Tuesday, 05 March 2019
Enhanced JGroups configuration
Infinispan uses JGroups as its underlying clustering layer. In order to configure the finer details of clustering (discovery, flow control, cross-site, etc) you have to provide a separate XML file with the desired configuration and reference it from your Infinispan XML file as follows:
For simple configurations this is usually fine, but configuring complex setups, such as cross-site replication, means juggling multiple files (one for the local stack, one for the cross-site stack and one for the relay configuration).
Starting with Infinispan 10 Alpha2 we have introduced a number of changes to make your life with JGroups configurations a lot easier.
Default stacks
Infinispan now comes with two pre-declared stacks: tcp and udp. Using them is as simple as just referencing their names in the <transport> element.
Inline stacks
Inlining a stack means you can put the JGroups configuration inside the Infinispan one as follows:
You can use the full JGroups schema, and by using XML namespaces you get full validation.
Stack inheritance
Most of the time you want to reuse one of the pre-declared stacks but just override some of the parameters (e.g. discovery) to suit your environment. The following example creates a new tcpgossip stack which is based on the default tcp stack but replaces the discovery protocol with TCPGOSSIP:
In the above example you can see that we have enhanced the JGroups protocol declarations with two new attributes: ispn:stack.combine and ispn:stack.position which affect how and where protocol changes are applied on the parent configuration to obtain a new configuration. stack.combine can be one of COMBINE (the default, possibly overriding any specified attributes), REPLACE (which completely replaces the protocol and resets all attributes), REMOVE (removes the protocol) and INSERT_AFTER (which places this protocol in the stack immediately after the protocol specified by stack.position).
Multiple stacks and Cross-site
The inline configuration really shows its usefulness in cross-site configurations. In fact, the JGroups stack declaration has been extended with a special element which replaces the need for a separate relay XML file and can reference other stacks just by name. The following configuration uses the default udp stack for the local cluster transport and uses the default tcp stack for connecting to a remote site:
Having the entire configuration in a single place greatly simplifies management. Of course you can combine all of the above features to obtain the configuration you need for your environment. You can find more details and examples in the documentation. Enjoy ! Tristan
Tags: configuration jgroups
Wednesday, 27 September 2017
JGroups workshops in Rome and Berlin in November
I’m happy to announce that I’ve revamped the JGroups workshop and I’ll be teaching 2 workshops in November: Rome Nov 7-10 and Berlin Nov 21-24.
The new workshop is 4 days (TUE-FRI). I’ve updated the workshop to use the latest version of JGroups (4.0.x), removed a few sections and added sections on troubleshooting/diagnosis and handling of network partitions (split brain).
Should be a fun and hands-on workshop!
To register and for the table of contents, navigate to http://www.jgroups.org/workshops.html
To get the early-bird discount, use code EARLYBIRD.
Cheers,
Bela
Tags: workshop jgroups
Tuesday, 23 May 2017
KUBE_PING 0.9.3 released
I’m happy to announce that JGroups KUBE_PING 0.9.3 was released. The major changes include:
-
Fixed releasing connections for embedded HTTP Server
-
Fixed JGroups 3/4 compatibility issues
-
Fixed test suite
-
Fixed
Message.setSrccompatibility issues -
Updated documentation
The bits might be downloaded from JBoss Repository as soon as the sync completes. Please download them from here in the meantime.
I would also like to recommend you recent blog post created by Bela Ban. KUBE_PING was completely revamped (no embedded HTTP Server, reduced dependencies) and we plan to use new, 1.0.0 version in Infinispan soon! If you’d like to try it out, grab it from here.
Tags: kubernetes jgroups
Wednesday, 15 March 2017
KUBE_PING 0.9.2 released!
I’m happy to announce a new release of KUBE_PING JGroups protocol.
Since this is a minor maintenance release, there are no ground breaking changes but we fixed a couple of issues that prevented our users from using JGroups 3.6.x and KUBE_PING 0.9.1.
Have a look at the release page to learn more details.
The artifacts should be available in Maven Central as soon as the sync completes. In the meantime grab them from JBoss Repository.
Tags: kubernetes jgroups
Wednesday, 20 July 2016
Improved Infinispan Docker image available

The Infinispan Docker image has been improved, making it easier to run Infinispan Servers in clustered, domain and standalone modes, with different protocol stacks.
In this blog post we’ll show a few usage scenarios and how to combine it with the jgroups-gossip image to create Infinispan Server clusters in docker based environments.
==== Getting started
By default the container runs in clustered mode, and to start a node simply execute:
Bringing a second container will cause it to form a cluster.The membership can be verified by running a command directly in the newly launched container:
Example output:
==== Using a different JGroups stack
The command above creates a cluster with the default JGroups stack (UDP), but it’s possible to pick another one provided it’s supported by the server. For example, to use TCP:
==== Running on cloud environments
We recently dockerized the JGroups Gossip Router to be used as an alternative discovery mechanism in environments where multicast is not enabled, such as cloud environments.
Employing a gossip router will enable discovery via TCP, where the router acts as a registry: each member will register itself in this registry upon start and also discover other members.
The gossip router container can be launched by:
Take note of the address where the router will bind to, it’s needed by the Infinispan nodes. The address can be easily obtained by:
Finally we can now launch our cluster specifying the tcp-gossip stack with the location of the gossip router:
==== Launching Standalone mode
Passing an extra parameter allows to run a server in standalone (non-clustered) mode:
==== Server Management Console in Domain mode
Domain mode is a special case of clustered mode (and currently a requirement to use the Server Management Console), that involves launching a domain controller process plus one or more host controller processes. The domain controller does not hold data, it is used as a centralized management process that can replicate configuration and provision servers on the host controllers.
Running a domain controller is easily achievable with a parameter:
Once the domain controller is running, it’s possible to start one or more host controllers. In the default configuration, each host controller has two Infinispan server instances:
The command line interface can be used to verify the hosts managed in the domain:
It should output all the host names that are part of the domain, including the master (domain controller):
To get access to the Management console, use credentials admin/admin and go to port 9990 of the domain controller, for example: http://172.17.0.2:9990/
==== Versions
The image is built on Dockerhub shortly after each Infinispan release (stable and unstable), and the improvements presented in this post are available for Infinispan 9.0.0.Alpha3 and Infinispan 8.2.3.Final. As a reminder, make sure to pick the right version when launching containers:
Getting involved
The image was created to be flexible and easy to use, but if something is not working for you or if you have any suggestions to improve it, please report it at https://github.com/jboss-dockerfiles/infinispan/issues/
Enjoy!
Tags: docker console domain mode server jgroups
Monday, 02 November 2015
JBoss Clustering Team @ JUG Berlin Brandenburg
The entire JBoss Clustering Team will be at the Berlin-Brandenburg JUG on Thursday, 19th November talking about JGroups, Infinispan and WildFly clustering. If you are around, please come over to meet the team and share your thoughts and ideas.
The meetup is advertised here
Tags: JUGs event jgroups wildfly
Friday, 13 March 2015
Infinispan on Openshift v3
Openshift v3 is the open source next generation of Paas, where applications run on Docker containers and are orchestrated/controlled/scheduled by Kubernetes.
In this post I’ll show how to create an Infinispan cluster on Openshift v3 and resize it with a snap of a finger.
Openshift v3 has not been released yet, so I’m going to use the code from origin. There are many ways to install Openshift v3, but for simplicity, I’ll run a full multinode cluster locally on top of VirtualBoxes using the provided Vagrant scripts.
Let’s start by checking out and building the sources:
To boot Openshift, it’s a simple matter of starting up the desired number of nodes:
Grab a beer while the cluster is being provisioned, after a while you should be able to see 3 instances running:
Creating the Infinispan template
The following template defines a 2 node Infinispan cluster communicating via TCP, and discovery done using the JGroups gossip router:
There are few different components declared in this template:
-
A service with id jgroups-gossip-service that will expose a JGroups gossip router service on port 11000, around the JGroups Gossip container
-
A ReplicationController with id jgroups-gossip-controller. Replication Controllers are used to ensure that, at any moment, there will be a certain number of replicas of a pod (a group of related docker containers) running. If for some reason a node crashes, the ReplicationController will instantiate a new pod elsewhere, keeping the service endpoint address unchanged.
-
Another ReplicationController with id infinispan-controller. This controller will start 2 replicas of the infinispan-pod. As it happens with the jgroups-pod, the infinispan-pod has only one container defined: the infinispan-server container (based on jboss/infinispan-server) , that is started with the 'clustered.xml' profile and configured with the 'jgroups-gossip-service' address. By defining the gossip router as a service, Openshift guarantees that environment variables such as[.pl-s1]# JGROUPS_GOSSIP_SERVICE_SERVICE_HOST are# available to other pods (consumers).
Applying the template
To apply the template via cmd line:
Grab another beer, it can take a while since in this case the docker images need to be fetched on each of the minions from the public registry. In the meantime, to inspect the pods, along with their containers and statuses:
Resizing the cluster
Changing the number of pods (and thus the number of nodes in the Infinispan cluster) is a simple matter of manipulating the number of replicas in the Replication Controller. To increase the number of nodes to 4:
This should take only a few seconds, since the docker images are already present in all the minions.
And this concludes the post, be sure to check other cool features of Openshift in the project documentation and try out other samples.
Tags: docker openshift kubernetes paas server jgroups vagrant
Friday, 22 June 2012
Infinispan 5.2 alpha out now with Command Line Inteface!
Infinispan 5.2.0.ALPHA1 has just been released and it comes with a load of new goodies, here’s a summary:
-
Command Line Interface! See Tristan’s blog post for more information.
-
Infinispan based Lucene directory has been upgraded to Apache Lucene 3.6.
-
Make @ProvidedId annotation on @Indexed objects optional.
-
Upgrade to JGroups 3.1.x.
-
Upgrade to Berkeley DB 5.x
-
HBase cache store plugin
Full details of all the rest enhancements can be found here. If you have feedback, please visit our forums. Finally, as always, you can download the release from here.
Cheers,
Galder
Tags: release hbase alpha lucene jgroups berkeleydb cli
Thursday, 31 May 2012
Infinispan 5.1.5 goes FINAL!
Infinispan 'Brahma' 5.1.5.FINAL has now been released fixing a whole bunch of issues around cache store preloading of distributed caches, Memcached server, tree module and Hot Rod client performance. We’ve also updated several libraries such as Netty (to 3.4.6) and JGroups (to 3.0.10).
Full details of what has been fixed can be found here, and if you have feedback, please visit our forums. Finally, as always, you can download the release from here.
Cheers, Galder
Tags: release hotrod memcached jgroups cache store netty
Tuesday, 25 May 2010
Infinispan EC2 Demo
Infinispan’s distributed mode is well suited to handling large datasets and scaling the clustered cache by adding nodes as required. These days when inexpensive scaling is thought of, cloud computing immediately comes to mind.
One of the largest providers of cloud computing is Amazon with its Amazon Web Services (AWS) offering. AWS provides computing capacity on demand with its EC2 services and storage on demand with its S3 and EBS offerings. EC2 provides just an operating system to run on and it is a relatively straightforward process to get an Infinispan cluster running on EC2. However there is one gotcha, EC2 does not support UDP multicasting at this time and this is the default node discovery approach used by Infinispan to detect nodes running in a cluster.
Some background on network communications
Infinispan uses the JGroups library to handle all network communications. JGroups enables cluster node detection, a process called discovery, and reliable data transfer between nodes. JGroups also handles the process of nodes entering and exiting the cluster and master node determination for the cluster.
Configuring JGroups in Infinispan The JGroups configuration details are passed to Infinispan in the infinispan configuration file
<transport clusterName="infinispan-cluster" distributedSyncTimeout="50000"
transportClass="org.infinispan.remoting.transport.jgroups.JGroupsTransport">
<properties>
<property name="configurationFile" value="jgroups-s3_ping-aws.xml" />
</properties>
</transport>Node Discovery
JGroups has three discovery options which can be used for node discovery on EC2.
The first is to statically configure the address of each node in the cluster in each of the nodes peers. This simplifies discovery but is not suitable when the IP addresses of each node is dynamic or nodes are added and removed on demand.
The second method is to use a Gossip Router. This is an external Java process which runs and waits for connections from potential cluster nodes. Each node in the cluster needs to be configured with the ip address and port that the Gossip Router is listening on. At node initialization, the node connects to the gossip router and retrieves the list of other nodes in the cluster.
Example JGroups gossip router configuration
<config>
<TCP bind_port="7800" />
<TCPGOSSIP timeout="3000" initial_hosts="192.168.1.20[12000]"
num_initial_members="3" />
<MERGE2 max_interval="30000" min_interval="10000" />
<FD_SOCK start_port="9777" />
...
</config>The infinispan-4.1.0-SNAPSHOT/etc/config-samples/ directory has sample configuration files for use with the Gossip Router. The approach works well but the dependency on an external process can be limiting.
The third method is to use the new S3_PING protocol that has been added to JGroups. Using this the user configures a S3 bucket (location) where each node in the cluster will store its connection details and upon startup each node will see the other nodes in the cluster. This avoids having to have a separate process for node discovery and gets around the static configuration of nodes.
Example JGroups configuration using the S3_PING protocol:
<config>
<TCP bind_port="7800" />
<S3_PING secret_access_key="secretaccess_key" access_key="access_key"
location=s3_bucket_location" />
<MERGE2 max_interval="30000" min_interval="10000" />
<FD_SOCK start_port="9777" />
...
</config>EC2 demo
The purpose of this demo is to show how an Infinispan cache running on EC2 can easily form a cluster and retrieve data seamlessly across the nodes in the cluster. The addition of any subsequent Infinispan nodes to the cluster automatically distribute the existing data and offer higher availability in the case of node failure.
To demonstrate Infinispan, data is required to be added to nodes in the cluster. We will use one of the many public datasets that Amazon host on AWS, the influenza virus dataset publicly made available by Amazon.
This dataset has a number components which make it suitable for the demo. First of all it is not a trivial dataset, there are over 200,000 records. Secondly there are internal relationships within the data which can be used to demonstrate retrieving data from different cache nodes. The data is made up for viruses, nucleotides and proteins, each influenza virus has a related nucleotide and each nucleotide has one or more proteins. Each are stored in their own cache instance.
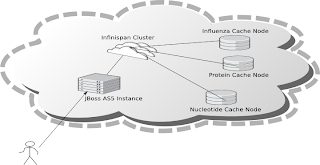
The caches are populated as follows :
-
InfluenzaCache - populated with data read from the
Influenza.datfile, approx 82,000 entries -
ProteinCache - populated with data read from the
Influenza_aa.datfile, approx 102,000 entries -
NucleotideCache - populated with data read from the
Influenza_na.datfile, approx 82,000 entries
The demo requires 4 small EC2 instances running Linux, one instance for each cache node and one for the Jboss application server which runs the UI. Each node has to have Sun JDK 1.6 installed in order to run the demos. In order to use the Web-based GUI, JBoss AS 5 should also be installed on one node.
In order for the nodes to communicate with each other the EC2 firewall needs to be modified. Each node should have the following ports open:
-
TCP 22 – For SSH access
-
TCP 7800 to TCP 7810 – used for JGroups cluster communications
-
TCP 8080 – Only required for the node running the AS5 instance in order to access the Web UI.
-
TCP 9777 - Required for FD_SOCK, the socket based failure detection module of the JGroups stack.
To run the demo, download the Infinispan "all" distribution, (infinispan-xxx-all.zip) to a directory on each node and unzip the archive.
Edit the etc/config-samples/ec2-demo/jgroups-s3_ping-aws.xml file to add the correct AWS S3 security credentials and bucket name.
Start the one of the cache instances on each node using one of the following scripts from the bin directory:
-
runEC2Demo-influenza.sh -
runEC2Demo-nucleotide.sh -
runEC2Demo-protein.sh
Each script will startup and display the following information :
[tmp\] ./runEC2Demo-nucleotide.shCacheBuilder called with /opt/infinispan-4.1.0-SNAPSHOT/etc/config-samples/ec2-demo/infinispan-ec2-config.xml ------------------------------------------------------------------- GMS: address=redlappie-37477, cluster=infinispan-cluster, physical address=192.168.122.1:7800 ------------------------------------------------------------------- Caches created.... Starting CacheManagerCache Address=redlappie-57930Cache Address=redlappie-37477Cache Address=redlappie-18122 Parsing files....Parsing [/opt/infinispan-4.1.0-SNAPSHOT/etc/Amazon-TestData/influenza_na.dat] About to load 81904 nucleotide elements into NucleiodCache Added 5000 Nucleotide records Added 10000 Nucleotide records Added 15000 Nucleotide records Added 20000 Nucleotide records Added 25000 Nucleotide records Added 30000 Nucleotide records Added 35000 Nucleotide records Added 40000 Nucleotide records Added 45000 Nucleotide records Added 50000 Nucleotide records Added 55000 Nucleotide records Added 60000 Nucleotide records Added 65000 Nucleotide records Added 70000 Nucleotide records Added 75000 Nucleotide records Added 80000 Nucleotide records Loaded 81904 nucleotide elements into NucleotidCache Parsing files....Done Protein/Influenza/Nucleotide Cache Size-->9572/10000/81904 Protein/Influenza/Nucleotide Cache Size-->9572/20000/81904 Protein/Influenza/Nucleotide Cache Size-->9572/81904/81904 Protein/Influenza/Nucleotide Cache Size-->9572/81904/81904
Items of interest in the output are the Cache Address lines which display the address of the nodes in the cluster. Also of note is the Protein/Influenza/Nucleotide line which displays the number of entries in each cache. As other caches are starting up these numbers will change as cache entries are dynamically moved around through out the Infinispan cluster.
To use the web based UI we first of all need to let the server know where the Infinispan configuration files are kept. To do this edit the jboss-5.1.0.GA/bin/run.conf file and add the line
JAVA_OPTS="$JAVA_OPTS -DCFGPath=/opt/infinispan-4.1.0-SNAPSHOT/etc/config-samples/ec2-demo/"at the bottom. Replace the path as appropriate.
Now start the Jboss application server using the default profile e.g. run.sh -c default -b xxx.xxx.xxx.xxx, where “xxx.xxx.xxx.xxx” is the public IP address of the node that the AS is running on.
Then drop the infinispan-ec2-demoui.war into the jboss-5.1.0.GA /server/default/deploy directory.
Finally point your web browser to http://public-ip-address:8080/infinispan-ec2-demoui and the following page will appear.

The search criteria is the values in the first column of the /etc/Amazon-TestData/influenza.dat file e.g. AB000604, AB000612, etc.

Note that this demo will be available in Infinispan 4.1.0.BETA2 onwards. If you are impatient, you can always build it yourself from Infinispan’s source code repository.
Enjoy, Noel
Tags: ec2 amazon jgroups s3 demo aws