Wednesday, 05 August 2015
RadarGun 2.1.0.Final
I’m happy to announce RadarGun 2.1.0.Final is officialy out. RadarGun is a multi purpose testing tool, which provides means to measure performance and test features specific to distributed systems (data grids, caches in particular).
The release contains multiple fixes and improvements listed below:
-
New plugins: jdg65, infinispan71, infinispan72, infinispan80, jcache
-
Reporting improvements (perfrepo reporter, percentile chart, net/gross throughput)
-
GaussianKeySelector
-
Enhanced listener support
-
JMX invocation stage now supports setting attributes
-
LogLogic improvements
-
Enanced TopologyHistory & WaitForTopologySettle stage
-
Better test coverage
-
Multiple bug fixes
From this point on, the main development will continue in 3.x line. We are preparing considerable design changes, so that RadarGun can be easily utilized to measure performance of other areas as well (e.g. JPA).
For more information about RadarGun, feel free to visit our wiki page, or try five minute tutorial. In case of any issues, please refer to our issue tracker.
Thanks everyone for their contributions!
Tags: radargun release
Thursday, 05 June 2014
Map/Reduce Performance improvements between Infinispan 6 and 7
Introduction
There have been a number of recent Infinispan 7.0 Map/Reduce performance related improvements that we were eager to test in our performance lab and subsequently share with you. The results are more than promising. In the word count use case, Map/Reduce task execution speed and throughput improvement is between fourfold and sixfold in certain situations that were tested.
We have achieved these improvements by focusing on:
-
Optimized mapper/reducer parallel execution on all nodes
-
Improving the handling and processing of larger data sets
-
Reducing the amount of memory needed for execution of MapReduceTask
Performance Test Results
The performance tests were run using the following parameters:
-
An Infinispan 7.0.0-SNAPSHOT build created after the last commits from the list were committed to the Infinispan GIT repo on May 9th vs Infinispan 6.0.1.Final
-
OpenJDK version 1.7.0_55 with 4GB of heap and the following JVM options:
-
Random data filled 30% of the Java heap, and 100 random words were used to create the 8 kilobyte cache values. The cache keys were generated using key affinity, so that the generated data would be distributed evenly in the cache. These values were chosen, so that a comparison to Infinispan 6 could be made. Infinispan 7 can handle a final result map with a much larger set of keys than is possible in Infinispan 6. The actual amount of heap size that is used for data will be larger due to backup copies, since the cluster is running in distributed mode.
-
The MapReduceTask executes a word count against the cache values using mapper, reducer, combiner, and collator implementations. The collator returns the 10 most frequently occurring words in the cache data. The task used a distributed reduce phase and a shared intermediate cache. The MapReduceTask is executed 10 times against the data in the cache and the values are reported as an average of these durations.
From 1 to 8 nodes using a fixed amount of data and 30% of the heap
This test executes two word count executions on each cluster with an increasing number of nodes. The first execution uses an increasing amount of data equal to 30% of the total Java heap across the cluster (i.e. With one node, the data consumes 30% of 4 GB. With two nodes, the data consumes 30% of 8 GB, etc.), and the second execution uses a fixed amount of data, (1352 MB which is approximately 30% of 4 GB). Throughput is calculated by dividing the total amount of data processed by the Map/Reduce task by the duration. The following charts show the throughput as nodes are added to the cluster for these two scenarios:
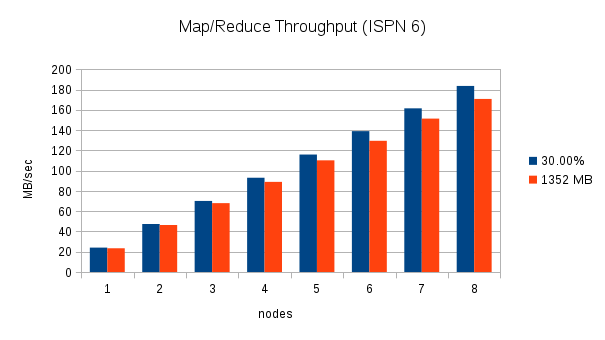

These charts clearly show the increase in throughput that were made in Infinispan 7. The throughput also seems to scale in an almost linear fashion for this word count scenario. With one node, Infinispan 7 processes the 30% of heap data in about 100 MB/sec, two nodes process almost 200 MB/sec, and 8 nodes process over 700 MB/sec.
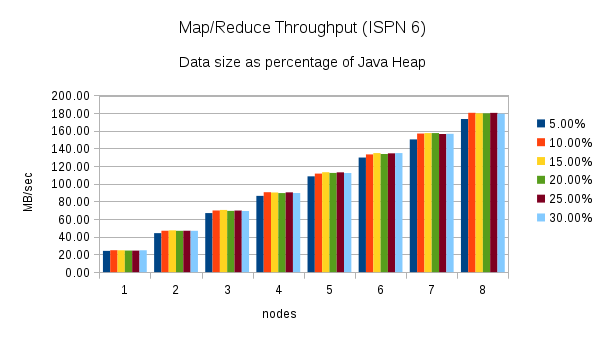
From 1 to 8 nodes using different heap size percentages
This test executes the word count task using different percentages of heap size as nodes are added to the cluster. (5%, 10%, 15%, 20%, 25%, and 30%) Here are the throughput results for this test:
 http://2.bp.blogspot.com/-fqmkYkxZtyI/U5AqS08Xk9I/AAAAAAAAACA/_wsTOmSbkdc/s1600/ISPN7_multi_ram_percent_throughput.png[
http://2.bp.blogspot.com/-fqmkYkxZtyI/U5AqS08Xk9I/AAAAAAAAACA/_wsTOmSbkdc/s1600/ISPN7_multi_ram_percent_throughput.png[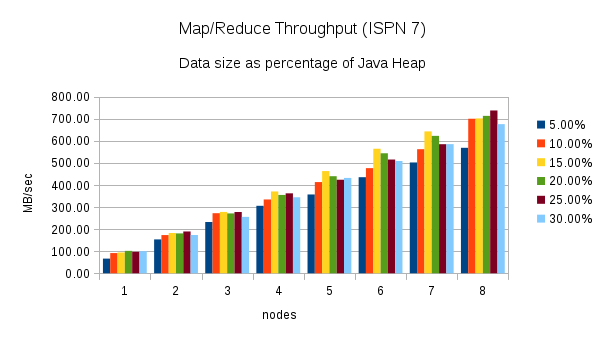 ]
]
Once again, these charts show an increase in throughput when performing the same word count task using Infinispan 7. The chart for Infinispan 7 shows more fluctuation in the throughput across the different percentages of heap size. The throughput plotted in the Infinispan 6 chart is more consistent.
From 1 to 8 nodes using different value sizes
This test executes the word count task using 30% of the heap size and different cache value sizes as nodes are added to the cluster. (1KB, 2KB, 4KB, 8KB, 16KB, 32KB, 64KB, 128KB, 256KB, 512KB, 1MB, and 2MB) Here are the throughput results for this test:
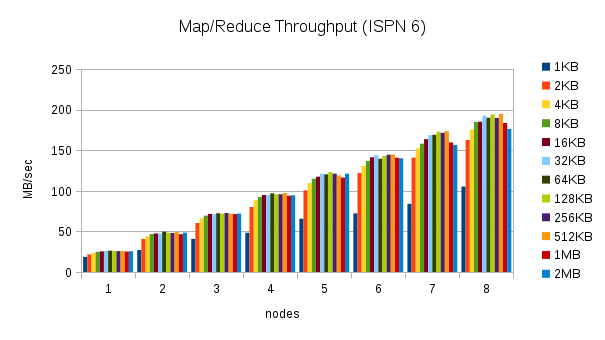
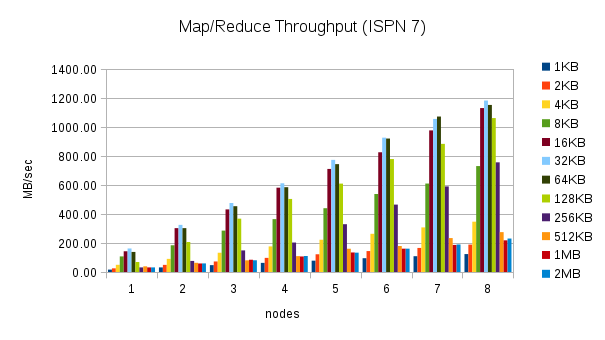
These results are more interesting. The throughput in Infinispan 7 is higher for certain cache size values, but closer to Infinispan 6 or even slower for other cache size values. The throughput peaks for 32KB cache values, but can be much lower for larger and smaller values. Smaller values require more overhead, but for larger values this behavior is not expected. This result needs to be investigated more closely.
Conclusion
The performance tests show that Infinispan 7 Map/Reduce improvements have increased the throughput and execution speed four to sixfold in some use cases. The changes have also allowed Infinispan 7 to process data sets that include larger intermediate results and produce larger final result maps. There are still areas of the Map/Reduce algorithm that need to be improved:
-
The Map/Reduce algorithm should be self-tuning. The maxCollectorSize parameter controls the number of values that the collector holds in memory, and it is not trivial to determine the optimal value for a given scenario. The value is based on the size of the values in the cache and the size of the intermediate results. A user is likely to know the size of the cache values, but currently Infinispan does not report statistics about the intermediate results to the user. The Map/Reduce algorithm should analyze the environment at runtime and adjust the size of the collector dynamically.
-
The fact that the throughput results vary with different value sizes needs to be investigated more closely. This could be due to the fact that the maxCollectorSize value used for these tests is not ideal for all value sizes, but there might be other causes for this behaviour.
Tags: radargun benchmarks performance map reduce
Wednesday, 09 November 2011
Single lock owner: an important step forward
The single lock owner is a highly requested Infinispan improvement. The basic idea behind it is that, when writing to a key, locks are no longer acquired on all the nodes that own that key, but only on a single designated node (named "main owner").
How does it help me?
Short version: if you use transactions that concurrently write to the same keys, this improvement significantly increases your system' throughput.
Long version: If you’re using Infinispan with transactions that modify the same key(s) concurrently then you can easily end up in a deadlock. A deadlock can also occur if two transaction modify the same key at the same time - which is both inefficient and counter-intuitive. Such a deadlock means that at one transaction(or both) eventually rollback but also the lock on the key is held for the duration of a lockAquistionTimout config option (defaults to 10 seconds). These deadlocks reduces the throughput significantly as transactions threads are held inactive during deadlock time. On top of that, other transactions that want to operate on that key are also delayed, potentially resulting in a cascade effect.
What’s the added performance penalty?
The only encountered performance penalty is during cluster topology changes. At that point the cluster needs to perform some additional computation (no RPC involved) to fail-over the acquired locks from previous to new owners. Another noticeable aspect is that locks are now being released asynchronously, after the transaction commits. This doesn’t add any burden to the transaction duration, but it means that locks are being held slightly longer. That’s not something to be concerned about if you’re not using transactions that compete for same locks though. We plan to benchmark this feature using Radargun benchmark tool - we’ll report back!
Want to know more?
You can read the single lock owner design wiki or/and follow the JIRA JIRA discussions.
Tags: radargun transactions locking deadlock detection
Wednesday, 10 August 2011
Transactions enhancements in 5.0
Besides other cool features such as Map reduce and distributed executors, Infinispan 5.0.0 "Pagoa" brings some significant improvements around transactional functionality:
-
transaction recovery http://community.jboss.org/docs/DOC-16646?uniqueTitle=false is now supported, with a set of tools that allow state reconciliation in case the transaction fails during 2nd phase of 2PC. This is especially useful in the case of transactions spreading over Infinispan and another resource manager, e.g. a database (distributed transactions). You can find out more on how to enable and use transaction recovery here.
-
Synchronization enlistment is another important feature in this release. This allows Infinispan to enlist in a transaction as an Synchronization rather than an XAResource.This enlistment allows the TransactionManager to optimize 2PC with a 1PC where only one other resource is enlisted with that transaction (last resource commit optimization). This is particularly important when using Infinispan as a 2nd level cache in Hibernate. You can read more about this feature here.
-
besides that several bugs were fixed particularly when it comes to the integration with a transaction manager - BIG thanks to the community for reporting and testing them!
To summarise, Infinispan can participate in a transaction in 3 ways:
-
as a fully fledged XAResource that supports recovery
-
as an XAResource, but without recovery. This is the default configuration
-
and as an Synchronization
In order to analyze the performance of running Infinispan in different transactional modes I’ve enhanced and used Radargun. The diagram below shows a performance comparison between running Infinispan in all the 3 modes described. The forth plot in the chart shows the performance of running Infinispan without transactions - this gives an idea about the cost of using transactions vs. raw operations.

The benchmark was run on this Radargun configuration, using Infinispan 5.0.0.CR5 configured as shown here. As a TransactionManager JBossTS 4.15.0.FINAL was used, configured with a VolatileStore as shown here. Each node was an 4-core Intel® Xeon® CPU E5640 @ 2.67GHz, with 4GB RAM.
Each transaction spread over only one put operation. The chart shows the following:
-
a non-transactional put is about 40% faster than a transactional one
-
Synchronization-enlisted transactions outperform an XAResource enlisted one by about 20%
-
A recoverable cache has about the same performance as a non-recoverable cache when it comes to transactions.
And that’s not all! During Infinispan 5.0.0 development we’ve been thinking a lot about how we can improve transactional throughput, especially in scenarios in which multiple transactions are writing on the same key. As a result we’ve come up with some improvement suggestions summarised here: please feel free to take a look and comment!
Cheers,
Mircea
Tags: jta radargun transactions benchmarks
Friday, 17 December 2010
Announcing project Radargun
Hi all,
Radargun is a tool we’ve developed and used for benchmarking Infinispan’s performance both between releases and compared with other similar products. Initially we shipped under the (poorly named) Cache Benchmark Framework. Due to increase community interest and the fact that this reached a certain maturity (we used it for benchmarking 100+ nodes clusters) we decided to revamp it a little and also come with another name: Radargun. You can read more about it here. A good start is the 5MinutesTutorial.
Cheers, Mircea
Tags: radargun benchmarks cache benchmark framework