Tuesday, 02 October 2018
Segmented Data Containers: Distributed Stream Performance Boost
Welcome to the first of several blog posts that describe the segmentation of containers that Infinispan uses to store data. Some of you may have noticed in the previous 9.3.0.Final notes that we announced a new feature named “Segmented On-Heap Data Container”. We also mentioned that “It improves performance of stream operations”, but what does that really mean?
What is a segmented data container and why does it matter?
Imagine a cluster of 4 nodes in distributed mode (numOwners = 2) with entries for k0 - k13. It might look like this:

The data is distributed between the nodes with only two copies of each entry available. However, the data itself is stored internally in the same Map instance. As a result, when performing operations on all entries in the cache, Infinispan must iterate over the same data multiple times. This degrades performance.
As of Infinispan 9.3, a segmented data container is available to separate data by segments. Although only on-heap bounded and unbounded implementations are currently available.
With a segmented data container, that same data set might look like this:

Because Infinispan internally reasons on data in terms of segments, a segmented data container lets Infinispan process data only in specific segments. This allows for operations performed upon all entries to require iteration over the data only once.
Actual Performance Difference
So with the above example you might be thinking that the performance increase maximum is two times throughput, since numOwners is two. This is close, but not quite correct. While iterating on the data we also have to determine what segment an entry belongs to. With a segmented container we know this already, so there is no need to calculate that. This provides additional performance, as you will see.
The following graphs were generated using the benchmark at https://github.com/infinispan/infinispan-benchmarks/tree/master/iteration. The following command was run: java -jar target/benchmarks.jar -pvalueObjectSize=1000 -pentryAmount=50000 -pbatchSize=4096

The preceding graph is the result of the iteration methods. As you can notice the performance increase isn’t that much… why not?!?
Unfortunately, remote iteration requires a lot of network overhead, so we don’t get to see the full benefits of segmentation. But at least it is about 5-12% faster, not too shabby.
Now to show the real improvement, here is the chart showing the performance increase for the Cache#size operation:

If you notice there is huge increase in performance: almost a three fold increase over the non-segmented container, even though numOwners is only two. The old segment calculation adds a bit of overhead compared to just incrementing a number.
So keep in mind this change will show a larger gain in performance if the result returned is smaller, especially if it is a fixed size, such as a single int for Cache#size.
What about gets and puts?
Having the container segmented should also affect get and put performance as well, right? In testing the difference for get and puts are less than one percent, in favor of segmentation due to some optimizations we were able to add.
How do I enable this?
So the performance gains are noticeable, especially when the remote operation returns a small data set. But how can a user configure this? This is the nice part, due to no performance loss with other operations the container will always be segmented as long as the cache mode supports segmentation. That is if it is a Distributed, Replicated or Scattered cache.
A real-life example and closing
Since this feature has been around a while already, we actually have users gaining benefits from this feature. An example can be found at https://developer.jboss.org/message/983837#983837. In this case the user only upgraded to Infinispan 9.3 and received over a three-fold increase in performance when using distributed streams. It actually starts to bring distributed streams performance within range of indexed query for some use cases.
So, by upgrading your application to Infinispan 9.3 or newer, you will benefit from these improvements. There will be future posts regarding segmentation, including support for stores. Either way please feel free to download Infinispan, report bugs, chat with us, ask questions on the forum or on StackOverflow.
Tags: streams segmented data container performance
Monday, 05 December 2016
Infinispan 9.0.0.Beta1 "Ruppaner"
![]()
It took us quite a bit to get here, but we’re finally ready to announce Infinispan 9.0.0.Beta1, which comes loaded with a ton of goodies.
Performance improvements
-
JGroups 4
-
A new algorithm for non-transactional writes (aka the Triangle) which reduces the number of RPCs required when performing writes
-
A new faster internal marshaller which produced smaller payloads.
-
A new asynchronous interceptor core
Off-Heap support
-
Avoid the size of the data in the caches affecting your GC times
CaffeineMap-based bounded data container
-
Superior performance
-
More reliable eviction
Ickle, Infinispan’s new query language
-
A limited yet powerful subset of JPQL
-
Supports full-text predicates
The Server Admin console now supports both Standalone and Domain modes
Pluggable marshallers for Kryo and ProtoStuff
The LevelDB cache store has been replaced with the better-maintained and faster RocksDB
Spring Session support
Upgraded Spring to 4.3.4.RELEASE
We will be blogging about the above in detail over the coming weeks, including benchmarks and tutorials.
The following improvements were also present in our previous Alpha releases:
Graceful clustered shutdown / restart with persistent state
Support for streaming values over Hot Rod, useful when you are dealing with very large entries
Cloud and Containers
-
Out-of-the box support for Kubernetes discovery
Cache store improvements
-
The JDBC cache store now use transactions and upserts. Also the internal connection pool is now based on HikariCP
Also, our documentation has received a big overhaul and we believe it is vastly superior than before.
There will be one more Beta including further performance improvements as well as additional features, so stay tuned.
Infinispan 9 is codenamed "Ruppaner" in honor of the Konstanz brewery, since many of the improvements of this release have been brewed on the shores of the Bodensee !
Prost!
Tags: beta release marshalling off-heap performance query
Friday, 09 January 2015
Infinispan 7.1.0.Beta1
Dear Infinispan community,
We’re proud to announce the first Beta release of Infinispan 7.1.0.
Infinispan brings the following major improvements:
-
Near-Cache support for Remote HotRod caches
-
Annotation-based generation of ProtoBuf serializers which removes the need to write the schema files by hand and greatly improves usability of Remote Queries
-
Cluster Listener Event Batching, which coalesces events for better performance
-
Cluster- and node-wide aggregated statistics
-
Vast improvements to the indexing performance
-
Support for domain mode and the security vault in the server
-
Further improvements to the Partition Handling with many stability fixes and the removal of the Unavailable mode: a cluster can now be either Available or Degraded.
Of course there’s also the usual slew of bug fixes, performance and memory usage improvements and documentation cleanups.
Feel free to join us and shape the future releases on our forums, our mailing lists or our #infinispan IRC channel.
For a complete list of features and bug fixes included in this release please refer to the release notes. Visit our downloads section to find the latest release.
Thanks to everyone for their involvement and contribution!
Tags: release near caching domain mode performance Protobuf indexing annotations
Thursday, 05 June 2014
Map/Reduce Performance improvements between Infinispan 6 and 7
Introduction
There have been a number of recent Infinispan 7.0 Map/Reduce performance related improvements that we were eager to test in our performance lab and subsequently share with you. The results are more than promising. In the word count use case, Map/Reduce task execution speed and throughput improvement is between fourfold and sixfold in certain situations that were tested.
We have achieved these improvements by focusing on:
-
Optimized mapper/reducer parallel execution on all nodes
-
Improving the handling and processing of larger data sets
-
Reducing the amount of memory needed for execution of MapReduceTask
Performance Test Results
The performance tests were run using the following parameters:
-
An Infinispan 7.0.0-SNAPSHOT build created after the last commits from the list were committed to the Infinispan GIT repo on May 9th vs Infinispan 6.0.1.Final
-
OpenJDK version 1.7.0_55 with 4GB of heap and the following JVM options:
-
Random data filled 30% of the Java heap, and 100 random words were used to create the 8 kilobyte cache values. The cache keys were generated using key affinity, so that the generated data would be distributed evenly in the cache. These values were chosen, so that a comparison to Infinispan 6 could be made. Infinispan 7 can handle a final result map with a much larger set of keys than is possible in Infinispan 6. The actual amount of heap size that is used for data will be larger due to backup copies, since the cluster is running in distributed mode.
-
The MapReduceTask executes a word count against the cache values using mapper, reducer, combiner, and collator implementations. The collator returns the 10 most frequently occurring words in the cache data. The task used a distributed reduce phase and a shared intermediate cache. The MapReduceTask is executed 10 times against the data in the cache and the values are reported as an average of these durations.
From 1 to 8 nodes using a fixed amount of data and 30% of the heap
This test executes two word count executions on each cluster with an increasing number of nodes. The first execution uses an increasing amount of data equal to 30% of the total Java heap across the cluster (i.e. With one node, the data consumes 30% of 4 GB. With two nodes, the data consumes 30% of 8 GB, etc.), and the second execution uses a fixed amount of data, (1352 MB which is approximately 30% of 4 GB). Throughput is calculated by dividing the total amount of data processed by the Map/Reduce task by the duration. The following charts show the throughput as nodes are added to the cluster for these two scenarios:
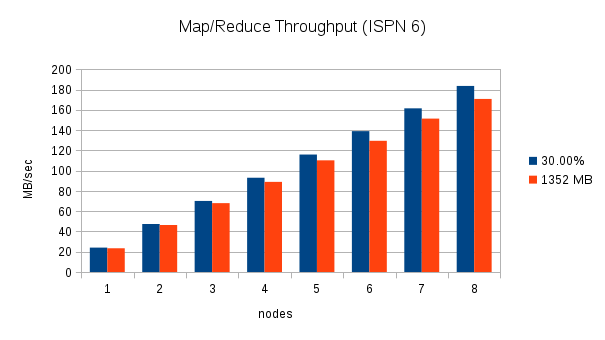

These charts clearly show the increase in throughput that were made in Infinispan 7. The throughput also seems to scale in an almost linear fashion for this word count scenario. With one node, Infinispan 7 processes the 30% of heap data in about 100 MB/sec, two nodes process almost 200 MB/sec, and 8 nodes process over 700 MB/sec.
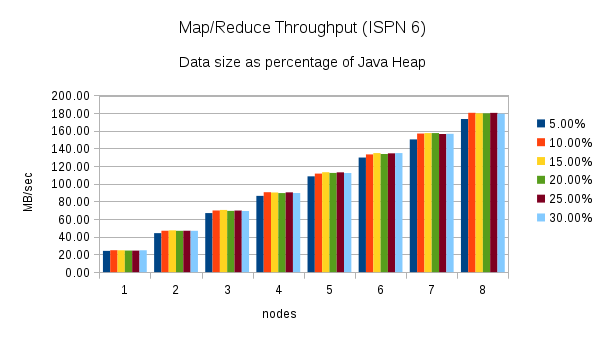
From 1 to 8 nodes using different heap size percentages
This test executes the word count task using different percentages of heap size as nodes are added to the cluster. (5%, 10%, 15%, 20%, 25%, and 30%) Here are the throughput results for this test:
 http://2.bp.blogspot.com/-fqmkYkxZtyI/U5AqS08Xk9I/AAAAAAAAACA/_wsTOmSbkdc/s1600/ISPN7_multi_ram_percent_throughput.png[
http://2.bp.blogspot.com/-fqmkYkxZtyI/U5AqS08Xk9I/AAAAAAAAACA/_wsTOmSbkdc/s1600/ISPN7_multi_ram_percent_throughput.png[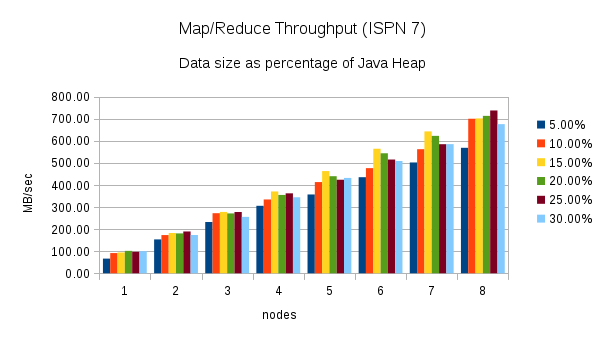 ]
]
Once again, these charts show an increase in throughput when performing the same word count task using Infinispan 7. The chart for Infinispan 7 shows more fluctuation in the throughput across the different percentages of heap size. The throughput plotted in the Infinispan 6 chart is more consistent.
From 1 to 8 nodes using different value sizes
This test executes the word count task using 30% of the heap size and different cache value sizes as nodes are added to the cluster. (1KB, 2KB, 4KB, 8KB, 16KB, 32KB, 64KB, 128KB, 256KB, 512KB, 1MB, and 2MB) Here are the throughput results for this test:
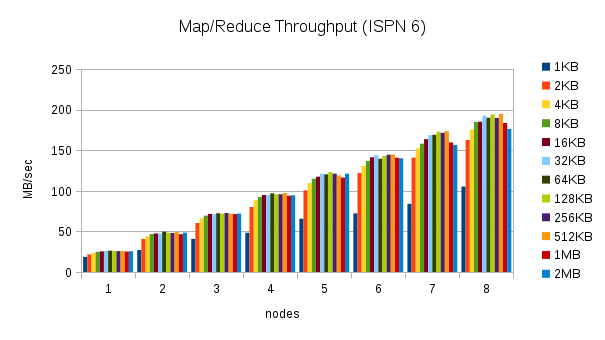
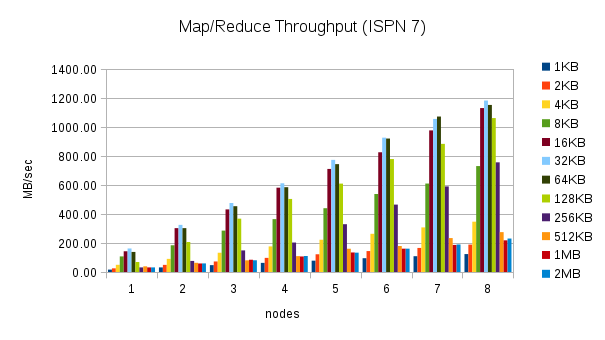
These results are more interesting. The throughput in Infinispan 7 is higher for certain cache size values, but closer to Infinispan 6 or even slower for other cache size values. The throughput peaks for 32KB cache values, but can be much lower for larger and smaller values. Smaller values require more overhead, but for larger values this behavior is not expected. This result needs to be investigated more closely.
Conclusion
The performance tests show that Infinispan 7 Map/Reduce improvements have increased the throughput and execution speed four to sixfold in some use cases. The changes have also allowed Infinispan 7 to process data sets that include larger intermediate results and produce larger final result maps. There are still areas of the Map/Reduce algorithm that need to be improved:
-
The Map/Reduce algorithm should be self-tuning. The maxCollectorSize parameter controls the number of values that the collector holds in memory, and it is not trivial to determine the optimal value for a given scenario. The value is based on the size of the values in the cache and the size of the intermediate results. A user is likely to know the size of the cache values, but currently Infinispan does not report statistics about the intermediate results to the user. The Map/Reduce algorithm should analyze the environment at runtime and adjust the size of the collector dynamically.
-
The fact that the throughput results vary with different value sizes needs to be investigated more closely. This could be due to the fact that the maxCollectorSize value used for these tests is not ideal for all value sizes, but there might be other causes for this behaviour.
Tags: radargun benchmarks performance map reduce
Monday, 16 September 2013
New persistence API in Infinispan 6.0.0.Alpha4
The existing CacheLoader/CacheStore API has been around since Infinispan 4.0. In this release of Infinispan we’ve taken a major step forward in both simplifying the integration with persistence and opening the door for some pretty significant performance improvements.
What’s new
So here’s what the new persistence integration brings to the table:
-
alignment with JSR-107: now we have a CacheWriter and CacheLoader interface similar to the the loader and writer in JSR 107, which should considerably help writing portable stores across JCache compliant vendors
-
simplified transaction integration: all the locking is now handled within the Infinispan layer, so implementors don’t have to be concerned coordinating concurrent access to the store (old LockSupportCacheStore is dropped for that reason).
-
parallel iteration: it is now possible to iterate over entries in the store with multiple threads in parallel. Map/Reduce tasks immediately benefit from this, as the map/reduce tasks now run in parallel over both the nodes in the cluster and within the same node (multiple threads)
-
reduced serialization (translated in less CPU usage): the new API allows exposing the stored entries in serialized format. If an entry is fetched from persistent storage for the sole purpose of being sent remotely, we no longer need to deserialize it (when reading from the store) and serialize it back (when writing to the wire). Now we can write to the wire the serialized format as read fro the storage directly
API
Now let’s take a look at the API in more detail:

The diagram above shows the main classes in the API:
-
-
abstracts the serialized form on an object
-
-
MarshalledEntry - abstracts the information held within a persistent store corresponding to a key-value added to the cache. Provides method for reading this information both in serialized (ByteBuffer) and deserialized (Object) format. Normally data read from the store is kept in serialized format and lazily deserialized on demand, within the MarshalledEntry implementation
-
CacheWriter and CacheLoader provide basic methods for reading and writing to a store
-
AdvancedCacheLoader and AdvancedCacheWriter provide operations to manipulate the underlaying storage in bulk: parallel iteration and purging of expired entries, clear and size.
A provider might choose to only implement a subset of these interfaces:
-
Not implementing the AdvancedCacheWriter makes the given writer not usable for purging expired entries or clear
-
Not implementing the AdvancedCacheLoader makes the information stored in the given loader not used for preloading, nor for the map/reduce iteration
If you’re looking at migrating your existing store to the new API, looking at the SingleFileStore for inspiration can be of great help.
Configuration
And finally, the way the stores are configured has changed:
-
the 5.x loaders element is now replaced with persistence
-
both the loaders and writers are configured through a unique store element (vs loader and store, as allowed in 5.x)
-
the preload and shared attributes are configured at each individual store, giving more flexibility when it comes to configuring multiple chained stores
Cheers,
Mircea
Tags: persistence jsr 107 loader store performance API
Thursday, 18 July 2013
Faster file cache store (no extra dependencies!) in 6.0.0.Alpha1
As announced yesterday by Adrian, the brand new Infinispan 6.0.0.Alpha1 release contains a new file-based cache store which needs no extra dependencies. This is essentially a replacement of the existing FileCacheStore which didn’t perform as expected, and caused major issues due to the number of files it created.
The new cache store, contributed by a Karsten Blees (who also contributed an improved asynchronous cache store), is called SingleFileCacheStore and it keeps all data in a single file. The way it looks up data is by keeping an in-memory index of keys and the positions of their values in this file. This design outperforms the existing FileCacheStore and even LevelDB based JNI cache store.
The classic case for a file based cache store is when you want to have a cache with a cache store available locally which stores data that has overflowed from memory, having exceeded size and/or time restrictions. We ran some performance tests to verify how fast different cache store implementations could deal with reading and writing overflowed data, and these are the results we got (in Ks):
-
FileCacheStore: 0.75k reads/s, 0.285k writes/s
-
LevelDB-JNI impl: 46k reads/s, 15.2k writes/s
-
SingleFileCacheStore: 458k reads/s, 137k writes/s
The difference is quite astonishing but as already hinted, this performance increase comes at a cost. Having to maintain an index of keys and positions in the file in memory has a cost in terms of extra memory required, and potential impact on GC. That’s why the SingleFileCacheStore is not recommended for use cases where the keys are too big.
In order to help tame this memory consumption issues, the size of the cache store can be optionally limited, providing a maximum number of entries to store in it. However, setting this parameter will only work in use cases where Infinispan is used as a cache. When used as a cache, data not present in Infinispan can be recomputed or re-retrieved from the authoritative data store and stored in Infinispan cache. The reason for this limitation is because once the maximum number of entries is reached, older data in the cache store is removed, so if Infinispan was used as an authoritative data store, it would lead to data loss which is not good.
Existing FileCacheStore users might wonder: what is it gonna happen to the existing FileCacheStore? We’re not 100% sure yet what we’re going to do with it, but we’re looking into some ways to migrate data from the FileCacheStore to the SingleFileCacheStore. Some interesting ideas have already been submitted which we’ll investigate in next Infinispan 6.0 pre-releases.
So, if you’re a FileCacheStore user, give the new SingleFileCacheStore a go and let us know how it goes! Switching from one to the other is easy :)
Cheers,
Galder
Tags: persistence alpha performance
Tuesday, 02 July 2013
Lower memory overhead in Infinispan 5.3.0.Final
Infinispan users worried about memory consumption should upgrade to Infinispan 5.3.0.Final as soon as possible, because as part of the work we’ve done to support storing byte arrays without wrappers, and the development of the interoperability mode, we’ve been working to reduce Infinispan’s memory overhead.
To measure overhead, we’ve used Martin Gencur’s excellent memory consumption tests. The results for entries with 512 bytes are:
Infinispan memory overhead, used in library mode: Infinispan 5.2.0.Final: ~151 bytes Infinispan 5.3.0.Final: ~135 bytes Memory consumption reduction: ~12%
Infinispan memory overhead, for the Hot Rod server: Infinispan 5.2.0.Final: ~174 bytes Infinispan 5.3.0.Final: ~151 bytes Memory consumption reduction: ~15%
Infinispan memory overhead, for the REST server: Infinispan 5.2.0.Final: ~208 bytes Infinispan 5.3.0.Final: ~172 bytes Memory consumption reduction: ~21%
Infinispan memory overhead, for the Memcached server:
Infinispan 5.2.0.Final: ~184 bytes
Infinispan 5.3.0.Final: ~180 bytes Memory consumption reduction: ~2%
This is great news for the Infinispan community but our effort doesn’t end here. We’ll be working on further improvements in next releases to bring down cost even further.
Cheers,
Galder
Tags: overhead memory performance
Saturday, 12 January 2013
Infinispan memory overhead
Have you ever wondered how much Java heap memory is actually consumed when data is stored in Infinispan cache? Let’s look at some numbers obtained through real measurement.
The strategy was the following:
1) Start Infinispan server in local mode (only one server instance, eviction disabled) 2) Keep calling full garbage collection (via JMX or directly via System.gc() when Infinispan is deployed as a library) until the difference in consumed memory by the running server gets under 100kB between two consecutive runs of GC 3) Load the cache with 100MB of data via respective client (or directly store in the cache when Infinispan is deployed as a library) 4) Keep calling the GC until the used memory is stabilised 5) Measure the difference between the final values of consumed memory after the first and second cycle of GC runs 6) Repeat steps 3, 4 and 5 four times to get an average value (first iteration ignored)
The amount of consumed memory was obtained from a verbose GC log (related JVM options: -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/tmp/gc.log)
The test output looks like this: https://gist.github.com/4512589
The operating system (Ubuntu) as well as JVM (Oracle JDK 1.6) were 64-bit. Infinispan 5.2.0.Beta6. Keys were kept intentionally small (10 character Strings) with byte arrays as values. The target entry size is a sum of key size and value size.
Memory overhead of Infinispan accessed through clients
==
HotRod client
entry size → overall memory
512B → 137144kB
1kB → 120184kB
10kB → 104145kB
1MB → 102424kB
So how much additional memory is consumed on top of each entry?
entry size/actual memory per entry → overhead per entry
512B/686B → ~174B
1kB(1024B)/1202B → ~178B
10kB(10240B)/10414B → ~176B
1MB(1048576B)/1048821B → ~245B
MemCached client (text protocol, SpyMemcached client)
entry size → overall memory
512B → 139197kB
1kB → 120517kB
10kB → 104226kB
1MB → N/A (SpyMemcached allows max. 20kB per entry)
entry size/actual memory per entry → overhead per entry
512B/696B → ~184B
1kB(1024B)/1205B → ~181B
10kB(10240B)/10422B → ~182B
==
REST client (Content-Type: application/octet-stream)
entry size → overall memory
512B → 143998kB
1kB → 122909kB
10kB → 104466kB
1MB → 102412kB
entry size/actual memory per entry → overhead per entry
512B/720B → ~208B
1kB(1024B)/1229B → ~205B
10kB(10240B)/10446B → ~206B
1MB(1048576B)/1048698B → ~123B
The memory overhead for individual entries seems to be more or less constant across different cache entry sizes.
Memory overhead of Infinispan deployed as a library
Infinispan was deployed to JBoss Application Server 7 using Arquillian.
entry size → overall memory/overall with storeAsBinary
512B → 132736kB / 132733kB
1kB → 117568kB / 117568kB
10kB → 103953kB / 103950kB
1MB → 102414kB / 102415kB
There was almost no difference in overall consumed memory when enabling or disabling storeAsBinary.
entry size/actual memory per entry→ overhead per entry (w/o storeAsBinary)
512B/663B → ~151B
1kB(1024B)/1175B → ~151B
10kB(10240B)/10395B → ~155B
1MB(1048576B)/1048719B → ~143B
As you can see, the overhead per entry is constant across different entry sizes and is ~151 bytes.
Conclusion
The memory overhead is slightly more than 150 bytes per entry when storing data into the cache locally. When accessing the cache via remote clients, the memory overhead is a little bit higher and ranges from ~170 to ~250 bytes, depending on remote client type and cache entry size. If we ignored the statistics for 1MB entries, which could be affected by a small number of entries (100) stored in the cache, the range would have been even narrower.
Cheers, Martin
Tags: overhead memory performance
Tuesday, 04 September 2012
Speeding up Cache calls with IGNORE_RETURN_VALUES invocation flag
Starting with Infinispan 5.2.0.Alpha3, a new Infinispan invocation flag has been added called IGNORE_RETURN_VALUES.
This flag signals that the client that calls an Infinispan Cache operation () which has some kind of return, i.e. java.util.Map#put(Object, Object) (remember that Infinispan’s Cache interface extends java.util.Map), the return value (which in the case of java.util.Map#put(Object, Object) represents the previous value) will be ignored by the client application. A typical client application that ignores the return value would use code like this:
In this example, both cache put call are ignoring the return of the put call, which returns the previous value. In other words, when we cache the last login date, we don’t care what the previous value was, so this is a great opportunity for the client code to be re-written in this way:
Or even better:
Thanks to such hints, Infinispan caches can behave in a more efficient way and can potentially do operations faster, because work associated with the production of the return value will be skipped. Such work can on occasions involve network calls, or access to persistent cache stores, so by avoiding this work, the cache calls are effectively faster.
In previous Infinispan versions, a similar effect could be achieved with flags with a narrower target and which are considered too brittle for end user consumption such as SKIP_REMOTE_LOOKUP or SKIP_CACHE_LOAD. So, if you’re using either of these flags in your Infinispan client codebase, we highly recommend that from Infinispan 5.2.0.Alpha3 you start using IGNORE_RETURN_VALUES instead.
Cheers, Galder
Tags: flags performance
Wednesday, 28 March 2012
Infinispan 5.1.3.FINAL is here!
Infinispan 5.1.3.FINAL is out now after having received very positive feedback on 5.1.3.CR1 and fixing some other issues on top of that, such as the file cache store leaving files open, improving standalone Infinispan Memcached implementation performance, and including Infinispan CDI extension jars in our distribution.
"Release early, release often", that’s out motto, so we’ll carry on taking feedback onboard and releasing new Infinispan versions where we improve on what we’ve done in the past apart from coming out with new goodies.
Thanks to everyone, both users who have been getting in touch to provide their feedback and developers who have been quickly reacting to users fixing issues and implementing requested features.
Full details of what has been fixed in FINAL (including CR1) can be found here, and if you have feedback, please visit our forums. Finally, as always, you can download the release from here.
Cheers, Galder
Tags: release memcached cdi final performance