Specifies the URL to which the CLI automatically connects on startup. -
autoexec: Specifies the path of a CLI batch file to execute on startup. -
truststore: Specifies the path of a truststore to validate server certificates. -
trustall: Specifies whether to trust all server certificates without supplying a trust store.
Console
This version includes a new version of the web console, including mainly fixes, but also the ability to finally view cache entries and their details:
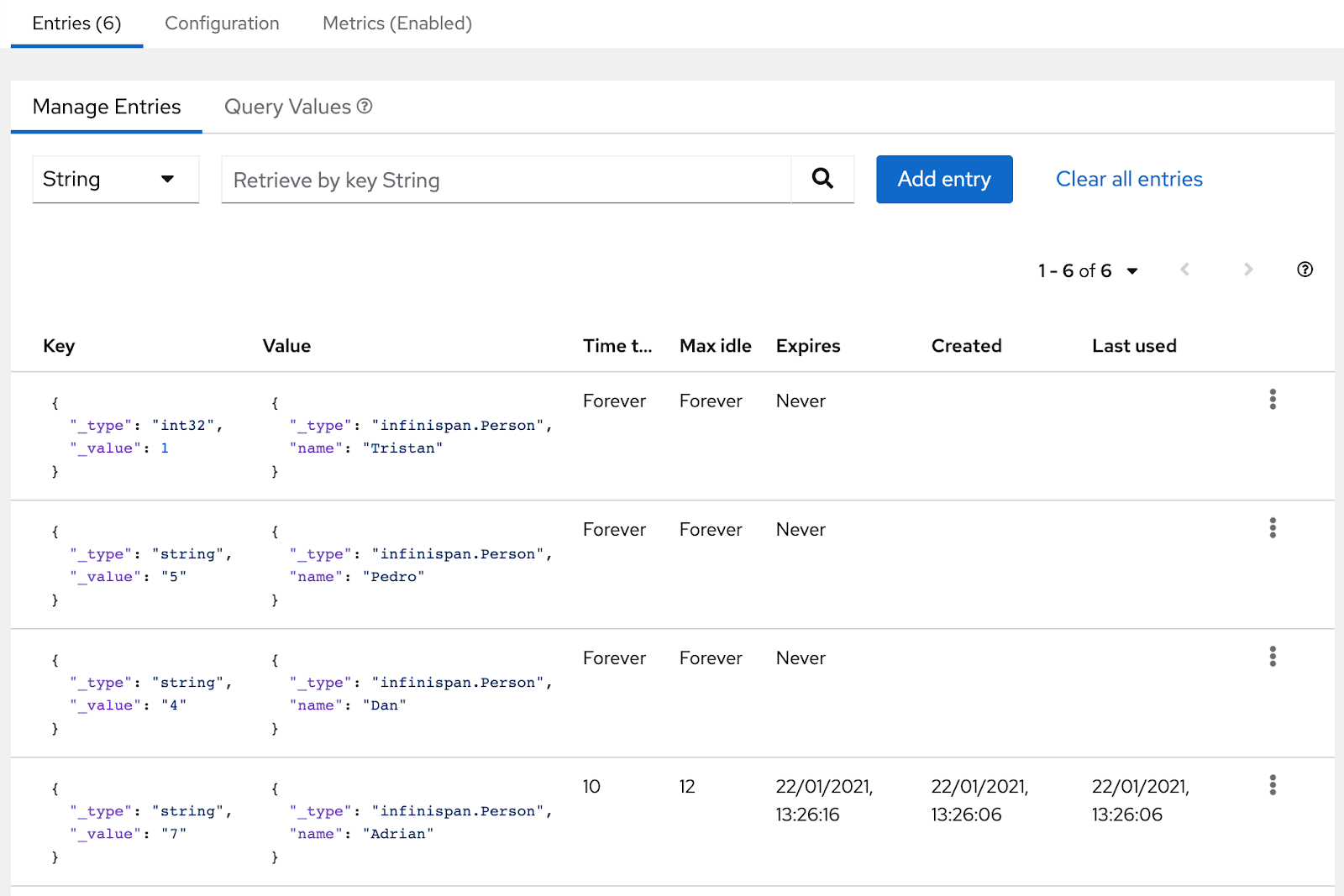
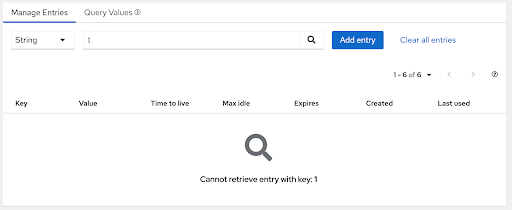
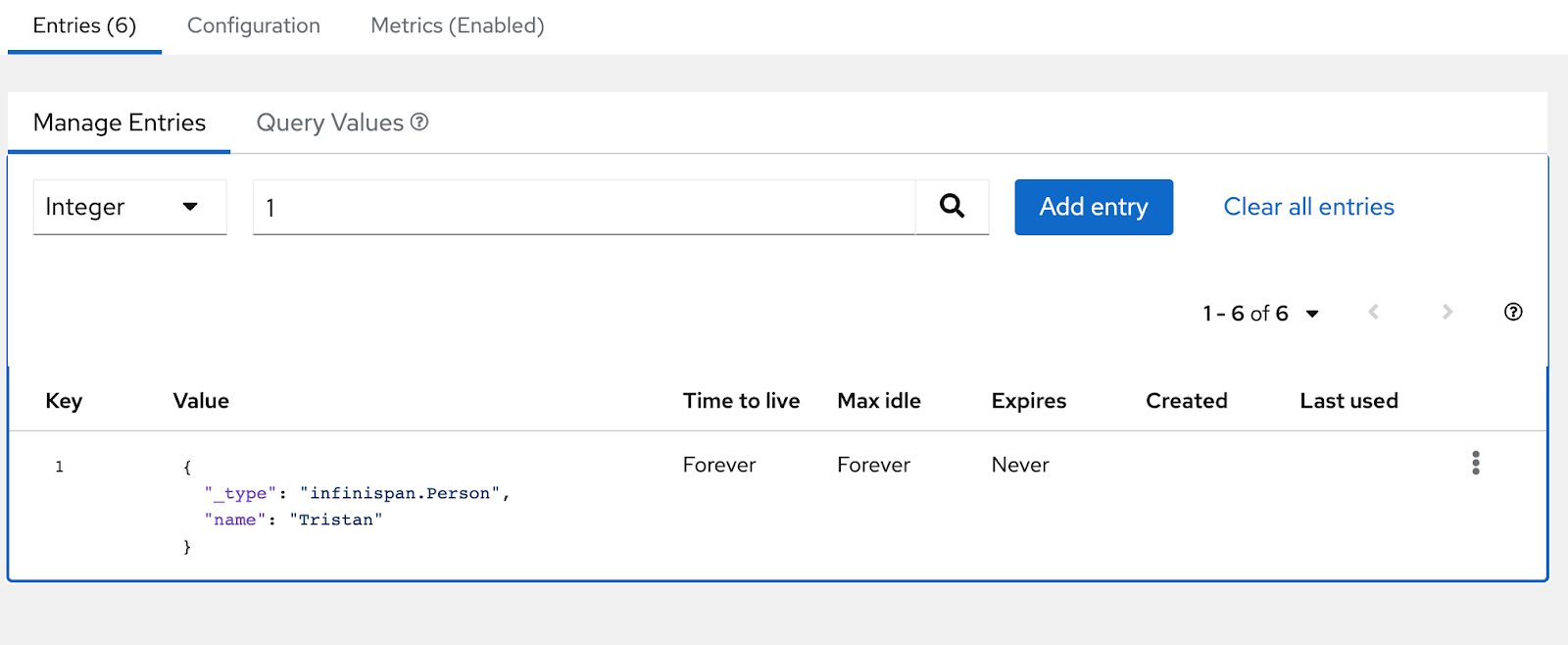
Cloud Events integration
The Infinispan CloudEvents integration is a new experimental module which converts Infinispan events to CloudEvents events and sends them to a Kafka topic in structured mode. This allows Infinispan be further used as a Knative source. There are two broad kinds of events:
-
Cache entry modifications: created, updated, removed, expired
-
Audit events: user login, access denied
Images
-
A natively compiled version of the CLI is now available as a container via the infinispan/cli image.
-
The server images have also added support for configuring zero-capacity as well as allowing JGroups properties to be overridden at runtime.
Operator
The operator continues to improve and evolve so that installing and managing Infinispan clusters on Kubernetes/OpenShift is a breeze:
-
Data Backup and Restore are available via CR.
-
Cross site improvements:
-
Access to remote cluster k8s API is no longer mandatory.
-
Manual configuration.
-
Namespaces can be different.
-
Multinamespace and global installation mode.
-
-
TLS can be disabled via CR configuration, even in environments where certificate management is built-in (e.g. OpenShift).
-
Support for the Quarkus native Infinispan image.
-
Anti-affinity configuration.
Documentation
-
Documentation for configuring cluster transport was overhauled in Infinispan 12. We made numerous changes, based on direct feedback from the community, to our JGroups content. We also added details on how to configure SYM_ENCRYPT and ASYM_ENCRYPT protocols, which were previously available only in the JGroups documentation set.
-
You can find new chapters on Configuring Cluster Transport in the Server Guide and Embedding Infinispan Guide. The details for JGroups encryption are also available in the guide for Securing Infinispan.
-
Off-Heap configuration has often been misunderstood and we’ve had several questions about what it actually means to store data in native memory outside the JVM heap. To address these questions, and spell out some of the benefits and potential downsides of using off-heap storage, we’ve added some conceptual information to our Configuration Guide.
-
Our documentation on Configuring Infinispan to Marshall Java Objects is also updated in an effort to improve clarity and be more task-oriented.
-
Along with all the refactoring and improvements that have been made to the Search API, we’ve made some improvements to our documentation for Querying Values in Infinispan Caches.
-
Lastly, we noticed that the documentation for Clustered Locks was a little out of date and potentially confusing so we spent time to rework that content to make sure it’s accurate.
As always, the Infinispan team hope you find the documentation useful and complete. We’d love to hear from you and really value feedback from our community. If you think something is missing from the docs or spot a correction, please get in touch and we’ll get on it straight away.
Other
-
We have decided to adopt Conscious language in Infinispan, both in our code and in our documentation. For example, Infinispan’s way of configuring which classes are allowed to be marshalled/unmarshalled is now called allow list. If you find other places where we are using inappropriate terms, please don’t hesitate to contact us.
-
We’ve added some UI writing guidelines and Infinispan terminology to our Contributor’s Guide in an effort to create a consistent user experience.
-
As you may have noticed, our website has gone through some extensive redesign.
-
Bye bye OSGI (it even rhymes !): we’ve removed support for OSGi since it was quite a maintenance burden.
Release notes and upgrading
You can look at the detailed release notes to see what has changed since CR1. If you are upgrading from a previous version of Infinispan, please checkout our Upgrading guide.
What’s next ?
Our next release, 12.1, will be a quick one, mostly focused on polishing and small API improvemnets, before we move on to bigger things. As usual, look out for blog postings about upcoming highlights. If you’d like to contribute, just get in touch.
Get it, Use it, Ask us!
We’re hard at work on new features, improvements and fixes, so watch this space for more announcements!Please, download and test the latest release.
The source code is hosted on GitHub. If you need to report a bug or request a new feature, look for a similar one on our GitHub issues tracker. If you don’t find any, create a new issue.
If you have questions, are experiencing a bug or want advice on using Infinispan, you can use GitHub discussions. We will do our best to answer you as soon as we can.
The Infinispan community uses Zulip for real-time communications. Join us using either a web-browser or a dedicated application on the Infinispan chat.
Tristan Tarrant
Tristan is the Infinispan lead. He's been a passionate open-source advocate and contributor for over three decades.

