Wednesday, 01 March 2017
Checking Infinispan cluster health and Kubernetes/OpenShift
Modern applications and microservices often need to expose their health status. A common example is Spring Actuator but there are also many different ways of doing that.
Starting from Infinispan 9.0.0.Beta2 we introduced the HealthCheck API. It is accessible in both Embedded and Client/Server mode.
Cluster Health and Embedded Mode
The HealthCheck API might be obtained directly from EmbeddedCacheManager and it looks like this:
The nice thing about the API is that it is exposed in JMX by default:
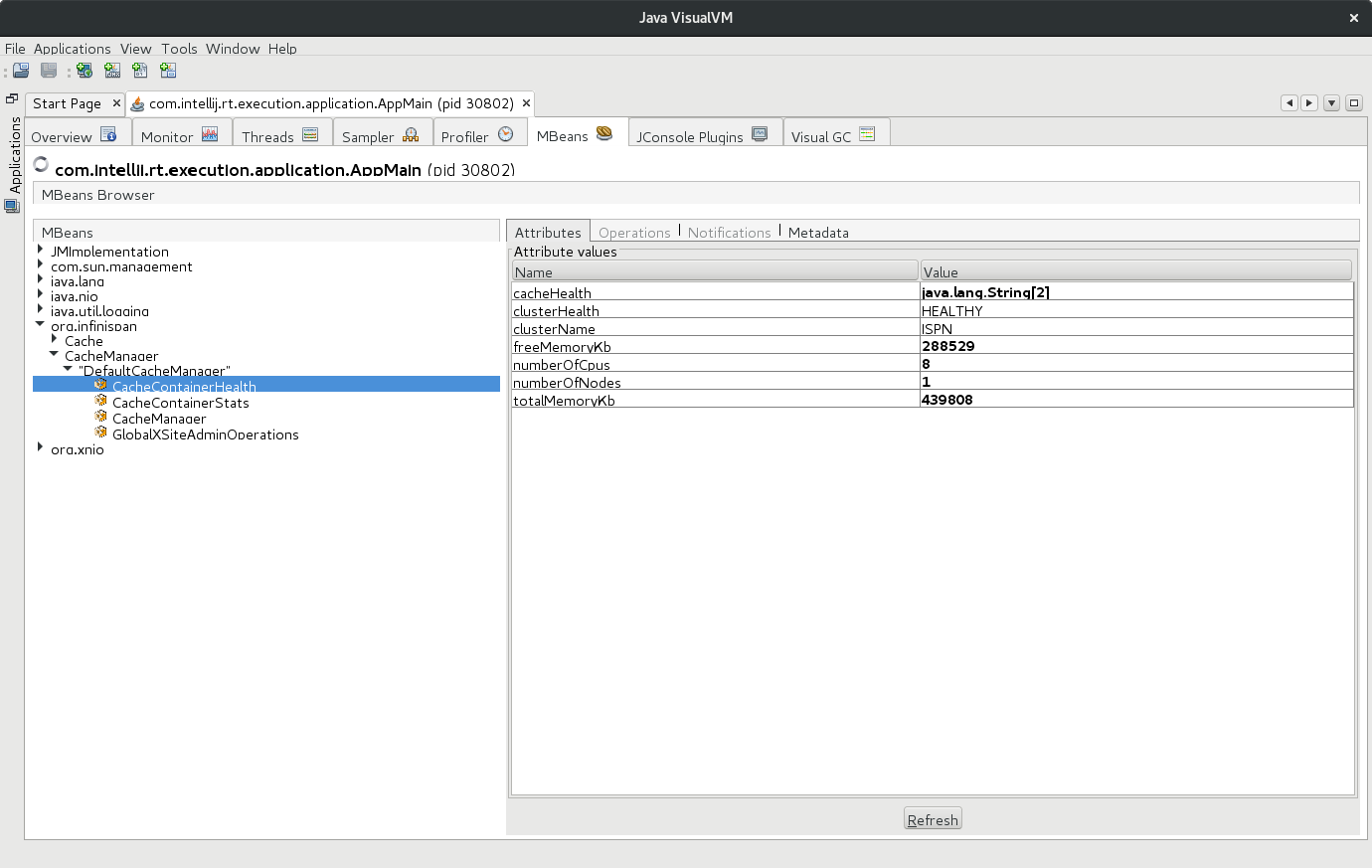
More information about using HealthCheck API in Embedded Mode might be found here:
Cluster Health and Server Mode
Since Infinispan is based on Wildfly, we decided to use CLI as well as built-in Management REST interface.
Here’s an example of checking the status of a running server:
Querying the HealthCheck API using the Management REST is also very simple:
Note that for the REST endpoint, you have to use proper credentials.
More information about the HealthCheckA API in Server Mode might be found here:
Cluster Health and Kubernetes/OpenShift
Monitoring cluster health is crucial for Clouds Platforms such as Kubernetes and OpenShift. Those Clouds use a concept of immutable Pods. This means that every time you need change anything in your application (changing configuration for the instance), you need to replace the old instances with new ones. There are several ways of doing that but we highly recommend using Rolling Updates. We also recommend to tune the configuration and instruct Kubernetes/OpenShift to replace Pods one by one (I will show you an example in a moment).
Our goal is to configure Kubernetes/OpenShift in such a way, that each time a new Pod is joining or leaving the cluster a State Transfer is triggered. When data is being transferred between the nodes, the Readiness Probe needs to report failures and prevent Kubernetes/OpenShift from doing progress in Rolling Update procedure. Once the cluster is back in stable state, Kubernetes/OpenShift can replace another node. This process loops until all nodes are replaced.
Luckily, we introduced two scripts in our Docker image, which can be used out of the box for Liveness and Readiness Probes:
At this point we are ready to put all the things together and assemble DeploymentConfig:
Interesting parts of the configuration:
-
lines 13 and 14: We allocate additional capacity for the Rolling Update and allow one Pod to be down. This ensures Kubernetes/OpenShift replaces nodes one by one.
-
line 44: Sometimes shutting a Pod down takes a little while. It is always better to wait until it terminates gracefully than taking the risk of losing data.
-
lines 45 - 53: The Liveness Probe definition. Note that when a node is transferring the data it might highly occupied. It is wise to set higher value of 'failureThreshold'.
-
lines 54 - 62: The same rule as the above. The bigger the cluster is, the higher the value of 'successThreshold' as well as 'failureThreshold'.
Feel free to checkout other articles about deploying Infinispan on Kubernetes/OpenShift:
-
http://blog.infinispan.org/2016/08/running-infinispan-cluster-on-openshift.html
-
http://blog.infinispan.org/2016/08/running-infinispan-cluster-on-kubernetes.html
-
http://blog.infinispan.org/2016/09/configuration-management-on-openshift.html
-
http://blog.infinispan.org/2016/10/openshift-and-node-affinity.html
-
http://blog.infinispan.org/2016/07/bleeding-edge-on-docker.html
Tags: openshift kubernetes state transfer health