Wednesday, 07 February 2018
Data Container Changes Part 3
Just over a year ago we detailed some improvements to the data container, including the availability of Off Heap storage in part 2. There have been quite a few fixes for Off Heap especially around memory size estimations with Infinispan 9.2. There is also a brand new "eviction" strategy that has a bit of a twist.
Eviction Strategy Resurrected
Some of you may have remembered that Infinispan used to have an eviction strategy. This was originally used to decide what eviction algorithm was used, such as LRU or LIRS. This was removed when the new data container was introduced. Well… it is back again, but it will be used for a slightly different purpose.
The eviction strategy still has NONE & MANUAL which are exactly the same as before.
Remove strategy
There is a new REMOVE strategy that is configured by default if eviction size is greater than 0. This strategy essentially enables eviction and removes old entries as new ones are inserted.
Exception strategy
We have a brand new "eviction" strategy that provides new functionality. It is unique in that it doesn’t really evict, but rather prevent entries from being inserted. This is the EXCEPTION strategy which blocks new entries from being inserted (or updated if they exceed memory size) by throwing a ContainerFullException when the size is reached.
This strategy only works on transactional caches that always have 2 phase commit enabled. This can be useful if you want to always have only so many entries and to give priority to currently inserted entries. This strategy has better performance than REMOVE since it doesn’t have to bookkeep all entries to know what to remove as well.
Note this strategy works across all storage types: OBJECT, BINARY and OFFHEAP and works with both MEMORY and SIZE based "eviction types. This makes it just as flexible as the REMOVE eviction strategy and hope it finds some uses by people.
Off Heap Memory Size Allocations & Estimations
Before the off heap memory based eviction only counted the allocated memory chunks for the stored entries themselves. This unfortunately meant that the size estimate is a bit less than what it should have been. There are a few things that we improved since then, including reducing the overhead of our allocations. Note all of the below things require no configuration changes and users should just get the benefits.
Reduced per object overhead
Prior the overhead for immutable entries with eviction, Infinispan itself use to allocate 2 chunks of memory with one being 28 bytes and adding 8 bytes to the actual object. Now we only allocate an additional 16 bytes to the object memory block itself (saving the extra allocation and requiring less on the object) when using eviction. Due to memory allocation overhead this saves much more than the 20 bytes as the allocator also has its own overhead.
We also shaved off 4 bytes off of all entries if expiration was not used, meaning overhead for an immutable cache entry without eviction only requires 21 bytes of overhead from ISPN when using off heap (retained in the same allocation block).
Per allocation memory sizing estimations
Internally ISPN allocates a new chunk of memory for each object. This is done currently to leverage the underlying OS allocator to handle features such as fragmentation or compaction (if the allocator does so). Unfortunately this means that each object has its own overhead from the allocator. Thus we now take that into account when estimating the memory used by adding 8 bytes overhead and aligning to 16 bytes. This seems to be a pretty common way for allocators to work. If possible we could allow for tweaking these values, but they are hard coded currently.
Accounting for Address Count
As was mentioned in the prior blog post about off heap, we allocate a single block of memory to hold address counters for our lookups when using Off Heap. Unfortunately we didn’t account for that in the memory eviction count. We now account for that in the eviction mechanism, thus your memory eviction size must be greater than the address count rounded up to the nearest power of 2, multiplied by 8. What a mouthful…
Wrap up
Off heap has been overhauled quite a bit to try to reduce memory usage, fix bugs and more accurately estimate the memory used. We hope that along with the new eviction strategy are welcome additions to various applications.
Please make sure to contact us if you have any feedback, find any bugs or have any questions! You can get in contact with various places listed on our website.
Tags: off-heap eviction configuration
Friday, 25 September 2015
Memory based eviction
Eviction Today
Infinispan since its inception has supported a way to help users control how much memory the in memory cache entries consume in the JVM. This has always been limited to a number of entries. In the past users have had to estimate the average amount of bytes their entries used on the heap. With this average you can easily calculate how many entries could safely be stored in memory without running into issues. For users who have keys and values that are relatively similar this can work well. However when the case requires entries that vary in size this can be problematic and you end up calculating the average size based on the worse case.
Enter Memory Based Eviction
Infinispan 8 introduces memory based eviction counting. That is Infinispan will automatically keep track of how large the key, value and overhead if possible. It can use these values then to try to limit the number of entries instead to a memory count such as 1 Gigabyte.
Key/Value limitations
Unfortunately this is currently limited to only using keys and values stored as primitives, primitive wrappers (ie. Integer), java.lang.String(s) and any of the previously mentioned stored in an array. This means this feature cannot be used with any custom classes. If enough feedback is provided we could provide a SPI to allow the user to plug in their own counter for their own classes, but this is not planned currently.
There are a couple ways to easily get around this. One is to use storeAsBinary, which will store your keys and/or values as byte arrays for you automatically, satisfying this limitation. A second way is when you are using the client such as HotRod, in this case the data is stored in the serialized (byte[]) form. Note that compatibility mode will prevent this from occurring and you are unable to use these configurations together.
Eviction Type limitation
Due to the complexity of LIRS, memory based eviction is only supported with LRU at this time. See the types here. This could be enhanced at a later point, but is also not planned.
Supported JVMs
This was tested and written specifically for Oracle and OpenJDK JVMs. In testing these JVMs showed memory accuracy within 1% of desired value. Other JVMs may shown incorrect values.
The algorithm takes into account JVM options, such as compressed pointers and 32 bit JVM vs 64 bit JVM. Keep in mind this is only for the data container and doesn’t take into account additional overhead such as created threads or other runtime objects.
Other JVMs are not handled such as the IBM JVM which was briefly tested and showed incorrect numbers greater than 10% of the desired amount. Support for other JVMs can be added later as interest is shown for them.
Closing Notes
I hope this feature helps people to better handle their memory constraints while using Infinispan! Let us know if you have any feedback or concerns.
Cheers!
- Will
Tags: eviction memory
Thursday, 19 March 2015
Eviction Improvements in Infinispan 7.2.0.Beta1
As many of you are most likely aware Infinispan provides a way to limit how many entries are stored in a single node’s memory at a given time. This is configurable via the eviction element in xml or EvictionConfiguraitonBuilder through the programmatic configuration.
In 7.2.0.Beta1 we have made some internal changes to our internal eviction support. This mostly entailed moving our implementation to the new ConcurrentHashMap that was updated for Java 8. This provides for a few new benefits and behaviors.
Long Size Support
Previously our eviction entry amount was limited to the maximum value of an int (2^31) and was always rounded up to the nearest power of 2 (ie. 100 would be changed to 128 which is 2^7).
With the new changes you can store up to a long worth of entries and it is not constrained to a power of 2. Unfortunately Beta1 does not contain the changes to allow for a long to be configured yet, but this should be fixed before 7.2.0.Final is done.
Memory wide eviction size
The old bounded map performed it’s eviction based on evicting elements stored in the same segment. This could cause the map to evict entries before it actually hit the maximum size. This is described in detail here.
The new ConcurrentHashMap for Java 8 automatically resizes its number of segments. As such the old method of eviction will not work. Instead we keep track of all entries in the entire map and only evict when we go over the max size. This prevents entries from being evicted that may not be the the least recent (previously in the case of when many elements in the same segment were added).
Better scalability
Since we utilize the new ConcurrentHashMap this automatically resizes the segments based on the amount of entries in the cache. Increasing the number of segments has some various benefits.
Tags: eviction
Tuesday, 17 March 2015
Infinispan 7.2.0.Beta1 released
Dear Infinispan community,
We are proud to announce the release of Infinispan 7.2.0.Beta1 today.
Along the usual assortment of bug fixes, this release includes a few exciting new features:
For a complete list of features and bug fixes included in this release, please refer to the release notes.
Feel free to join us and shape the future releases on our forums, our mailing lists or our #infinispan IRC channel.
Many thanks to everyone who contributed to this release!
Tags: release hotrod scripting eviction jcache
Tuesday, 30 March 2010
Infinispan eviction, batching updates and LIRS
DataContainer abstraction represents the heart of Infinispan. It is a container structure where actual cache data resides. Every put, remove, get and other invoked cache operations eventually end up in the data container. Therefore, it is of utmost importance the data container is implemented in a way that does not impede overall system throughput. Also recall that the data container’s memory footprint can not grow indefinitely because we would eventually run out of memory; we have to periodically evict certain entries from the data container according to a chosen eviction algorithm.
LRU eviction algorithm, although simple and easy to understand, under performs in cases of weak access locality (one time access entries are not timely replaced, entries to be accessed soonest are unfortunately replaced, and so on). Recently, a new eviction algorithm - LIRS has gathered a lot of attention because it addresses weak access locality shortcomings of LRU yet it retains LRU’s simplicity.
However, no matter what eviction algorithm is utilized, if eviction is not implemented in a scalable, low lock contention approach, it can seriously degrade overall system performance. In order to do any meaningful selection of entries for eviction we have to lock data container until appropriate eviction entries are selected. Having such a lock protected data container in turn causes high lock contention offsetting any eviction precision gained by sophisticated eviction algorithms. In order to get superior throughput while retaining high eviction precision we need both low lock contention data container and high precision eviction algorithm implementation – a seemingly impossible feat.
Instead of making a trade-off between the high precision eviction algorithm and the low lock contention there is a third approach: we keep lock protected data container but we amortize locking cost through batching updates. The basic idea is to wrap any eviction algorithm with a framework that keeps track of cache access per thread (i.e. ThreadLocal) in a simple queue. For each cache hit associated with a thread, the access is recorded in the thread’s queue. If thread’s queue is full or the number of accesses recorded in the queue reaches a certain pre-determined threshold, we acquire a lock and then execute operations defined by the eviction algorithm - once for all the accesses in the queue. A thread is allowed to access many cache items without requesting a lock to run the eviction replacement algorithm, or without paying the lock acquisition cost. We fully exploit a non-blocking lock APIs like tryLock. As you recall tryLock makes an attempt to get the lock and if the lock is currently held by another thread, it fails without blocking its caller thread. Although tryLock is cheap it is not used for every cache access for obvious reasons but rather on certain pre-determined thresholds. In case when thread’s queue is totally full a lock must be explicitly requested. Therefore, using batching updates approach we significantly lower the cost of lock contention, streamline access to locked structures and retain the precision of eviction algorithm such as LIRS. The key insight is that batching the updates on the eviction algorithm doesn’t materially affect the accuracy of the algorithm.
How are these ideas implemented in Infinispan? We introduced BoundedConcurrentHashMap class based on Doug Lea’s ConcurrentHashMap. BoundedConcurrentHashMap hashes entries based on their keys into lock protected segments. Instead of recording entries accessed per thread we record them in a lock free queue on a segment level. The main reason not to use ThreadLocal is that we could potentially have hundreds of threads hitting the data container, some of them very short lived thus possibly never reaching batching thresholds. When predetermined thresholds are reached eviction algorithms is executed on a segment level. Would running eviction algorithm on a segment level rather than entire data container impact overall eviction precision? In our performance tests we have not found any evidence of that.
Infinispan’s eviction algorithm is specified using strategy attribute of eviction XML element. In addition to old eviction approaches, starting with release 4.1.ALPHA2, you can now select LIRS eviction algorithm. LRU remains the default. Also note that starting with 4.1ALPHA2 release there are two distinct approaches to actually evict entries from the cache: piggyback and the default approach using a dedicated EvictionManager thread. Piggyback eviction thread policy, as it name implies, does eviction by piggybacking on user threads that are hitting the data container. Dedicated EvictionManager thread is unchanged from the previous release and it remains the default option. In order to support these two eviction thread policies a new eviction attribute threadPolicy has been added to eviction element of Infinispan configuration schema.
Does eviction redesign based on batching updates promise to live up to its expectations? Ding et al, authors of the original batching proposal, found that their framework increased throughput nearly twofold in comparison with unmodified eviction in postgreSQL 8.2.3. We do not have any numbers to share yet, however, initial testing of BoundedConcurrentHashMap were indeed promising. One of our partner companies replaced their crucial caching component with BoundedConcurrentHashMap and realized a 54% performance improvement on the Berlin SPARQL benchmark for their flagship product. Stay tuned for more updates.
Cheers,
Vladimir
Tags: eviction concurrency data structures
Tuesday, 20 October 2009
Infinispan based Hibernate Cache Provider available now!
Update (2009/11/13)! Infinispan 4.0.0.Beta2 based Hibernate second level cache provider now available in Hibernate 3.5 Beta2. However, neither Infinispan 4.0.0.Beta2 nor the Infinispan Cache Provider jar are available in the zip distribution. Instead, please download Infinispan 4.0.0.Beta2 from our download site and the Infinispan Cache Provider from our Maven repository.
I’ve just finished the development of an Infinispan 4.0 based Hibernate second level cache provider. This will be included from next Hibernate 3.5 release onwards but if you cannot wait and wanna play with it in the mean time, just checkout Hibernate trunk from our SVN repository and run 'mvn install'.
I’ve also written a wiki called "Using Infinispan as JPA/Hibernate Second Level Cache Provider" that should help users understand how to configure the Infinispan cache provider and how to make the most of it!
So, what’s good about it? Why should I use it? First of all, since the cache provider is based on Infinispan, you benefit from all the improvements we’ve done to Infinispan in terms of performance and memory consumption so far and there are more to come!
On top of that, starting with this cache provider, we’re aiming to reduce the number of files needed to modify in order to define the most commonly tweaked parameters. So, for example, by enabling eviction/expiration configuration on a per generic Hibernate data type or particular entity/collection type via hibernate.cfg.xml or persistence.xml, users don’t have to touch to Infinispan’s cache configuration file any more. You can find detailed information on how to do this in the "Using Infinispan as JPA/Hibernate Second Level Cache Provider" wiki
Please direct any feedback to the Infinispan user forum.
Galder
Tags: eviction hibernate second level cache provider
Tuesday, 12 May 2009
Implementing a performant, thread-safe ordered data container
To achieve efficient ordering of entries in the DataContainer interface for configurations that support eviction, there was a need for a linked HashMap implementation that was thread-safe and performant. Below, I specifically discuss the implementations of the FIFODataContainer and LRUDataContainer in Infinispan 4.0.x. Wherever this document references FIFODataContainer, this also applies to LRUDataContainer - which extends FIFODataContainer. The only difference is that LRUDataContainer updates links whenever an entry is visited as well as added.
After analysing and considering a few different approaches, the one I settled on is a subset of the algorithms described by H. Sundell and P. Tsigas in their 2008 paper titled Lock-Free Deques and Doubly Linked Lists, combined with the approach used by Sun’s JDK6 for reference marking in ConcurrentSkipListMap's implementation.
Reference marking? What’s that?
Compare-and-swap (CAS) is a common technique today for atomically updating a variable or a reference without the use of a mutual exclusion mechanism like a lock. But this only works when you modify a single memory location at a time, be it a reference or a primitive. Sometimes you need to atomically update two separate bits of information in a single go, such as a reference, as well as some information about that reference. Hence reference marking. In C, this is sometimes done by making use of the assumption that an entire word in memory is not needed to store a pointer to another memory location, and some bits of this word can be used to store additional flags via bitmasking. This allows for atomic updates of both the reference and this extra information using a single CAS operation.
This is possible in Java too using AtomicMarkableReference, but is usually considered overly complex, slow and space-inefficient. Instead, what we do is borrow a technique from ConcurrentSkipListMap and use an intermediate, delegating entry. While this adds a little more complexity in traversal (you need to be aware of the presence of these marker entries when traversing the linked list), this performs better than an AtomicMarkableReference.
In this specific implementation, the 'extra information' stored in a reference is the fact that the entry holding the reference is in the process of being deleted. It is a common problem with lock-free linked lists when you have concurrent insert and delete operations that the newly inserted entry gets deleted as well, since it attaches itself to the entry being concurrently deleted. When the entry to be removed marks its references, however, this makes other threads aware of the fact and cause CAS operations on the reference to fail and retry.
Performance
Aside from maintaining order of entries and being thread-safe, performance was one of the other goals. The target is to achieve constant-time performance - O(1) - for all operations on DataContainer.
The clhttp://3.bp.blogspot.com/_ca0W9t-Ryos/SgGwA2iw_vI/AAAAAAAAAKA/TpVMWo2Rq9U/s1600-h/FIFODataContainer.jpeg[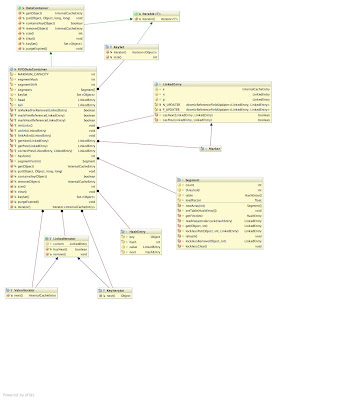 ]ass diagram (click to view in full-size) depicts the FIFODataContainer class. At its heart the FIFODataContainer mimics a JDK ConcurrentHashMap (CHM), making use of hashtable-like lockable segments. Unlike the segments in CHM, however, these segments are simpler as they support a much smaller set of operations.
]ass diagram (click to view in full-size) depicts the FIFODataContainer class. At its heart the FIFODataContainer mimics a JDK ConcurrentHashMap (CHM), making use of hashtable-like lockable segments. Unlike the segments in CHM, however, these segments are simpler as they support a much smaller set of operations.
Retrieving data from the container The use of segments allow for constant-time thread-safe get() and containsKey() operations. Iterators obtained from the DataContainer - which implements Iterable, and hence usable in for-each loops - and keySet() are immutable, thread-safe and efficient, using traversal of the linked list - making use of getNext() and getPrev() helpers. See below for details. Traversal is efficient and constant-time.
Updating the container When removing an entry, remove() locks the segment in question, removes the entry, and unlinks the entry. Both operations are thread-safe and constant-time. Locking the segment and removing the entry is pretty straightforward. Unlinking involves marking references, and then an attempt at CAS’ing next and previous references to bypass the removed entry. Order here is important - updates to the next reference needs to happen first, read on for more details as to why.
When performing a put(), the entry is created, segment locked and entry inserted into the segment. The entry is then inserted at the tail of the linked list. Again, both operations are thread-safe and constant-time. Linking at the tail involves careful CAS’ing of references on the new entry, the tail dummy entry and the former last entry in the list.
Maintaining a lock-free, concurrent doubly linked list It is important to note that the entries in this implementation are doubly linked. This is critical since, unlike the JDK’s ConcurrentSkipListMap, we use a hashtable to look up entries to be removed, to achieve constant time performance in lookup. Locating the parent entry to update a reference needs to be constant-time as well, and hence the need for a previous reference. Doubly-linked lists make things much trickier though, as there two references to update atomically (yes, that sounds wrong!)
Crucially, what we do not care about - and do not support - is reverse-order traversal. This means that we only really care about maintaining accuracy in the forward direction of the linked list, and treat the previous reference as an approximation to an entry somewhere behind the current entry. Previous references can then be corrected - using the correctPrev() helper method described below - to locate the precise entry behind the current entry. By placing greater importance on the forward direction of the list, this allows us to reliably CAS the forward reference even if the previous reference CAS fails. It is hence critical that whenever any references are updated, the next reference is CAS’d first, and only on this success the previous reference CAS is attempted. The same order applies with marking references. Also, it is important that any process that touches an entry that observes that the next pointer is marked but the previous pointer is not, attempts to mark the previous pointer before attempting any further steps.
The specific functions we need to expose, to support DataContainer operations, are:
void linkAtEnd(LinkedEntry entry);
void unlink(LinkedEntry entry);
LinkedEntry correctPrev(LinkedEntry suggestedPrev, LinkedEntry current);
LinkedEntry getNext(LinkedEntry current);
LinkedEntry getPrev(LinkedEntry current);These are exposed as protected final methods, usable by FIFODataContainer and its subclasses. The implementations themselves use a combination of CAS’s on a LinkedEntry’s next and previous pointers, marking references, and helper correction of previous pointers when using getNext() and getPrevious() to traverse the list. Note that it is important that only the last two methods are used when traversing rather than directly accessing a LinkedEntry’s references - since markers need to be stepped over and links corrected.
Please refer to Lock-Free Deques and Doubly Linked Lists for details of the algorithm steps.
Tags: algorithms eviction concurrency data structures