Monday, 31 August 2020
Non Blocking Saga
As many you are probably aware recent trends have shown that making applications non blocking provides quite a few benefits allowing for greater scalability with less resources. Infinispan has been written and rewriting parts to take advantage of this as we can for both embedded and server use cases.
Before Infinispan 11
The Infinispan Server has always utilized netty, however we may not have been the best about ensuring we didn’t block the event loop. The HotRod Client in 9.2.0 also utilizes netty to provide for non blocking operations. The internal embedded interceptors were rewritten in 9.0.0 to provide for non blocking support for internal cache operations, which include put/get. Cache store operations in 10.0.0 were offloaded to a blocking thread pool to provide non blocking support.
Infinispan 11 Non Blocking Changes
With the newest release we have rewritten lots of the internals of Infinispan to take advantage of non blocking as much as possible. The amount of changes is quite large and a bit hard to describe them all in this blog post. The various JIRA can be seen from https://issues.redhat.com/browse/ISPN-10309, which isn’t even complete yet despite how many different changes we have done.
The persistence SPI was completely rewritten in 11 with non blocking in mind as well and this will be covered in a future post as it has much more detailing it. For now you can rest assure that all prior stores will still work, however they may have or can be optimized to take into account non blocking support.
Conversions
Pretty much every module in the Infinispan code base has been changed to support non blocking. If code relies upon an API that is blocking that is known to be blocking, we offload those calls to a blocking thread pool to ensure we never block the non blocking thread.
Unfortunately some modules have not yet been updated and those are ones related to query. Query is in the middle of a giant refactoring and doing so would have caused massive conflicts and thus has been delayed to Infinispan 12. The server works around this by ensuring write operations performed upon a cache with query are always done in a blocking thread to ensure safety.
Thread Pools
Infinispan utilizes various thread pools for handling of operations. This table details how many thread pools each version of Infinispan can have.
| Version | Embedded | Server |
|---|---|---|
ISPN 10 | 5 | 7 |
ISPN 11 | 2 | 3 |
As you can see there is more than a 50 percent reduction of the number of thread pools in both embedded and server modes. This in turn has allowed for a reduction of the default number of threads as well as seen in the next table. Note that N is how many cores that are available to the JVM.
| Version | Embedded | Server |
|---|---|---|
ISPN 10 | 310 + N | 470 + (2 * N) |
ISPN 11 | 150 + (2 * N) | 150 + (4 * N) |
After this consolidation we have non blocking and blocking thread pools. As you can see this allows us to reduce the maximum number of threads in embedded by about half and the server to a third of what it used to be before.
The server has an additional thread pool for the netty event loop and unfortunately we cannot consolidate this thread pool, but it is planned for Infinispan 12, which will get us to the same number of threads and thread pools for both embedded and server modes.
Note that this doesn’t talk about the JGroups thread pool as this is unchanged and is the same.
BlockHound
If you are familiar with making code non blocking it can be a very difficult task as even the most mundane call can be hiding something blocking, even if it is very brief. We could write something to do detect such calls, but there is already an open source tool that does exactly what we needed. This tool is BlockHound, which can detect blocking calls at runtime. More information about it can be found at https://github.com/reactor/BlockHound.
Infinispan takes advantage of blockhound in that we configure it at the module level. This allows the end user to even add block hound with Infinispan in embedded mode and it should work to test out to ensure that interactions with Infinispan are not blocking when needed. Note that we do not yet support block hound for the client, despite many methods are not blocking today.
What remains for Infinispan 12
Infinispan 12 should bring the entire non blocking saga to its hopfully final completion.
The aforementioned query modules need to be revamped
Existing supported cache stores need to be rewritten to directly support non blocking
Cache retrieval needs to be offloaded to a blocking thread
Combine server event loop with non blocking thread pool
Tags: non-blocking server embedded
Tuesday, 28 July 2020
Infinispan Server Tutorial
Dear Infinispan community,
If you are wondering how to start with Infinispan Server from your Java Application, a new Tutorial is available. This tutorial covers the essentials to get started with Infinispan Server and takes around half an hour to complete.
In this tutorial you will learn how to:
-
Run Infinispan Server.
-
Access and use the Infinispan Console.
-
Create Infinispan caches.
-
Read and write data as primitive types and Java objects.
-
Add lifespans to entries so data expires.
-
Deploy client listeners to get event notifications.
-
Search the data store for specific values.
-
Use out-of-the-box testing with Junit 5 for verification.
Complete the tutorial, ask us anything about it, give us feedback and feel free to share it!
Get it, Use it, Ask us!
Please download, report bugs, chat with us, ask questions on StackOverflow.
Tags: tutorial learning server
Thursday, 04 June 2020
Secure server by default
The Infinispan server we introduced in 10.0 exposes a single port through which both Hot Rod and HTTP clients can connect.
While Infinispan has had very extensive security support since 7.0, the out-of-the-box default configuration did not enable authentication.
Infinispan 11.0’s server’s default configuration, instead, requires authentication. We have made several improvements to how authentication is configured and the tooling we provide to make the experience as smooth as possible.
Automatic authentication mechanism selection
Previously, when enabling authentication, you had to explicitly define which mechanisms had to be enabled per-protocol, with all of the peculiarities specific to each one (i.e. SASL for Hot Rod, HTTP for REST). Here is an example configuration with Infinispan 10.1 that enables DIGEST authentication:
<endpoints socket-binding="default" security-realm="default">
<hotrod-connector name="hotrod">
<authentication>
<sasl mechanisms="DIGEST-MD5" server-name="infinispan"/>
</authentication>
</hotrod-connector>
<rest-connector name="rest">
<authentication mechanisms="DIGEST"/>
</rest-connector>
</endpoints>In Infinispan 11.0, the mechanisms are automatically selected based on the capabilities of the security realm. Using the following configuration:
<endpoints socket-binding="default" security-realm="default">
<hotrod-connector name="hotrod" />
<rest-connector name="rest"/>
</endpoints>together with a properties security realm, will enable DIGEST for HTTP and SCRAM-*, DIGEST-* and CRAM-MD5 for Hot Rod. BASIC/PLAIN will only be implicitly enabled when the security realm has a TLS/SSL identity.
The following tables summarize the mapping between realm type and implicitly enabled mechanisms.
| Security Realm | SASL Authentication Mechanism |
|---|---|
Property Realms and LDAP Realms | SCRAM-*, DIGEST-*, CRAM-MD5 |
Token Realms | OAUTHBEARER |
Trust Realms | EXTERNAL |
Kerberos Identities | GSSAPI, GS2-KRB5 |
SSL/TLS Identities | PLAIN |
| Security Realm | HTTP Authentication Mechanism |
|---|---|
Property Realms and LDAP Realms | DIGEST |
Token Realms | BEARER_TOKEN |
Trust Realms | CLIENT_CERT |
Kerberos Identities | SPNEGO |
SSL/TLS Identities | BASIC |
Automatic encryption
If the security realm has a TLS/SSL identity, the endpoint will automatically enable TLS for all protocols.
Encrypted properties security realm
The properties realm that is part of the default configuration has been greatly improved in Infinispan 11. The passwords are now stored in multiple encrypted formats in order to support the various DIGEST, SCRAM and PLAIN/BASIC mechanisms.
The user functionality that is now built into the CLI allows easy creation and manipulation of users, passwords and groups:
[disconnected]> user create --password=secret --groups=admin admin
[disconnected]> connect --username=admin --password=secret
[ispn-29934@cluster//containers/default]> user ls
[ "admin" ]
[ispn-29934@cluster//containers/default]> user describe admin
{ username: "admin", realm: "default", groups = [admin] }
[ispn-29934@cluster//containers/default]> user password admin
Set a password for the user: ******
Confirm the password for the user: ******
[ispn-29934@cluster//containers/default]>Authorization: simplified
Authorization is another security aspect of Infinispan. In previous versions, setting up authorization was complicated by the need to add all the needed roles to each cache:
<infinispan>
<cache-container name="default">
<security>
<authorization>
<identity-role-mapper/>
<role name="AdminRole" permissions="ALL"/>
<role name="ReaderRole" permissions="READ"/>
<role name="WriterRole" permissions="WRITE"/>
<role name="SupervisorRole" permissions="READ WRITE EXEC BULK_READ"/>
</authorization>
</security>
<distributed-cache name="secured">
<security>
<authorization roles="AdminRole ReaderRole WriterRole SupervisorRole"/>
</security>
</distributed-cache>
</cache-container>
...
</infinispan>With Infinispan 11 you can avoid specifying all the roles at the cache level: just enable authorization and all roles will implicitly apply. As you can see, the cache definition is much more concise:
<infinispan>
<cache-container name="default">
...
<distributed-cache name="secured">
<security>
<authorization/>
</security>
</distributed-cache>
</cache-container>
...
</infinispan>Conclusions
Tags: server security
Thursday, 28 May 2020
CLI enhancements
One of the key aspects of our new server architecture is the management API exposed through the single port.
While I’m sure there will be those of you who like to write scripts with plenty of curl/wget magic, and those who prefer the comfort of our new web console, the Infinispan CLI offers a powerful tool which combines the power of the former with the usability of the latter.
During the Infinispan 11 development cycle, the CLI has received numerous enhancements. Let’s look at some of them !
User management
When using the built-in properties-based security realm, you had to use the user-tool script to manage users, passwords and groups. That functionality has now been built into the CLI:
[disconnected]> user create --password=secret --groups=admin john
[disconnected]> connect --username=joe --password=secret
[infinispan-29934@cluster//containers/default]>Remote logging configuration
You can now modify the server logging configuration from the CLI. For example, to enable TRACE logging for the org.jgroups category, use the following:
[infinispan-29934@cluster//containers/default]> logging set --level=TRACE org.jgroups| logging configuration changes are volatile, i.e. they will be lost when restarting a node. |
Server report
To help with debugging issues, the server now implements an aggregate log which includes information such as a thread dump, memory configuration, open sockets/files, etc.
[bespin-29934@cluster//containers/default]> server report
Downloaded report 'infinispan-bespin-29934-20200522114559-report.tar.gz'| this feature currently only works on Linux/Unix systems. |
Real CLI mode
It is now possible to invoke all CLI commands directly from the command-line, without having to resort to interactive mode or a batch. For example:
cli.sh user create --password=secret --groups=admin johnNative CLI
The CLI can now be built as a native executable, courtesy of GraalVM's native-image tool. We will soon be shipping binaries/images of this, so look out for an announcement.
Tags: cli server management administration logging
Thursday, 20 February 2020
Infinispan Server configuration
The new Infinispan Server introduced in version 10.0 is quite different from the WildFly-based one we had up to 9.x. One of the big differences is that the new server’s configuration is just an extension of the embedded configuration.
The XML snippet below shows the configuration used by the server "out-of-the-box":
<infinispan
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:10.1 https://infinispan.org/schemas/infinispan-config-10.1.xsd
urn:infinispan:server:10.1 https://infinispan.org/schemas/infinispan-server-10.1.xsd"
xmlns="urn:infinispan:config:10.1"
xmlns:server="urn:infinispan:server:10.1">
<cache-container name="default" statistics="true"> (1)
<transport cluster="${infinispan.cluster.name}" stack="${infinispan.cluster.stack:tcp}" node-name="${infinispan.node.name:}"/>
</cache-container>
<server xmlns="urn:infinispan:server:10.1"> (2)
<interfaces>
<interface name="public"> (3)
<inet-address value="${infinispan.bind.address:127.0.0.1}"/>
</interface>
</interfaces>
<socket-bindings default-interface="public" port-offset="${infinispan.socket.binding.port-offset:0}"> (4)
<socket-binding name="default" port="${infinispan.bind.port:11222}"/>
<socket-binding name="memcached" port="11221"/>
</socket-bindings>
<security> (5)
<security-realms>
<security-realm name="default">
<!-- Uncomment to enable TLS on the realm -->
<!-- server-identities>
<ssl>
<keystore path="application.keystore" relative-to="infinispan.server.config.path"
keystore-password="password" alias="server" key-password="password"
generate-self-signed-certificate-host="localhost"/>
</ssl>
</server-identities-->
<properties-realm groups-attribute="Roles">
<user-properties path="users.properties" relative-to="infinispan.server.config.path" plain-text="true"/>
<group-properties path="groups.properties" relative-to="infinispan.server.config.path" />
</properties-realm>
</security-realm>
</security-realms>
</security>
<endpoints socket-binding="default" security-realm="default"> (6)
<hotrod-connector name="hotrod"/>
<rest-connector name="rest"/>
</endpoints>
</server>
</infinispan>Let’s have a look at the various elements, describing their purposes:
| 1 | The cache-container element is a standard Infinispan cache manager configuration like you’d use in embedded deployments. You can decide to leave it empty and create any caches at runtime using the CLI, Console or Hot Rod and RESTful APIs, or statically predefine your caches here. |
| 2 | The server element holds the server-specific configuration which includes network, security and protocols. |
| 3 | The interface element declares named interfaces which are associated with specific addresses/interfaces. The default public interface will use the loopback address 127.0.0.1 unless overridden with the -b switch or the infinispan.bind.address system property. Refer to server interfaces documentation for a detailed list of all possible ways of selecting an address. |
| 4 | The socket-bindings element associates addresses and ports with unique names you can use later on configuring the protocol endpoints. For convenience, a port offset can be added to all port numbers to ease starting multiple servers on the same host. Use the -o switch or the infinispan.socket.binding.port-offset system property to change the offset. |
| 5 | The security element configures the server’s realms and identities. We will ignore this for now as this deserves its own dedicated blog post in the near future. |
| 6 | The endpoints element configures the various protocol servers. Unless overridden, all sub protocols are aggregated into a single-port endpoint which, as its name suggests, listens on a single port and automatically detects the incoming protocol, delegating to the appropriate handler. |
The rest-connector has a special role in the new server, since it now also handles administrative tasks. It is therefore required if you want to use the CLI or the Console. You may wish to have the protocols listen on different ports, as outlined in the configuration below:
<infinispan
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:10.1 https://infinispan.org/schemas/infinispan-config-10.1.xsd
urn:infinispan:server:10.1 https://infinispan.org/schemas/infinispan-server-10.1.xsd"
xmlns="urn:infinispan:config:10.1"
xmlns:server="urn:infinispan:server:10.1">
<cache-container name="default" statistics="true">
<transport cluster="${infinispan.cluster.name}" stack="${infinispan.cluster.stack:tcp}" node-name="${infinispan.node.name:}"/>
</cache-container>
<server xmlns="urn:infinispan:server:10.1">
<interfaces>
<interface name="public">
<match-interface value="eth0"/>
</interface>
<interface name="admin">
<loopback/>
</interface>
</interfaces>
<socket-bindings default-interface="public" port-offset="${infinispan.socket.binding.port-offset:0}">
<socket-binding name="public" port="${infinispan.bind.port:11222}"/>
<socket-binding name="admin" interface="admin" port="${infinispan.bind.port:11222}"/>
</socket-bindings>
<security>
<security-realms>
<security-realm name="default">
<properties-realm groups-attribute="Roles">
<user-properties path="users.properties" relative-to="infinispan.server.config.path" plain-text="true"/>
<group-properties path="groups.properties" relative-to="infinispan.server.config.path" />
</properties-realm>
</security-realm>
</security-realms>
</security>
<endpoints socket-binding="admin" security-realm="default">
<hotrod-connector name="hotrod" socket-binding="public"/>
<rest-connector name="rest"/>
</endpoints>
</server>
</infinispan>This creates two socket bindings, one named public bound to the eth0 interface and one named admin bound to the loopback interface. The server will therefore listen for Hot Rod traffic only on the public network and for HTTP/REST traffic on the admin network.
For more details on how to configure Infinispan Server, refer to our documentation.
In the next blog post we will have an in-depth look at security.
Tags: server
Monday, 11 November 2019
Infinispan's new server
One of the biggest changes in Infinispan 10 is the new server, which replaces the WildFly-based server we had been using up until 9.x.
This is the first of a series of blog posts which will describe the new server, how to use it, how to configure it and how to deploy it in your environment. More specifically, this post will focus mostly on the reasons behind the change, while the next ones will be of a more practical nature.
A history of servers
Infinispan has had a server implementing the Hot Rod protocol since 4.1. Originally it was just a main class which bootstrapped the server protocol. It was configured via the same configuration file used by the embedded library, it had no security and only handled Hot Rod.
Over time both a RESTful HTTP and a Memcached protocol were added and could be bootstrapped in the same way.
While the server bootstrap code was trivial, it was not going to scale to support all the things we needed (security, management, provisioning, etc). We therefore decided to build our next server on top of the very robust foundation provided by WildFly (aka, the application server previously known as JBoss AS 7), which made its first appearance in 5.3.
Integration with WildFly’s management model was not trivial but it gave us all of the things we were looking for and more, such as deployments, data sources, CLI, console, etc. It also came with a way to provision multiple nodes and manage them from a central controller, i.e. domain mode. All of these facilities however came at the cost of a lot of extra integration code to maintain as well as a larger footprint, both in terms of memory and storage use, caused by a number of subsystems which we had to carry along, even though we didn’t use them directly.
A different server
Fast-forward several versions, and the computing landscape has changed considerably: services are containerized, they are provisioned and managed via advanced orchestration tools like Kubernetes or via configuration management tools like Ansible and the model we were using was overlapping (if not altogether clashing) with the container model, where global configuration is immutable and managed externally.
With the above in mind, we have therefore decided to reboot our server implementation. During planning and development it has been known affectionately as ServerNG, but nowadays it is just the Infinispan Server. The WildFly-based server is now the legacy server.
Configuration
The new server separates global configuration (clustering, endpoints, security) from the configuration of dynamic resources like caches, counters, etc. This means that global configuration can be made immutable while the mutable configuration is stored separately in the global persistence location. In a containerized environment you will place the persistence location onto a volume that will survive restarts.
A quick two-node cluster with Docker
Starting a two-node cluster using the latest version of the server image is easy:
$ docker run --name ispn1 --hostname ispn1 -e USER=admin -e PASS=admin -p 11222:11222 infinispan/server $ docker run --name ispn2 --hostname ispn2 -e USER=admin -e PASS=admin -p 11322:11222 infinispan/server
The two nodes will discover each other, as can be seen from the logs:
15:58:21,201 INFO [org.infinispan.CLUSTER] (jgroups-5,ispn-1-42736) ISPN000094: Received new cluster view for channel infinispan: [ispn-1-42736|1] (2) [ispn-1-42736, ispn-2-51789] 15:58:21,206 INFO [org.infinispan.CLUSTER] (jgroups-5,ispn-1-42736) ISPN100000: Node ispn-2-51789 joined the cluster
Next we will connect to the cluster using the CLI:
$ docker run -it --rm infinispan/server /opt/infinispan/bin/cli.sh [disconnected]> connect http://172.17.0.2:11222 Username: admin Password: ***** [ispn-1-42736@infinispan//containers/DefaultCacheManager]>
Next we will create a distributed cache and select it for future operations:
[ispn-1-42736@infinispan//containers/DefaultCacheManager]> create cache --template=org.infinispan.DIST_SYNC distcache [ispn-1-42736@infinispan//containers/DefaultCacheManager]> cache distcache [ispn-1-42736@infinispan//containers/DefaultCacheManager/caches/distcache]>
Let’s insert some data now:
[ispn-1-42736@infinispan//containers/DefaultCacheManager/caches/distcache]> put k1 v1 [ispn-1-42736@infinispan//containers/DefaultCacheManager/caches/distcache]> put k2 v2 [ispn-1-42736@infinispan//containers/DefaultCacheManager/caches/distcache]> ls k2 k1 [ispn-1-42736@infinispan//containers/DefaultCacheManager/caches/distcache]> get k1 v1
Now let’s use the RESTful API to fetch one of the entries:
$ curl --digest -u admin:admin http://localhost:11222/rest/v2/caches/distcache/k2 v2
Since we didn’t map persistent volumes to our containers, both the cache and its contents will be lost when we terminate the containers.
In the next blog post we will look at configuration and persistence in more depth.
Tags: server
Tuesday, 24 July 2018
Infinispan Spark connector 0.8 released
The Infinispan Spark connector version 0.8 has been released and is available in Maven central and SparkPackages.
This is a maintenance only release to bring compatibility with Spark 2.3 and Infinispan 9.3.
For more information about the connector, please consult the documentation and also try the docker based sample.
For feedback and general help, please use the Infinispan chat.
Tags: release spark server
Wednesday, 07 March 2018
REST with HTTP/2
HTTP has become one of the most successful and heavily used network protocols around the world. Version 1.0 was created in 1996 and received a minor update 3 years later. But it took more than a decade to create HTTP/2 (which was approved in 2015). Why did it take so long? Well, I wouldn’t tell you all the truth if I didn’t mention an experimental protocol, called SPDY. SPDY was primarily focused on improving performance. The initial results were very promising and inside Google’s lab, the developers measured 55% speed improvement. This work and experience was converted into HTTP/2 proposal back in 2012. A few years later, we can all use HTTP/2 (sometimes called h2) along with its older brother - HTTP/1.1.
Main differences between HTTP/1.1 and HTTP/2

HTTP/1.1 is a text-based protocol. Sometimes this is very convenient, since you can use low level tools, such as Telnet, for hacking. But it doesn’t work very well for transporting large, binary payloads. HTTP/2 solves this problem by using a completely redesigned architecture. Each HTTP message (a request or a response) consists of one or more frames. A frame is the smallest portion of data travelling through a TCP connection. A set of messages is aggregated into a, so called stream.

HTTP/2 allows to lower the number of physical connections between the server and the client by multiplexing logical connections into one TCP connection. Streams allow the server to recognize, which frame belongs to which conversation.
How to connect using HTTP/2?
There are two ways for starting an HTTP/2 conversation.
The first one, and the most commonly used one, is TLS/ALPN. During TLS handshake the server and the client negotiate protocol for further communication. Unfortunately JDK below 9 doesn’t support it by default (there are a couple of workarounds but please refer to your favorite HTTP client’s manual to find some suggestions).
The second one, much less popular, is so called plain text upgrade. During HTTP/1.1 conversation, the client issues an HTTP/1.1 Upgrade header and proposes new conversation protocol. If the server agrees, they start using it. If not, they stick with HTTP/1.1.
The good news is that Infinispan supports both those upgrade paths. Thanks to the ALPN Hack Engine (the credit goes to Stuart Douglas from the Wildfly Team), we support TLS/ALPN without any bootstrap classpath modification.
Configuring Infinispan server for HTTP/2
Infinispan’s REST server already supports plain text upgrades out of the box. TLS/ALPN however, requires additional configuration since the server needs to use a Keystore. In order to make it even more convenient, we support generating keystores automatically when needed. Here’s an example showing how to configure a security realm:
The next step is to bind the security realm to a REST endpoint:
You may also use one of our configuration examples. The easiest way to get it working is to use our Docker image:
Let’s explain a couple of things from the command above:
-
-e "APP_USER=test" - This is a user name we will be used for REST authentication.
-
-e "APP_PASS=test" - Corresponding password.
-
../../docs/examples/configs/standalone-rest-ssl.xml - Here is a ready-to-go configuration with REST and TLS/ALPN support
Unfortunately, HTTP/2 functionality has been broken in 9.2.0.Final. But we promise to fix it as soon as we can :) Please use 9.1.5.Final in the meantime.
Testing using CURL
Curl is one of my favorite tools. It’s very simple, powerful, and… it supports HTTP/2. Assuming that you already started Infinispan server using docker run command, you can put something into the cache:
Once, it’s there, let’s try to get it back:
Let’s analyze CURL switches one by one:
-
-k - Ignores certificate validation. All automatically generated certificates and self-signed and not trusted by default.
-
-v - Debug logging.
-
-u test:test - Username and password for authentication.
-
-d test - This is the payload when invoking HTTP POST.
-
-H “Accept: text/plain” - This tells the server what type of data we’d like to get in return.
Conclusions and links
I hope you enjoyed this small tutorial about HTTP/2. I highly encourage you to have a look at the links below to learn some more things about this topic. You may also measure the performance of your app when using HTTP/1.1 and HTTP/2. You will be surprised!
-
High Performance Browser Networking - One of the best books about HTTP and network performance. Most of the graphics in this article has been copied from that book. I highly recommend it!
Tags: docker server http/2 rest
Sunday, 10 September 2017
Multi-tenancy - Infinispan as a Service (also on OpenShift)
In recent years Software as a Service concept has gained a lot of traction. I’m pretty sure you’ve used it many times before. Let’s take a look at a practical example and explain what’s going on behind the scenes.
Practical example - photo album application
Imagine a very simple photo album application hosted within the cloud. Upon the first usage you are asked to create an account. Once you sign up, a new tenant is created for you in the application with all necessary details and some dedicated storage just for you. Starting from this point you can start using the album - download and upload photos.
The software provider that created the photo album application can also celebrate. They have a new client! But with a new client the system needs to increase its capacity to ensure it can store all those lovely photos. There are also other concerns - how to prevent leaking photos and other data from one account into another? And finally, since all the content will be transferred through the Internet, how to secure transmission?
As you can see, multi-tenancy is not that easy as it would seem. The good news is that if it’s properly configured and secured, it might be beneficial both for the client and for the software provider.
Multi-tenancy in Infinispan
Let’s think again about our photo album application for a moment. Whenever a new client signs up we need to create a new account for him and dedicate some storage. Translating that into Infinispan concepts this would mean creating a new CacheContainer. Within a CacheContainer we can create multiple Caches for user details, metadata and photos. You might be wondering why creating a new Cache is not sufficient? It turns out that when a Hot Rod client connects to a cluster, it connects to a CacheContainer exposed via a Hot Rod Endpoint. Such a client has access to all Caches. Considering our example, your friends could possibly see your photos. That’s definitely not good! So we need to create a CacheContainer per tenant. Before we introduced Multi-tenancy, you could expose each CacheContainer using a separate port (using separate Hot Rod Endpoint for each of them). In many scenarios this is impractical because of proliferation of ports. For this reason we introduced the Router concept. It allows multiple clients to access their own CacheContainers through a single endpoint and also prevents them from accessing data which doesn’t belong to them. The final piece of the puzzle is transmitting sensitive data through an unsecured channel such as the Internet. The use of TLS encryption solves this problem. The final outcome should look like the following:
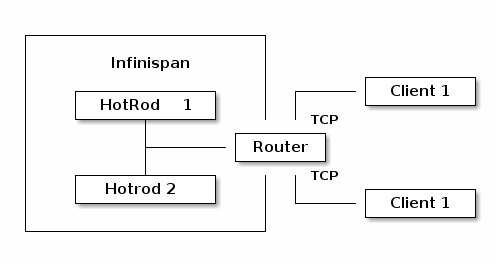
The Router component on the diagram above is responsible for recognizing data from each client and redirecting it to the appropriate Hot Rod endpoint. As the name implies, the router inspects incoming traffic and reroutes it to the appropriate underlying CacheContainer. To do this it can use two different strategies depending on the protocol: TLS/SNI for the Hot Rod protocol, matching each server certificate to a specific cache container and path prefixes for REST. The SNI strategy detects the SNI Host Name (which is used as tenant) and also requires TLS certificates to match. By creating proper trust stores we can match which tenant can access which CacheContainers. URL path prefix is very easy to understand, but it is also less secure unless you enable authentication. For this reason it should not be used in production unless you know what you are doing (the SNI strategy for the REST endpoint will be implemented in the near future). Each client has its own unique REST path prefix that needs to be used for accessing the data (e.g. http://127.0.0.1:8080/rest/client1/fotos/2).
Confused? Let’s clarify this with an example.
Foto application sample configuration
The first step is to generate proper key/trust stores for the server and client:
The next step is to configure the server. The snippet below shows only the most important parts:
Let’s analyze the most critical lines:
-
7, 15 - We need to add generated key stores to the server identities
-
25, 30 - It is highly recommended to use separate CacheContainers
-
38, 39 - A Hot Rod connector (but without socket binding) is required to provide proper mapping to CacheContainer. You can also use many useful settings on this level (like ignored caches or authentication).
-
42 - Router definition which binds into default Hot Rod and REST ports.
-
44 - 46 - The most important bit which states that only a client using SSLRealm1 (which uses trust store corresponding to client_1_server_keystore.jks) and TLS/SNI Host name client-1 can access Hot Rod endpoint named multi-tenant-hotrod-1 (which points to CacheContainer multi-tenancy-1).
Improving the application by using OpenShift
Hint: You might be interested in looking at our previous blog posts about hosting Infinispan on OpenShift. You may find them at the bottom of the page.
So far we’ve learned how to create and configure a new CacheContainer per tenant. But we also need to remember that system capacity needs to be increased with each new tenant. OpenShift is a perfect tool for scaling the system up and down. The configuration we created in the previous step almost matches our needs but needs some tuning.
As we mentioned earlier, we need to encrypt transport between the client and the server. The main disadvantage is that OpenShift Router will not be able to inspect it and take routing decisions. A passthrough Route fits perfectly in this scenario but requires creating TLS/SNI Host Names as Fully Qualified Application Names. So if you start OpenShift locally (using oc cluster up) the tenant names will look like the following: client-1-fotoalbum.192.168.0.17.nip.io.
We also need to think how to store generated key stores. The easiest way is to use Secrets:
Finally, a full DeploymentConfiguration:
If you’re interested in playing with the demo by yourself, you might find a working example here. It mainly targets OpenShift but the concept and configuration are also applicable for local deployment.
Tags: security hotrod server multi-tenancy rest
Monday, 03 April 2017
Infinispan Spark connector 0.5 released!
The Infinispan Spark connector offers seamless integration between Apache Spark and Infinispan Servers. Apart from supporting Infinispan 9.0.0.Final and Spark 2.1.0, this release brings many usability improvements, and support for another major Spark API.
Configuration changes
The connector no longer uses a java.util.Properties object to hold configuration, that’s now duty of org.infinispan.spark.config.ConnectorConfiguration, type safe and both Java and Scala friendly:
Filtering by query String
The previous version introduced the possibility of filtering an InfinispanRDD by providing a Query instance, that required going through the QueryDSL which in turn required a properly configured remote cache.
It’s now possible to simply use an Ickle query string:
Improved support for Protocol Buffers
Support for reading from a Cache with protobuf encoding was present in the previous connector version, but now it’s possible to also write using protobuf encoding and also have protobuf schema registration automatically handled.
To see this in practice, consider an arbitrary non-Infinispan based RDD<Integer, Hotel> where Hotel is given by:
In order to write this RDD to Infinispan it’s just a matter of doing:
Internally the connector will trigger the auto-generation of the .proto file and message marshallers related to the configured entity(ies) and will handle registration of schemas in the server prior to writing.
Splitter is now pluggable
The Splitter is the interface responsible to create one or more partitions from a Infinispan cache, being each partition related to one or more segments. The Infinispan Spark connector now can be created using a custom implementation of Splitter allowing for different data partitioning strategies during the job processing.
Goodbye Scala 2.10
Scala 2.10 support was removed, Scala 2.11 is currently the only supported version. Scala 2.12 support will follow https://issues.apache.org/jira/browse/SPARK-14220
Streams with initial state
It is possible to configure the InfinispanInputDStream with an extra boolean parameter to receive the current cache state as events.
Dataset support
The Infinispan Spark connector now ships with support for Spark’s Dataset API, with support for pushing down predicates, similar to rdd.filterByQuery. The entry point of this API is the Spark session:
To create an Infinispan based Dataframe, the "infinispan" data source need to be used, along with the usual connector configuration:
From here it’s possible to use the untyped API, for example:
or execute SQL queries by setting a view:
In both cases above, the predicates and the required columns will be converted to an Infinispan Ickle filter, thus filtering data at the source rather than at Spark processing phase.
For the full list of changes see the release notes. For more information about the connector, the official documentation is the place to go. Also check the twitter data processing sample and to report bugs or request new features use the project JIRA.
Tags: spark server