Tuesday, 25 May 2010
Infinispan EC2 Demo
Infinispan’s distributed mode is well suited to handling large datasets and scaling the clustered cache by adding nodes as required. These days when inexpensive scaling is thought of, cloud computing immediately comes to mind.
One of the largest providers of cloud computing is Amazon with its Amazon Web Services (AWS) offering. AWS provides computing capacity on demand with its EC2 services and storage on demand with its S3 and EBS offerings. EC2 provides just an operating system to run on and it is a relatively straightforward process to get an Infinispan cluster running on EC2. However there is one gotcha, EC2 does not support UDP multicasting at this time and this is the default node discovery approach used by Infinispan to detect nodes running in a cluster.
Some background on network communications
Infinispan uses the JGroups library to handle all network communications. JGroups enables cluster node detection, a process called discovery, and reliable data transfer between nodes. JGroups also handles the process of nodes entering and exiting the cluster and master node determination for the cluster.
Configuring JGroups in Infinispan The JGroups configuration details are passed to Infinispan in the infinispan configuration file
<transport clusterName="infinispan-cluster" distributedSyncTimeout="50000"
transportClass="org.infinispan.remoting.transport.jgroups.JGroupsTransport">
<properties>
<property name="configurationFile" value="jgroups-s3_ping-aws.xml" />
</properties>
</transport>Node Discovery
JGroups has three discovery options which can be used for node discovery on EC2.
The first is to statically configure the address of each node in the cluster in each of the nodes peers. This simplifies discovery but is not suitable when the IP addresses of each node is dynamic or nodes are added and removed on demand.
The second method is to use a Gossip Router. This is an external Java process which runs and waits for connections from potential cluster nodes. Each node in the cluster needs to be configured with the ip address and port that the Gossip Router is listening on. At node initialization, the node connects to the gossip router and retrieves the list of other nodes in the cluster.
Example JGroups gossip router configuration
<config>
<TCP bind_port="7800" />
<TCPGOSSIP timeout="3000" initial_hosts="192.168.1.20[12000]"
num_initial_members="3" />
<MERGE2 max_interval="30000" min_interval="10000" />
<FD_SOCK start_port="9777" />
...
</config>The infinispan-4.1.0-SNAPSHOT/etc/config-samples/ directory has sample configuration files for use with the Gossip Router. The approach works well but the dependency on an external process can be limiting.
The third method is to use the new S3_PING protocol that has been added to JGroups. Using this the user configures a S3 bucket (location) where each node in the cluster will store its connection details and upon startup each node will see the other nodes in the cluster. This avoids having to have a separate process for node discovery and gets around the static configuration of nodes.
Example JGroups configuration using the S3_PING protocol:
<config>
<TCP bind_port="7800" />
<S3_PING secret_access_key="secretaccess_key" access_key="access_key"
location=s3_bucket_location" />
<MERGE2 max_interval="30000" min_interval="10000" />
<FD_SOCK start_port="9777" />
...
</config>EC2 demo
The purpose of this demo is to show how an Infinispan cache running on EC2 can easily form a cluster and retrieve data seamlessly across the nodes in the cluster. The addition of any subsequent Infinispan nodes to the cluster automatically distribute the existing data and offer higher availability in the case of node failure.
To demonstrate Infinispan, data is required to be added to nodes in the cluster. We will use one of the many public datasets that Amazon host on AWS, the influenza virus dataset publicly made available by Amazon.
This dataset has a number components which make it suitable for the demo. First of all it is not a trivial dataset, there are over 200,000 records. Secondly there are internal relationships within the data which can be used to demonstrate retrieving data from different cache nodes. The data is made up for viruses, nucleotides and proteins, each influenza virus has a related nucleotide and each nucleotide has one or more proteins. Each are stored in their own cache instance.
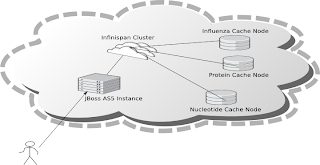
The caches are populated as follows :
-
InfluenzaCache - populated with data read from the
Influenza.datfile, approx 82,000 entries -
ProteinCache - populated with data read from the
Influenza_aa.datfile, approx 102,000 entries -
NucleotideCache - populated with data read from the
Influenza_na.datfile, approx 82,000 entries
The demo requires 4 small EC2 instances running Linux, one instance for each cache node and one for the Jboss application server which runs the UI. Each node has to have Sun JDK 1.6 installed in order to run the demos. In order to use the Web-based GUI, JBoss AS 5 should also be installed on one node.
In order for the nodes to communicate with each other the EC2 firewall needs to be modified. Each node should have the following ports open:
-
TCP 22 – For SSH access
-
TCP 7800 to TCP 7810 – used for JGroups cluster communications
-
TCP 8080 – Only required for the node running the AS5 instance in order to access the Web UI.
-
TCP 9777 - Required for FD_SOCK, the socket based failure detection module of the JGroups stack.
To run the demo, download the Infinispan "all" distribution, (infinispan-xxx-all.zip) to a directory on each node and unzip the archive.
Edit the etc/config-samples/ec2-demo/jgroups-s3_ping-aws.xml file to add the correct AWS S3 security credentials and bucket name.
Start the one of the cache instances on each node using one of the following scripts from the bin directory:
-
runEC2Demo-influenza.sh -
runEC2Demo-nucleotide.sh -
runEC2Demo-protein.sh
Each script will startup and display the following information :
[tmp\] ./runEC2Demo-nucleotide.shCacheBuilder called with /opt/infinispan-4.1.0-SNAPSHOT/etc/config-samples/ec2-demo/infinispan-ec2-config.xml ------------------------------------------------------------------- GMS: address=redlappie-37477, cluster=infinispan-cluster, physical address=192.168.122.1:7800 ------------------------------------------------------------------- Caches created.... Starting CacheManagerCache Address=redlappie-57930Cache Address=redlappie-37477Cache Address=redlappie-18122 Parsing files....Parsing [/opt/infinispan-4.1.0-SNAPSHOT/etc/Amazon-TestData/influenza_na.dat] About to load 81904 nucleotide elements into NucleiodCache Added 5000 Nucleotide records Added 10000 Nucleotide records Added 15000 Nucleotide records Added 20000 Nucleotide records Added 25000 Nucleotide records Added 30000 Nucleotide records Added 35000 Nucleotide records Added 40000 Nucleotide records Added 45000 Nucleotide records Added 50000 Nucleotide records Added 55000 Nucleotide records Added 60000 Nucleotide records Added 65000 Nucleotide records Added 70000 Nucleotide records Added 75000 Nucleotide records Added 80000 Nucleotide records Loaded 81904 nucleotide elements into NucleotidCache Parsing files....Done Protein/Influenza/Nucleotide Cache Size-->9572/10000/81904 Protein/Influenza/Nucleotide Cache Size-->9572/20000/81904 Protein/Influenza/Nucleotide Cache Size-->9572/81904/81904 Protein/Influenza/Nucleotide Cache Size-->9572/81904/81904
Items of interest in the output are the Cache Address lines which display the address of the nodes in the cluster. Also of note is the Protein/Influenza/Nucleotide line which displays the number of entries in each cache. As other caches are starting up these numbers will change as cache entries are dynamically moved around through out the Infinispan cluster.
To use the web based UI we first of all need to let the server know where the Infinispan configuration files are kept. To do this edit the jboss-5.1.0.GA/bin/run.conf file and add the line
JAVA_OPTS="$JAVA_OPTS -DCFGPath=/opt/infinispan-4.1.0-SNAPSHOT/etc/config-samples/ec2-demo/"at the bottom. Replace the path as appropriate.
Now start the Jboss application server using the default profile e.g. run.sh -c default -b xxx.xxx.xxx.xxx, where “xxx.xxx.xxx.xxx” is the public IP address of the node that the AS is running on.
Then drop the infinispan-ec2-demoui.war into the jboss-5.1.0.GA /server/default/deploy directory.
Finally point your web browser to http://public-ip-address:8080/infinispan-ec2-demoui and the following page will appear.

The search criteria is the values in the first column of the /etc/Amazon-TestData/influenza.dat file e.g. AB000604, AB000612, etc.

Note that this demo will be available in Infinispan 4.1.0.BETA2 onwards. If you are impatient, you can always build it yourself from Infinispan’s source code repository.
Enjoy, Noel
Tags: ec2 amazon jgroups s3 demo aws
Saturday, 02 May 2009
Keep it in the cloud
Corporate slaves often spend months of paper work only to find their machine obsolete before its powered on. Forward thinking individuals need playgrounds to try out new ideas. Enterprise 2.0 projects have to scale with their user base. In short, there’s a lot of demand for flexible infrastructure. Cloud infrastructure is one way to fill that order.
One popular cloud infrastructure provider is Amazon EC2. EC2 is basically a pay-as-you-go datacenter. You pay for CPU, storage, and network resources. Using the open-source Infinispan data grid, you have a good chance of linear performance as your application needs change. Using EC2, you can instantly bring on hosts to support that need. Great match, right? What’s next?
Assuming your data is important, you will need to persist your Infinispan cluster somewhere. That said, Amazon charges you for traffic that goes in and out of their network… this could get expensive. So, the next bit is controlling these costs.
Amazon offers a storage service called S3. Transferring data between EC2 and S3 is free; you only pay for data parking. In short, there is a way to control these I/O costs: S3.
Infinispan will save your cluster to S3 when configured with its high-performance JClouds plug-in. You specify the S3 Bucket and your AWS credentials and Infinispan does the rest.
In summary, not only does Infinispan shred your license costs, but we also help cut your persistence costs, too!
So, go ahead: Keep it in the cloud!
Tags: data grids jclouds ec2 s3 aws