Tuesday, 12 May 2009
Implementing a performant, thread-safe ordered data container
To achieve efficient ordering of entries in the DataContainer interface for configurations that support eviction, there was a need for a linked HashMap implementation that was thread-safe and performant. Below, I specifically discuss the implementations of the FIFODataContainer and LRUDataContainer in Infinispan 4.0.x. Wherever this document references FIFODataContainer, this also applies to LRUDataContainer - which extends FIFODataContainer. The only difference is that LRUDataContainer updates links whenever an entry is visited as well as added.
After analysing and considering a few different approaches, the one I settled on is a subset of the algorithms described by H. Sundell and P. Tsigas in their 2008 paper titled Lock-Free Deques and Doubly Linked Lists, combined with the approach used by Sun’s JDK6 for reference marking in ConcurrentSkipListMap's implementation.
Reference marking? What’s that?
Compare-and-swap (CAS) is a common technique today for atomically updating a variable or a reference without the use of a mutual exclusion mechanism like a lock. But this only works when you modify a single memory location at a time, be it a reference or a primitive. Sometimes you need to atomically update two separate bits of information in a single go, such as a reference, as well as some information about that reference. Hence reference marking. In C, this is sometimes done by making use of the assumption that an entire word in memory is not needed to store a pointer to another memory location, and some bits of this word can be used to store additional flags via bitmasking. This allows for atomic updates of both the reference and this extra information using a single CAS operation.
This is possible in Java too using AtomicMarkableReference, but is usually considered overly complex, slow and space-inefficient. Instead, what we do is borrow a technique from ConcurrentSkipListMap and use an intermediate, delegating entry. While this adds a little more complexity in traversal (you need to be aware of the presence of these marker entries when traversing the linked list), this performs better than an AtomicMarkableReference.
In this specific implementation, the 'extra information' stored in a reference is the fact that the entry holding the reference is in the process of being deleted. It is a common problem with lock-free linked lists when you have concurrent insert and delete operations that the newly inserted entry gets deleted as well, since it attaches itself to the entry being concurrently deleted. When the entry to be removed marks its references, however, this makes other threads aware of the fact and cause CAS operations on the reference to fail and retry.
Performance
Aside from maintaining order of entries and being thread-safe, performance was one of the other goals. The target is to achieve constant-time performance - O(1) - for all operations on DataContainer.
The clhttp://3.bp.blogspot.com/_ca0W9t-Ryos/SgGwA2iw_vI/AAAAAAAAAKA/TpVMWo2Rq9U/s1600-h/FIFODataContainer.jpeg[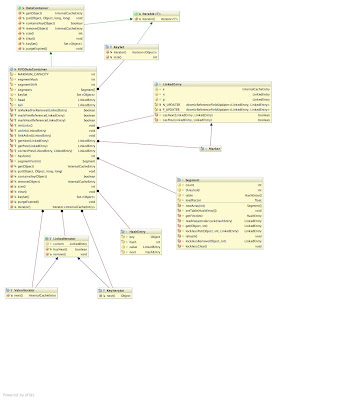 ]ass diagram (click to view in full-size) depicts the FIFODataContainer class. At its heart the FIFODataContainer mimics a JDK ConcurrentHashMap (CHM), making use of hashtable-like lockable segments. Unlike the segments in CHM, however, these segments are simpler as they support a much smaller set of operations.
]ass diagram (click to view in full-size) depicts the FIFODataContainer class. At its heart the FIFODataContainer mimics a JDK ConcurrentHashMap (CHM), making use of hashtable-like lockable segments. Unlike the segments in CHM, however, these segments are simpler as they support a much smaller set of operations.
Retrieving data from the container The use of segments allow for constant-time thread-safe get() and containsKey() operations. Iterators obtained from the DataContainer - which implements Iterable, and hence usable in for-each loops - and keySet() are immutable, thread-safe and efficient, using traversal of the linked list - making use of getNext() and getPrev() helpers. See below for details. Traversal is efficient and constant-time.
Updating the container When removing an entry, remove() locks the segment in question, removes the entry, and unlinks the entry. Both operations are thread-safe and constant-time. Locking the segment and removing the entry is pretty straightforward. Unlinking involves marking references, and then an attempt at CAS’ing next and previous references to bypass the removed entry. Order here is important - updates to the next reference needs to happen first, read on for more details as to why.
When performing a put(), the entry is created, segment locked and entry inserted into the segment. The entry is then inserted at the tail of the linked list. Again, both operations are thread-safe and constant-time. Linking at the tail involves careful CAS’ing of references on the new entry, the tail dummy entry and the former last entry in the list.
Maintaining a lock-free, concurrent doubly linked list It is important to note that the entries in this implementation are doubly linked. This is critical since, unlike the JDK’s ConcurrentSkipListMap, we use a hashtable to look up entries to be removed, to achieve constant time performance in lookup. Locating the parent entry to update a reference needs to be constant-time as well, and hence the need for a previous reference. Doubly-linked lists make things much trickier though, as there two references to update atomically (yes, that sounds wrong!)
Crucially, what we do not care about - and do not support - is reverse-order traversal. This means that we only really care about maintaining accuracy in the forward direction of the linked list, and treat the previous reference as an approximation to an entry somewhere behind the current entry. Previous references can then be corrected - using the correctPrev() helper method described below - to locate the precise entry behind the current entry. By placing greater importance on the forward direction of the list, this allows us to reliably CAS the forward reference even if the previous reference CAS fails. It is hence critical that whenever any references are updated, the next reference is CAS’d first, and only on this success the previous reference CAS is attempted. The same order applies with marking references. Also, it is important that any process that touches an entry that observes that the next pointer is marked but the previous pointer is not, attempts to mark the previous pointer before attempting any further steps.
The specific functions we need to expose, to support DataContainer operations, are:
void linkAtEnd(LinkedEntry entry);
void unlink(LinkedEntry entry);
LinkedEntry correctPrev(LinkedEntry suggestedPrev, LinkedEntry current);
LinkedEntry getNext(LinkedEntry current);
LinkedEntry getPrev(LinkedEntry current);These are exposed as protected final methods, usable by FIFODataContainer and its subclasses. The implementations themselves use a combination of CAS’s on a LinkedEntry’s next and previous pointers, marking references, and helper correction of previous pointers when using getNext() and getPrevious() to traverse the list. Note that it is important that only the last two methods are used when traversing rather than directly accessing a LinkedEntry’s references - since markers need to be stepped over and links corrected.
Please refer to Lock-Free Deques and Doubly Linked Lists for details of the algorithm steps.
Tags: algorithms eviction concurrency data structures