Friday, 12 July 2019
Infinispan Operator 0.3.0 expands container and security configuration!
Infinispan Operator 0.3.0 is now available with expanded configuration and security options:
Container Configuration
With this release of the Infinispan Operator, you can configure explicit CPU and memory limits for individual containers. The defaults are 0.5 CPUs and 512Mi of memory.
The Operator also lets you pass extra JVM options, which is useful for tracking native memory consumption or extra GC logging parameters.
Security Configuration
Starting with 0.3.0, credentials are automatically generated for data connector and management users when you instantiate the Infinispan Operator.
The default usernames are developer and admin for the data connector user and management user, respectively.
Generated passwords are stored in Kubernetes Secret instances. You can extract the passwords as follows:
For convenience, the default usernames are also stored in the secret. Using the jq command line tool, you can inspect both the username and password values with a single command:
If you want to set custom credentials for the data connector and management users, create Kubernetes Secret instances as follows:
When using a Credentials type authentication, the referenced secrets must contain username and password fields.
Trying It Out!
The easiest way to get started with the Infinispan Operator is via the simple tutorial. The Operator is compatible with vanilla Kubernetes environments, such as Minikube, as well as Red Hat OpenShift.
Available via Operator Hub
Install the Infinispan Operator directly from the Operator Hub, which is available out of the box on all OpenShift 4 versions. If you’re using a vanilla Kubernertes environment, you might need to install the Operator Lifecycle Manager before you can install via the Operator Hub.
The Infinispan Operator is also included in the community for Kubernetes Operators is available from operatorhub.io.
What’s Next?
The Operator configuration does not yet provide all capabilities available for Infinispan servers. We’re working through a process of configuration specification that distills the server configuration into a simple, easy to use, set of configuration options. The current proposal is being discussed openly here.
Infinispan 10 brings a brand new server that’s no longer based on WildFly. The Operator 0.x series will remain focused on Infinispan 9.x server, with Operator 1.x series focusing on Infinispan 10 and onwards.
Cheers, Galder
Tags: release openshift kubernetes operator
Wednesday, 10 May 2017
Running an Infinispan cluster with Kubernetes on Google Container Engine (GKE)
Over the past few years we’ve been blogging a lot on how to use Infinispan in cloud environments based on Docker, Kubernetes or OpenShift.
Continuing with this series of blog posts, Bela Ban, chief-in-charge of JGroups, posted an unmissable blog post yesterday not only how to run Infinispan with Kubernetes on Google Container Engine (GKE), but also how to load test it with IspnPerfTest.
If any of these topics interests you, don’t miss out and head to Bela’s blog to read all about it!
Thanks Bela for the blog post!!!
Cheers, Galder
Tags: gke kubernetes google
Monday, 20 March 2017
Memory and CPU constraints inside a Docker Container
In one of the previous blog posts we wrote about different configuration options for our Docker image. Now we did another step adding auto-configuration steps for memory and CPU constraints.
Before we dig in…
Setting memory and CPU constraints to containers is very popular technique especially for public cloud offerings (such as OpenShift). Behind the scenes everything works based on adding additional Docker settings to the containers. There are two very popular switches: --memory (which is responsible for setting the amount of available memory) and --cpu-quota (which throttles CPU usage).
Now here comes the best part… JDK has no idea about those settings! We will probably need to wait until JDK9 for getting full CGroups support.
What can we do about it?
The answer is very simple, we need to tell JDK what is the available memory (at least by setting Xmx) and available number of CPUs (by setting XX:ParallelGCThreads, XX:ConcGCThreads and Djava.util.concurrent.ForkJoinPool.common.parallelism).
And we have some very good news! We already did it for you!
Let’s test it out!
At first you need to pull our latest Docker image:
Then run it with CPU and memory limits using the following command:
Note that JAVA_OPTS variable was overridden. Let’s have a look what had happened:
-
-Xms64m -Xmx350m - it is always a good idea to set Xmn inside a Docker container. Next we set Xmx to 70% of available memory.
-
-XX:ParallelGCThreads=6 -XX:ConcGCThreads=6 -Djava.util.concurrent.ForkJoinPool.common.parallelism=6 - The next thing is setting CPU throttling as I explained above.
There might be some cases where you wouldn’t like to set those properties automatically. In that case, just pass -n switch to the starter script:
More reading
If this topic sounds interesting to you, do not forget to have a look at those links:
-
A great series of articles about memory and CPU in the containers by Andrew Dinn
-
A practical implementation by Fabric8 Team
-
A great article about memory limits by Rafael Benevides
-
OpenShift guidelines for creating Docker images
Tags: docker openshift kubernetes
Wednesday, 15 March 2017
KUBE_PING 0.9.2 released!
I’m happy to announce a new release of KUBE_PING JGroups protocol.
Since this is a minor maintenance release, there are no ground breaking changes but we fixed a couple of issues that prevented our users from using JGroups 3.6.x and KUBE_PING 0.9.1.
Have a look at the release page to learn more details.
The artifacts should be available in Maven Central as soon as the sync completes. In the meantime grab them from JBoss Repository.
Tags: kubernetes jgroups
Wednesday, 01 March 2017
Checking Infinispan cluster health and Kubernetes/OpenShift
Modern applications and microservices often need to expose their health status. A common example is Spring Actuator but there are also many different ways of doing that.
Starting from Infinispan 9.0.0.Beta2 we introduced the HealthCheck API. It is accessible in both Embedded and Client/Server mode.
Cluster Health and Embedded Mode
The HealthCheck API might be obtained directly from EmbeddedCacheManager and it looks like this:
The nice thing about the API is that it is exposed in JMX by default:
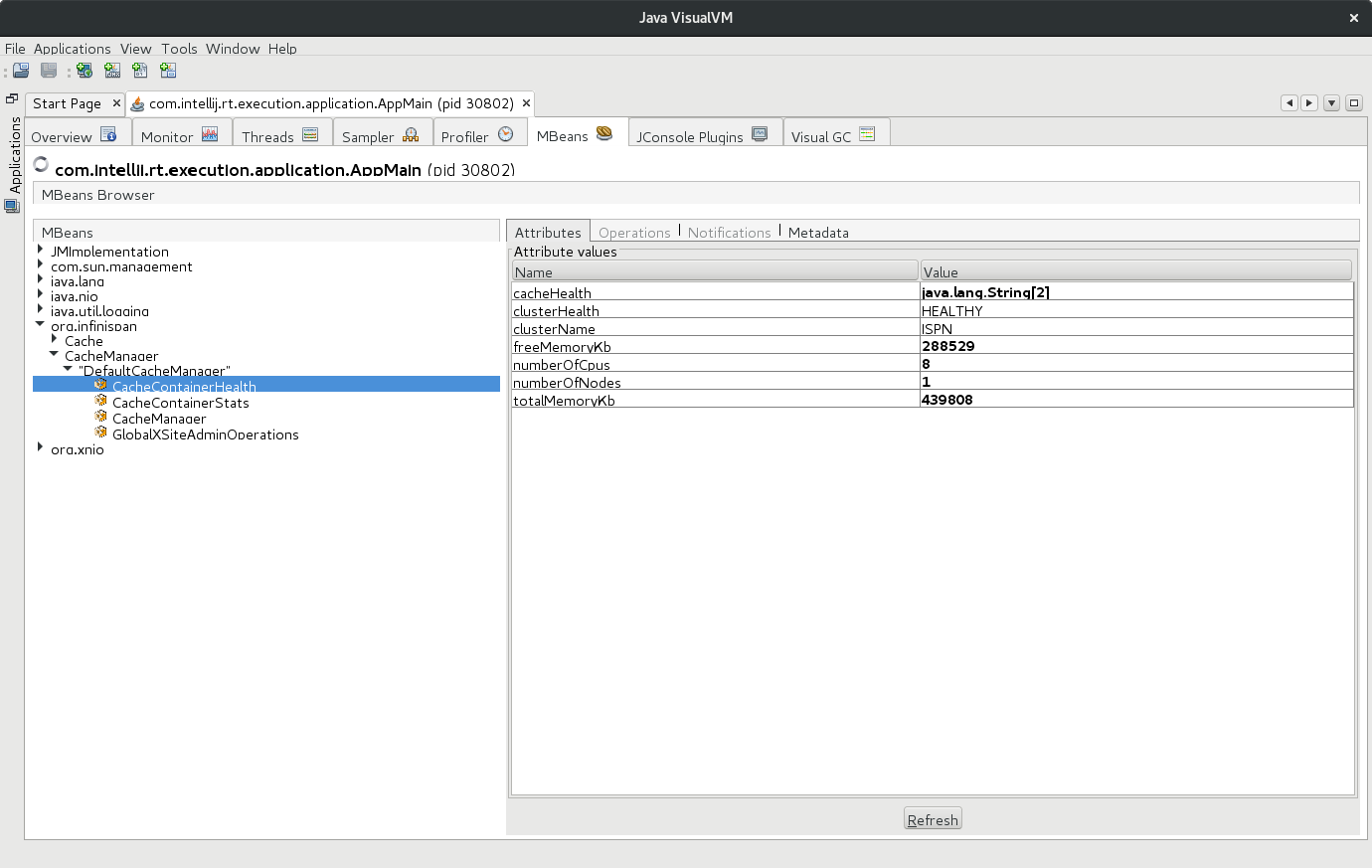
More information about using HealthCheck API in Embedded Mode might be found here:
Cluster Health and Server Mode
Since Infinispan is based on Wildfly, we decided to use CLI as well as built-in Management REST interface.
Here’s an example of checking the status of a running server:
Querying the HealthCheck API using the Management REST is also very simple:
Note that for the REST endpoint, you have to use proper credentials.
More information about the HealthCheckA API in Server Mode might be found here:
Cluster Health and Kubernetes/OpenShift
Monitoring cluster health is crucial for Clouds Platforms such as Kubernetes and OpenShift. Those Clouds use a concept of immutable Pods. This means that every time you need change anything in your application (changing configuration for the instance), you need to replace the old instances with new ones. There are several ways of doing that but we highly recommend using Rolling Updates. We also recommend to tune the configuration and instruct Kubernetes/OpenShift to replace Pods one by one (I will show you an example in a moment).
Our goal is to configure Kubernetes/OpenShift in such a way, that each time a new Pod is joining or leaving the cluster a State Transfer is triggered. When data is being transferred between the nodes, the Readiness Probe needs to report failures and prevent Kubernetes/OpenShift from doing progress in Rolling Update procedure. Once the cluster is back in stable state, Kubernetes/OpenShift can replace another node. This process loops until all nodes are replaced.
Luckily, we introduced two scripts in our Docker image, which can be used out of the box for Liveness and Readiness Probes:
At this point we are ready to put all the things together and assemble DeploymentConfig:
Interesting parts of the configuration:
-
lines 13 and 14: We allocate additional capacity for the Rolling Update and allow one Pod to be down. This ensures Kubernetes/OpenShift replaces nodes one by one.
-
line 44: Sometimes shutting a Pod down takes a little while. It is always better to wait until it terminates gracefully than taking the risk of losing data.
-
lines 45 - 53: The Liveness Probe definition. Note that when a node is transferring the data it might highly occupied. It is wise to set higher value of 'failureThreshold'.
-
lines 54 - 62: The same rule as the above. The bigger the cluster is, the higher the value of 'successThreshold' as well as 'failureThreshold'.
Feel free to checkout other articles about deploying Infinispan on Kubernetes/OpenShift:
-
http://blog.infinispan.org/2016/08/running-infinispan-cluster-on-openshift.html
-
http://blog.infinispan.org/2016/08/running-infinispan-cluster-on-kubernetes.html
-
http://blog.infinispan.org/2016/09/configuration-management-on-openshift.html
-
http://blog.infinispan.org/2016/10/openshift-and-node-affinity.html
-
http://blog.infinispan.org/2016/07/bleeding-edge-on-docker.html
Tags: openshift kubernetes state transfer health
Thursday, 18 August 2016
Running Infinispan cluster on Kubernetes
In the previous post we looked how to run Infinispan on OpenShift. Today, our goal is exactly the same, but we’ll focus on Kubernetes.
Running Infinispan on Kubernetes requires using proper discovery protocol. This blog post uses Kubernetes Ping but it’s also possible to use Gossip Router.
Our goal
We’d like to build Infinispan cluster based on Kubernetes hosted locally (using Minikube). We will expose a service and route it to our local machine. Finally, we will use it to put data into the grid.
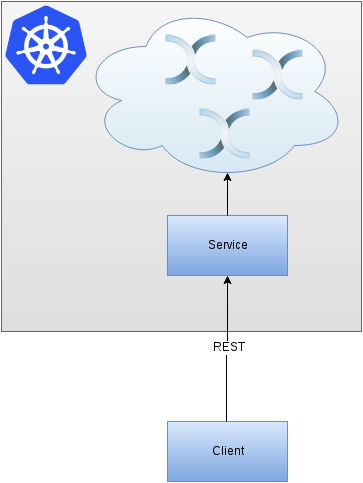
Spinning local Kubernetes cluster
There are many ways to spin up a local Kubernetes cluster. One of my favorites is Minikube. At first you will need the 'minikube' binary, which can be downloaded from Github releases page. I usually copy it into '/usr/bin' which makes it very convenient to use. The next step is to download 'kubectl' binary. I usually use Kubernetes Github releases page for this. The 'kubectl' binary is stored inside the release archive under 'kubernetes/platforms/<your_platform>/<your_architecture>/kubectl'. I’m using linux/amd64 since I’m running Fedora F23. I also copy the binary to '/usr/bin'.
We are ready to spin up Kubernetes:
Deploying Infinispan cluster
This time we’ll focus on automation, so there will be no 'kubectl edit' commands. Below is the yaml file for creating all necessary components in Kubernetes cluster:
-
(lines 23 - 24) - We added additional arguments to the bootstrap scipt
-
(lines 26 - 30) - We used Downward API for pass the current namespace to the Infinispan
-
(lines 34 - 45) - We defined all ports used by the Pod
-
(lines 49 - 66) - We created a service for port 8080 (the REST interface)
-
(line 64) - We used NodePort service type which we will expose via Minikube in the next paragraph
Save it somewhere on the disk and execute 'kubectl create' command:
Exposing the service port
One of the Minikube’s limitations is that it can’t use Ingress API and expose services to the outside world. Thankfully there’s other way - use Node Port service type. With this simple trick we will be able to access the service using '<minikube_ip>:<node_port_number>'. The port number was specified in the yaml file (we could leave it blank and let Kubernetes assign random one). The node port can easily be checked using the following command:
In order to obtain the Kubernetes node IP, use the following command:
Testing the setup
Testing is quite simple and the only thing to remember is to use the proper address - <minikube_ip>:<node_port>:
Conclusion
Kubernetes setup is almost identical to the OpenShift one but there are a couple of differences to keep in mind:
-
OpenShift’s DeploymentConfiguration is similar Kubernetes Deployment with ReplicaSets
-
OpenShift’s Services work the same way as in Kubernetes
-
OpenShift’s Routes are similar to Kubernetes' Ingresses
Happy scaling and don’t forget to check if Infinispan formed a cluster (hint - look into the previous post).
Tags: kubernetes
Tuesday, 09 August 2016
Running Infinispan cluster on OpenShift
Did you know that it’s extremely easy to run Infinispan in OpenShift? Infinispan 9.0.0.Alpha4 adds out of the box support for OpenShift (and Kubernetes) discovery!
Our goal
We’d like to build an Infinispan cluster on top of OpenShift and expose a Service for it (you may think about Services as Load Balancers). A Service can be exposed to the outside world using Routes. Finally, we will use REST interface to PUT and GET some data from the cluster.
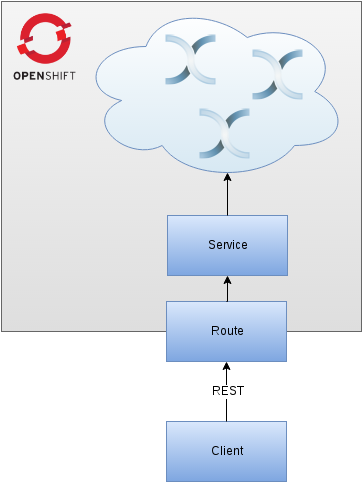
Accessing the OpenShift cloud
Of course before playing with Infinispan, you will need an OpenShift cluster. There are number of options you can investigate. I will use the simplest path - OpenShift local cluster.
The first step is to download OpenShift Client Tools for your platform. You can find them on OpenShift releases Github page. Once you download and extract the 'oc' binary, make it accessible in your $PATH. I usually copy such things into my '/usr/bin' directory (I’m using Fedora F23).
Once everything is set and done - spin up the cluster:
Note that you have been automatically logged in as 'developer' and your project has been automatically set to 'myproject'.
Spinning an Infinispan cluster
The first step is to create an Infinispan app:
Now you need to modify the Deployment Configuration (use 'oc edit dc/infinispan-server' for this) and tell Infinispan to boot up with Kubernetes' discovery protocol stack by using the proper namespace to look up other nodes (unfortunately this step can not be automated, otherwise a newly created Infinispan node might try to join an existing cluster and this is something you might not want). Here’s my modified Deployment Configuration:
-
(lines 58-60) - Modified Infinispan startup parameters by adding image startup arguments.
-
(lines 88-90) - JGroups Kubernetes Discovery protocol is instrumented by the Downward API to use current project’s namespace.
There is one final step - Kubernetes' PING protocol uses the API to look up other nodes in the Infinispan cluster. By default API access is disabled in OpenShift and needs to be enabled. This can be done by this simple command:
Now we can redeploy the application (to ensure that all changes were applied) and scale it out (to 3 nodes):
Now let’s check if everything looks good - you can do it either through the OpenShift web console or by using 'oc get pods' and 'oc logs' commands:
Accessing the cluster
In order to access the Infinispan cluster from the outside world we need a Route:
The newly created Route needs small changes - we need to change the target port to 8080 (this is the REST service). The 'oc edit route/infinispan-server' command is perfect for it. Below is my updated configuration:
-
(line 17) - Modified to 8080 TCP port
Testing the setup
You can easily see how to access the cluster by describing the Route:
Now let’s try to play with the data:
Cleaning up
Finally, when you are done with experimenting, you can remove everything using 'oc delete' command:
Conclusion
Running Infinispan cluster inside an OpenShift cloud is really simple. Just 3 steps to remember:
-
Create an Infinispan app ('oc new-app')
-
Tell it to use Kubernetes JGroups Stack and in which project look for other cluster members ('oc edit dc/infinispan-server')
-
Allow access to the OpenShift API ('oc policy add-role-to-user')
Happy scaling!
Tags: openshift kubernetes
Friday, 13 March 2015
Infinispan on Openshift v3
Openshift v3 is the open source next generation of Paas, where applications run on Docker containers and are orchestrated/controlled/scheduled by Kubernetes.
In this post I’ll show how to create an Infinispan cluster on Openshift v3 and resize it with a snap of a finger.
Openshift v3 has not been released yet, so I’m going to use the code from origin. There are many ways to install Openshift v3, but for simplicity, I’ll run a full multinode cluster locally on top of VirtualBoxes using the provided Vagrant scripts.
Let’s start by checking out and building the sources:
To boot Openshift, it’s a simple matter of starting up the desired number of nodes:
Grab a beer while the cluster is being provisioned, after a while you should be able to see 3 instances running:
Creating the Infinispan template
The following template defines a 2 node Infinispan cluster communicating via TCP, and discovery done using the JGroups gossip router:
There are few different components declared in this template:
-
A service with id jgroups-gossip-service that will expose a JGroups gossip router service on port 11000, around the JGroups Gossip container
-
A ReplicationController with id jgroups-gossip-controller. Replication Controllers are used to ensure that, at any moment, there will be a certain number of replicas of a pod (a group of related docker containers) running. If for some reason a node crashes, the ReplicationController will instantiate a new pod elsewhere, keeping the service endpoint address unchanged.
-
Another ReplicationController with id infinispan-controller. This controller will start 2 replicas of the infinispan-pod. As it happens with the jgroups-pod, the infinispan-pod has only one container defined: the infinispan-server container (based on jboss/infinispan-server) , that is started with the 'clustered.xml' profile and configured with the 'jgroups-gossip-service' address. By defining the gossip router as a service, Openshift guarantees that environment variables such as[.pl-s1]# JGROUPS_GOSSIP_SERVICE_SERVICE_HOST are# available to other pods (consumers).
Applying the template
To apply the template via cmd line:
Grab another beer, it can take a while since in this case the docker images need to be fetched on each of the minions from the public registry. In the meantime, to inspect the pods, along with their containers and statuses:
Resizing the cluster
Changing the number of pods (and thus the number of nodes in the Infinispan cluster) is a simple matter of manipulating the number of replicas in the Replication Controller. To increase the number of nodes to 4:
This should take only a few seconds, since the docker images are already present in all the minions.
And this concludes the post, be sure to check other cool features of Openshift in the project documentation and try out other samples.
Tags: docker openshift kubernetes paas server jgroups vagrant