Friday, 02 November 2018
Near caching with Spring-Boot and Infinispan
We have recently released infinispan-spring-boot-starter 2.0.0.Final. This version supports Spring Boot 2.1 and Infinispan 9.4.0.Final.
Before this release, some important features - such as near caching - were only configurable by code. From now on, we can set all of the Hot Rod client configuration using the hotrod.properties file or the Spring application YAML. The latter is an important community requirement we had.
Let’s see how to speed up our applications performance with near caching!
==
==
Hot Rod
Just as a quick reminder, Infinispan can be used embedded in your application or in client/server mode. To connect you application to a server you can use an Infinispan Client and the Infinispan “Hot Rod Protocol”. Other protocols are available, such as REST, but Hot Rod is the most recommended way since it is the one that supports most of the Infinispan functionalities.
Near cache
From the Infinispan documentation: Hot Rod client can keep a local cache that stores recently used data. Enabling near caching can significantly improve the performance of read operations get and getVersioned since data can potentially be located locally within the Hot Rod client instead of having to go remote.
When should I use it?
Near caching can improve the performance of an application when most of the accesses to a given cache are read-only and the accessed dataset is relatively small. When an application is doing lots of writes to a cache, invalidations, evictions and updates to the near cache need to happen. In this scenario we won’t probably get much benefit.
As I said in the introduction, the good news is that this feature can be activated just by configuration. Code doesn’t change, so we can measure the benefits, if such exist, in a very straightforward way.
Spring-Boot
I have created a very simple application, available here. Maven, Java 8 and an Infinispan server are required to run it. You can download the server or use docker.
Docker: docker run -it -p 11222:11222 jboss/infinispan-server:9.4.0.Final
Standalone: PATH/infinispan-server-9.4.0.Final/bin/standalone.sh
Once the server is up and running, build the application using maven
>> infinispan-near-cache: mvn clean install
Activating the near cache
I need to configure two properties:
-
Near Cache Mode: DISABLED or INVALIDATED. Default value is DISABLED, so I turn it on with INVALIDATED.
-
Max Entries: Integer value that sets the max size of the near caches. There is no default value, so I set up one.
The hotrod client configuration is for each client, not for each cache (this might change in the future). With that in mind, note that configuring the previous properties will activate near caching for all the caches. If you need to activate it just for some of them, add the following property:
-
Cache Name Pattern: String pattern. For example "i8n-.*" will activate the near caching for all the caches whose name starts by "i8n-".
Configuration can be placed in the hotrod-client.properties, Spring-boot configuration or code.
Results
My dataset contains 25 contributors. If I activate the near cache with max 12 entries and I run my reader again, I get the job done in ~1900 milliseconds, which is already an improvement. If I configure it to hold the complete dataset, I get it done in ~220 milliseconds, which is a big one!
Conclusions
Near caching can help us speed up our client applications if configured properly. We can test our tuning easily because we only need to add some configuration to the client. Finally, the Spring-Boot Infinispan Starter helps us build services with Spring-Boot and Infinispan.
Further work will be done to help Spring-Boot users work with Infinispan, so stay tuned! Any feedback on the starter or any requirement from the community is more that welcome. Find us in Zulip Chat for direct contact or post your questions in StackOverflow!
Tags: hotrod near caching spring spring boot
Sunday, 10 September 2017
Multi-tenancy - Infinispan as a Service (also on OpenShift)
In recent years Software as a Service concept has gained a lot of traction. I’m pretty sure you’ve used it many times before. Let’s take a look at a practical example and explain what’s going on behind the scenes.
Practical example - photo album application
Imagine a very simple photo album application hosted within the cloud. Upon the first usage you are asked to create an account. Once you sign up, a new tenant is created for you in the application with all necessary details and some dedicated storage just for you. Starting from this point you can start using the album - download and upload photos.
The software provider that created the photo album application can also celebrate. They have a new client! But with a new client the system needs to increase its capacity to ensure it can store all those lovely photos. There are also other concerns - how to prevent leaking photos and other data from one account into another? And finally, since all the content will be transferred through the Internet, how to secure transmission?
As you can see, multi-tenancy is not that easy as it would seem. The good news is that if it’s properly configured and secured, it might be beneficial both for the client and for the software provider.
Multi-tenancy in Infinispan
Let’s think again about our photo album application for a moment. Whenever a new client signs up we need to create a new account for him and dedicate some storage. Translating that into Infinispan concepts this would mean creating a new CacheContainer. Within a CacheContainer we can create multiple Caches for user details, metadata and photos. You might be wondering why creating a new Cache is not sufficient? It turns out that when a Hot Rod client connects to a cluster, it connects to a CacheContainer exposed via a Hot Rod Endpoint. Such a client has access to all Caches. Considering our example, your friends could possibly see your photos. That’s definitely not good! So we need to create a CacheContainer per tenant. Before we introduced Multi-tenancy, you could expose each CacheContainer using a separate port (using separate Hot Rod Endpoint for each of them). In many scenarios this is impractical because of proliferation of ports. For this reason we introduced the Router concept. It allows multiple clients to access their own CacheContainers through a single endpoint and also prevents them from accessing data which doesn’t belong to them. The final piece of the puzzle is transmitting sensitive data through an unsecured channel such as the Internet. The use of TLS encryption solves this problem. The final outcome should look like the following:
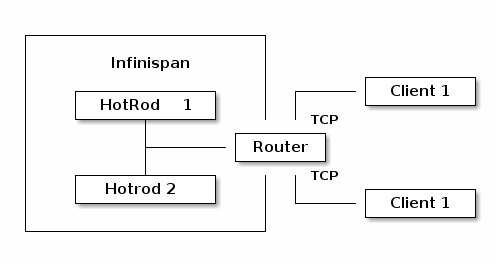
The Router component on the diagram above is responsible for recognizing data from each client and redirecting it to the appropriate Hot Rod endpoint. As the name implies, the router inspects incoming traffic and reroutes it to the appropriate underlying CacheContainer. To do this it can use two different strategies depending on the protocol: TLS/SNI for the Hot Rod protocol, matching each server certificate to a specific cache container and path prefixes for REST. The SNI strategy detects the SNI Host Name (which is used as tenant) and also requires TLS certificates to match. By creating proper trust stores we can match which tenant can access which CacheContainers. URL path prefix is very easy to understand, but it is also less secure unless you enable authentication. For this reason it should not be used in production unless you know what you are doing (the SNI strategy for the REST endpoint will be implemented in the near future). Each client has its own unique REST path prefix that needs to be used for accessing the data (e.g. http://127.0.0.1:8080/rest/client1/fotos/2).
Confused? Let’s clarify this with an example.
Foto application sample configuration
The first step is to generate proper key/trust stores for the server and client:
The next step is to configure the server. The snippet below shows only the most important parts:
Let’s analyze the most critical lines:
-
7, 15 - We need to add generated key stores to the server identities
-
25, 30 - It is highly recommended to use separate CacheContainers
-
38, 39 - A Hot Rod connector (but without socket binding) is required to provide proper mapping to CacheContainer. You can also use many useful settings on this level (like ignored caches or authentication).
-
42 - Router definition which binds into default Hot Rod and REST ports.
-
44 - 46 - The most important bit which states that only a client using SSLRealm1 (which uses trust store corresponding to client_1_server_keystore.jks) and TLS/SNI Host name client-1 can access Hot Rod endpoint named multi-tenant-hotrod-1 (which points to CacheContainer multi-tenancy-1).
Improving the application by using OpenShift
Hint: You might be interested in looking at our previous blog posts about hosting Infinispan on OpenShift. You may find them at the bottom of the page.
So far we’ve learned how to create and configure a new CacheContainer per tenant. But we also need to remember that system capacity needs to be increased with each new tenant. OpenShift is a perfect tool for scaling the system up and down. The configuration we created in the previous step almost matches our needs but needs some tuning.
As we mentioned earlier, we need to encrypt transport between the client and the server. The main disadvantage is that OpenShift Router will not be able to inspect it and take routing decisions. A passthrough Route fits perfectly in this scenario but requires creating TLS/SNI Host Names as Fully Qualified Application Names. So if you start OpenShift locally (using oc cluster up) the tenant names will look like the following: client-1-fotoalbum.192.168.0.17.nip.io.
We also need to think how to store generated key stores. The easiest way is to use Secrets:
Finally, a full DeploymentConfiguration:
If you’re interested in playing with the demo by yourself, you might find a working example here. It mainly targets OpenShift but the concept and configuration are also applicable for local deployment.
Tags: security hotrod server multi-tenancy rest
Wednesday, 11 January 2017
Near Cache for native C++/C# Client example
Dear Readers,
as mentioned in our previous post about the new C++/C# release 8.1.0.Beta1, clients are now equipped with near cache support.
The near cache is an additional cache level that keeps the most recently used cache entries in an "in memory" data structure. Near cached objects are synchronized with the remote server value in the background and can be get as fast as a map[] operation.
So, your client tends to periodically focus the operations on a subset of your entries? This feature could be of help: it’s easy to use, just enable it and you’ll have near cache seamless under the wood.
A C++ example of a cache with near cache configuration
The last line does the magic, the INVALIDATED mode is the active mode for the near cache (default mode is DISABLED which means no near cache, see Java docs), maxEntries is the maximum number of entries that can be stored nearly. If the near cache is full the oldest entry will be evicted. Set maxEntries=0 for unbounded cache (do you have enough memory?) Now a full example of application that just does some gets and puts and counts how many of them are served remote and how many are served nearly. As you can see the cache object is an instance of the "well known" RemoteCache class
Entries values in the near cache are kept aligned with the remote cache state via the events subsystem: if something changes in the server, an update event (modified, expired, removed) is sent to the client that updates the cache accordingly.
By the way: do you know that C++/C# clients can subscribe listener to events? In the next "native" post we will see how.
Cheers! and thank you for reading.
Tags: c++ hotrod near caching 8.1.0 cpp-client dotnet-client c#
Wednesday, 04 January 2017
Hotrod clients C++/C# 8.1.0.Beta1 released!
New Year, New (Beta) Clients!
I’m pleased to announce that the C++/C# clients version 8.1.0.Beta1 are out! The big news in this release is:
-
Near Caching Support
Find the bits in the usual place: http://infinispan.org/hotrod-clients/
Features list for 8.1 is almost done… not bad :) Feedbacks, proposals, hints and lines of code are welcome!
Happy New Year, The Infinispan Team
Tags: c++ release hotrod 8.1.0 cpp-client dotnet-client c#
Friday, 11 November 2016
Hotrod clients C++/C# 8.1.0.Alpha2 released!
Dear Infinispan community,
I’m pleased to announce that the C++/C# clients version 8.1.0.Alpha2 are out!
Some of the good news coming with this release:
-
more bugs fixed than added
-
SNI support
-
C++ Client listener for remote events
Download it from the usual link http://infinispan.org/hotrod-clients/
We’re trying to keep track of the 8.1 trip at this Jira url: Features list for 8.1 Feedbacks, proposals, hints are welcome!
Cheers, The Infinispan Team
Tags: c++ release hotrod cpp-client dotnet-client c#
Thursday, 01 September 2016
Hotrod clients C/C# 8.0.0.Final released!
Dear Infinispan community, I’m glad to announce the Final release of the C++ and C# clients version 8.0.0.
You can find the download on the Infinispan web site:
Major new features for this release are:
-
queries
-
remote script execution
-
asynchronous operation (C++ only)
plus several minor and internal updates that partially fill the gap between C++/C# and the Java client.
Some posts about the 8 serie of the C++/C# clients have been already published on this blog, you can recall them clicking through the list below.
The equivalent C# examples are collected here:
Enjoy!
Tags: c++ release hotrod cpp-client dotnet-client c#
Wednesday, 01 June 2016
HotRod C++ Native Client 8 Series
The Infinispan Team started the development of the new HotRod C Client (version 8) with two main goals in mind: update and refresh the code and reduce the feature gap between the C client and its Java big brother.
The work is still in progress, but since we’re close to the 8.0.0.Final release, I would like to describe, in this and in the following posts, what’s changed as of today.
Although there are a lot of changes and improvements in the code (protocol updates, segments topology, configurable balancing strategy… you can have a detailed view of the activities stream browsing to the Jira issues), I would like to focus on the following three big changes:
-
C++11 Standard
-
Remote Execution
-
Queries
C++11 Standard
Activities grouped under this title are motivated by the change in the development approach of the new features. Until version 7 we have followed the approach of keeping the baseline compiler requirements quite low to ensure a broad client portability, even to platforms with old compilers/libraries, #[#result_box]#but when we started development for the 8 series we felt that this principle would excessively complicate the implementation of new features.
With this in mind, we have fully embraced the new C++11 language feature (such as lambda function in the asynchronous interface method, or variadic templates) and pushed for extensive use of standard library container classes in lieu of our custom ones.
We know that in this way we may have limited use of the client to more recent platforms (bye bye RHEL 6) but fortunately the source is open and we have a very good build procedure based on cmake that can easily generates builder for the most used pair <compiler model, compiler version>.
The work on C++11 language adoption is still in progress and the goal on this front is to update the code wherever it results in improved readability (i.e. the auto keyword is a simple but powerful way to reduce code verbosity).
Because in this cycle we have added a few new features that required the introduction of some library dependencies and automatic code generation, the build process has become more complex, but we’re doing our best to keep it manageable. We want to ensure that our packaging structure is what users expect on all of our platforms with respect to libraries, headers and documentation.
[result_box] #
I will be glad to hear from any of you about any thoughts and suggestions, especially on the portability issues.
[result_box] #
In the next post I will show an example of the new Remote Script Execution features.
[result_box] #
Cheers
[result_box] #
Tags: c++ hotrod
Friday, 16 October 2015
Stored Script Execution
One of the questions we get asked a lot is: when will I be able to run Map/Reduce and DistExec jobs over HotRod.
I’m happy to say: now !
Infinispan Server comes with Stored Script Execution which means that remote clients can invoke named scripts on the server. If you’re familiar with the concept of Stored Procedures of the SQL world, then you already have an idea of what this feature is about. The types of scripts you can run are those handled by Java’s scripting API. Out of the box this means Javascript (which uses either the Nashorn engine on JDK 8+), but you can add many more (Groovy, Scala, JRuby, Jython, Lua, etc). Scripts are stored in a dedicated script cache ("___scriptcache") so that they can be easily created/modified using the standard cache operations (put/get/etc.).
Here’s an example of a very simple script:
The script above just obtains the default cache, retrieves the value with key 'a' and returns it (the Javascript script engine uses the last evaluated expression of a script as its return value). The first line of the script is special: it looks like a comment, but, like the first line in Unix shell scripts, it actually provides instructions on how the script should be run in the form of properties.
The mode property instructs the execution engine where we want to run the script: local for running the script on the node that is handling the request and distributed for running the script wrapped by a distributed executor. Bear in mind that you can certainly use clustered operations in local mode.
Scripts can also take named parameters which will "appear" as bindings in the execution scope.
Invoking it from a Java HotRod client would look like this:
Server-side scripts will be evolving quite a bit in Infinispan 8.1 where we will add support for the broader concept of server-side tasks which will include both scripts and deployable code which can be invoked in the same way, all managed and configured by the upcoming changes in the Infinispan Server console.
Tags: hotrod remote scripting javascript server nashorn
Monday, 14 September 2015
Initial Support for Apache Avro and Gora
Avro and Gora are two Apache projects that belong to the Hadoop ecosystem. Avro is a data serialization framework that relies on JSON for defining data types and protocols, and serializes data in a compact binary format. Its primary use in Hadoop is to provide a serialization format for persistent data, and a wire format for communication between Hadoop nodes, and from client programs to the Hadoop services. Gora is an open-source software framework that provides an in-memory data model and persistence for big data. Gora supports persisting to column stores, key/value stores or databases, and analyzing the data with extensive Apache Hadoop MapReduce support.
As an effort to run Hadoop based applications atop Infinispan, the LEADS EU FP7 project has developed an Avro backend (infinispan-avro) and a Gora module (gora-infinispan). The former allows to store, retrieve and query Avro defined types via the HotRod protocol. The latter allows Gora-based applications to use Infinispan as a storage backend for their MapReduce jobs. In the current state of the implementation, the two modules make use of Infinispan 8.0.0.Final, Avro 1.7.6 and Gora 0.6
What’s in it for you Infinispan user
There are several use cases for which you can benefit from those modules.
-
With Infinispan’s Avro support, you can decide to persist your data in Infinispan using Avro’s portable format instead of Infinispan’s own format (or Java serialization’s format). This might help you standardize upon a common format for your data at rest.
-
If you use Apache Gora to store/query some of your data in, or even out, of the Hadoop ecosystem, you can use Infinispan as the backend and benefit Infinispan’s features that you come to know like data distribution, partition handling, cross-site clustering.
-
The last use case is to run legacy Hadoop applications, using Infinispan as the primary storage. For instance, it is possible to run the Apache Nutch web crawler atop Infinispan. A recent paper at IEEE Cloud 2015 gives a detailed description of such an approach in a geo-distributed environment (a preprint is available here).
Tags: marshalling hotrod map reduce
Tuesday, 11 August 2015
Infinispan 7.2.4.Final out including fixes for async store, Hot Rod...etc
Infinispan 7.2.4.Final is just out containing some important fixes in areas such as Hot Rod client and server, async cache store, key set iteration, as well as a Hibernate HQL parser upgrade. You can find more details about the issues fixed in our detailed release notes.
Happy hacking :)
Galder
Tags: release hotrod hql cache store