Monday, 14 September 2015
Initial Support for Apache Avro and Gora
Avro and Gora are two Apache projects that belong to the Hadoop ecosystem. Avro is a data serialization framework that relies on JSON for defining data types and protocols, and serializes data in a compact binary format. Its primary use in Hadoop is to provide a serialization format for persistent data, and a wire format for communication between Hadoop nodes, and from client programs to the Hadoop services. Gora is an open-source software framework that provides an in-memory data model and persistence for big data. Gora supports persisting to column stores, key/value stores or databases, and analyzing the data with extensive Apache Hadoop MapReduce support.
As an effort to run Hadoop based applications atop Infinispan, the LEADS EU FP7 project has developed an Avro backend (infinispan-avro) and a Gora module (gora-infinispan). The former allows to store, retrieve and query Avro defined types via the HotRod protocol. The latter allows Gora-based applications to use Infinispan as a storage backend for their MapReduce jobs. In the current state of the implementation, the two modules make use of Infinispan 8.0.0.Final, Avro 1.7.6 and Gora 0.6
What’s in it for you Infinispan user
There are several use cases for which you can benefit from those modules.
-
With Infinispan’s Avro support, you can decide to persist your data in Infinispan using Avro’s portable format instead of Infinispan’s own format (or Java serialization’s format). This might help you standardize upon a common format for your data at rest.
-
If you use Apache Gora to store/query some of your data in, or even out, of the Hadoop ecosystem, you can use Infinispan as the backend and benefit Infinispan’s features that you come to know like data distribution, partition handling, cross-site clustering.
-
The last use case is to run legacy Hadoop applications, using Infinispan as the primary storage. For instance, it is possible to run the Apache Nutch web crawler atop Infinispan. A recent paper at IEEE Cloud 2015 gives a detailed description of such an approach in a geo-distributed environment (a preprint is available here).
Tags: marshalling hotrod map reduce
Thursday, 05 June 2014
Map/Reduce Performance improvements between Infinispan 6 and 7
Introduction
There have been a number of recent Infinispan 7.0 Map/Reduce performance related improvements that we were eager to test in our performance lab and subsequently share with you. The results are more than promising. In the word count use case, Map/Reduce task execution speed and throughput improvement is between fourfold and sixfold in certain situations that were tested.
We have achieved these improvements by focusing on:
-
Optimized mapper/reducer parallel execution on all nodes
-
Improving the handling and processing of larger data sets
-
Reducing the amount of memory needed for execution of MapReduceTask
Performance Test Results
The performance tests were run using the following parameters:
-
An Infinispan 7.0.0-SNAPSHOT build created after the last commits from the list were committed to the Infinispan GIT repo on May 9th vs Infinispan 6.0.1.Final
-
OpenJDK version 1.7.0_55 with 4GB of heap and the following JVM options:
-
Random data filled 30% of the Java heap, and 100 random words were used to create the 8 kilobyte cache values. The cache keys were generated using key affinity, so that the generated data would be distributed evenly in the cache. These values were chosen, so that a comparison to Infinispan 6 could be made. Infinispan 7 can handle a final result map with a much larger set of keys than is possible in Infinispan 6. The actual amount of heap size that is used for data will be larger due to backup copies, since the cluster is running in distributed mode.
-
The MapReduceTask executes a word count against the cache values using mapper, reducer, combiner, and collator implementations. The collator returns the 10 most frequently occurring words in the cache data. The task used a distributed reduce phase and a shared intermediate cache. The MapReduceTask is executed 10 times against the data in the cache and the values are reported as an average of these durations.
From 1 to 8 nodes using a fixed amount of data and 30% of the heap
This test executes two word count executions on each cluster with an increasing number of nodes. The first execution uses an increasing amount of data equal to 30% of the total Java heap across the cluster (i.e. With one node, the data consumes 30% of 4 GB. With two nodes, the data consumes 30% of 8 GB, etc.), and the second execution uses a fixed amount of data, (1352 MB which is approximately 30% of 4 GB). Throughput is calculated by dividing the total amount of data processed by the Map/Reduce task by the duration. The following charts show the throughput as nodes are added to the cluster for these two scenarios:
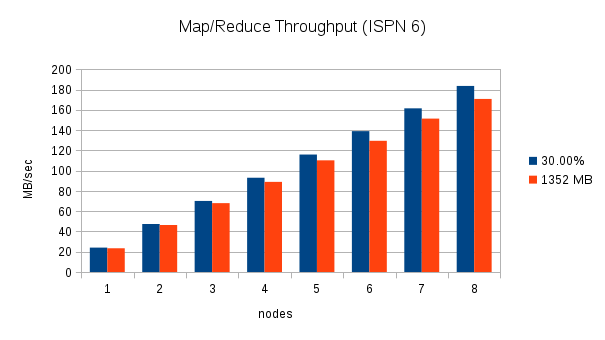

These charts clearly show the increase in throughput that were made in Infinispan 7. The throughput also seems to scale in an almost linear fashion for this word count scenario. With one node, Infinispan 7 processes the 30% of heap data in about 100 MB/sec, two nodes process almost 200 MB/sec, and 8 nodes process over 700 MB/sec.
From 1 to 8 nodes using different heap size percentages
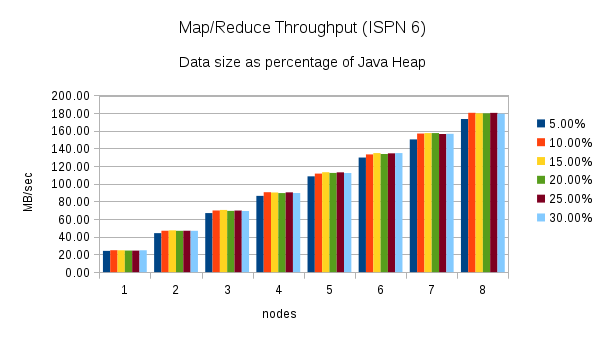
This test executes the word count task using different percentages of heap size as nodes are added to the cluster. (5%, 10%, 15%, 20%, 25%, and 30%) Here are the throughput results for this test:
 http://2.bp.blogspot.com/-fqmkYkxZtyI/U5AqS08Xk9I/AAAAAAAAACA/_wsTOmSbkdc/s1600/ISPN7_multi_ram_percent_throughput.png[
http://2.bp.blogspot.com/-fqmkYkxZtyI/U5AqS08Xk9I/AAAAAAAAACA/_wsTOmSbkdc/s1600/ISPN7_multi_ram_percent_throughput.png[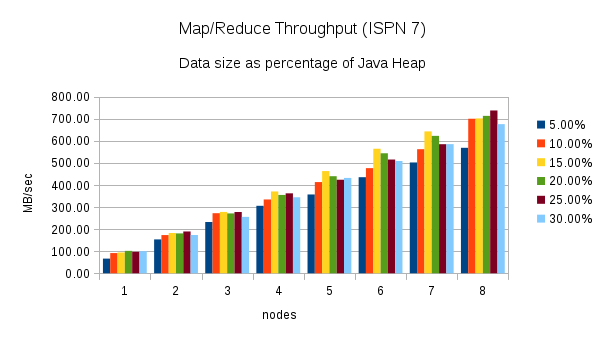 ]
]
Once again, these charts show an increase in throughput when performing the same word count task using Infinispan 7. The chart for Infinispan 7 shows more fluctuation in the throughput across the different percentages of heap size. The throughput plotted in the Infinispan 6 chart is more consistent.
From 1 to 8 nodes using different value sizes
This test executes the word count task using 30% of the heap size and different cache value sizes as nodes are added to the cluster. (1KB, 2KB, 4KB, 8KB, 16KB, 32KB, 64KB, 128KB, 256KB, 512KB, 1MB, and 2MB) Here are the throughput results for this test:
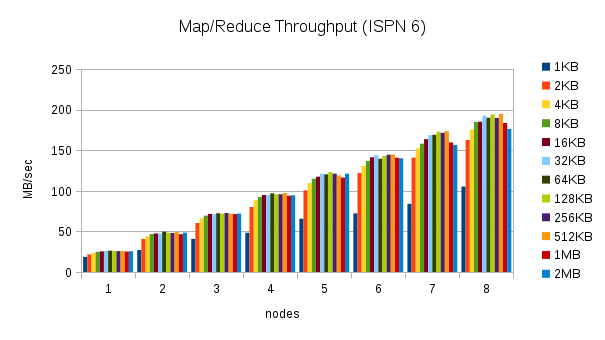
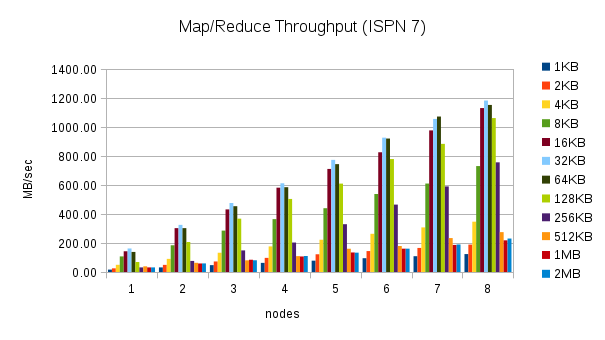
These results are more interesting. The throughput in Infinispan 7 is higher for certain cache size values, but closer to Infinispan 6 or even slower for other cache size values. The throughput peaks for 32KB cache values, but can be much lower for larger and smaller values. Smaller values require more overhead, but for larger values this behavior is not expected. This result needs to be investigated more closely.
Conclusion
The performance tests show that Infinispan 7 Map/Reduce improvements have increased the throughput and execution speed four to sixfold in some use cases. The changes have also allowed Infinispan 7 to process data sets that include larger intermediate results and produce larger final result maps. There are still areas of the Map/Reduce algorithm that need to be improved:
-
The Map/Reduce algorithm should be self-tuning. The maxCollectorSize parameter controls the number of values that the collector holds in memory, and it is not trivial to determine the optimal value for a given scenario. The value is based on the size of the values in the cache and the size of the intermediate results. A user is likely to know the size of the cache values, but currently Infinispan does not report statistics about the intermediate results to the user. The Map/Reduce algorithm should analyze the environment at runtime and adjust the size of the collector dynamically.
-
The fact that the throughput results vary with different value sizes needs to be investigated more closely. This could be due to the fact that the maxCollectorSize value used for these tests is not ideal for all value sizes, but there might be other causes for this behaviour.
Tags: radargun benchmarks performance map reduce
Friday, 11 April 2014
Infinispan 7.0.0.Alpha3 is out!
Hi, The Alpha3 release of Infinispan 7.0.0 is now available.
Highlights:
-
authorization at both CacheManager and Cache levels
-
some important enhancements for Map/Reduce’s usability, like the ability to use an intermediate cache during Map/Reduce execution and for storing the final results of the Map/Reduce tasks
-
a much welcomed revamp of the Infinispan embedded configuration which has been aligned to with the server
For a complete list of features and bug fixes included in this release please refer to the release notes. Visit our downloads section to find the latest release.
Cheers, Mircea
Tags: security configuration map reduce
Wednesday, 25 July 2012
Map/Reduce improvements in Infinispan 5.2.0ALPHA2
As our MapReduce implementation grew out of the proof of concept phase (and especially after our users had already production tested it), we needed to remove the most prominent impediment to an industrial grade MapReduce solution that we strive for: distributing reduce phase execution.
Reduce phase prior to the Infinispan 5.2 release was done on a single Infinispan master task node. Therefore, the size of map reduce problems we could support (data size wise) was effectively shrunk to a working memory of a single Infinispan node. Starting with the Infinispan 5.2 release, we have removed this limitation, and reduce phase execution is distributed across the cluster as well. Of course, users still have an option to use MapReduceTask the old way, and we even recommend that particular approach for smaller sized input tasks. We have achieved distribution of reduce phase by relying on Infinispan’s consistent hashing and DeltaAware cache insertion. Here is how we distributed reduce phase execution:
Map phase
MapReduceTask, as it currently does, will hash task input keys and group them by execution node N they are hashed to*. After key node mapping, MapReduceTask sends map function and input keys to each node N. Map function is invoked using given keys and locally loaded corresponding values.
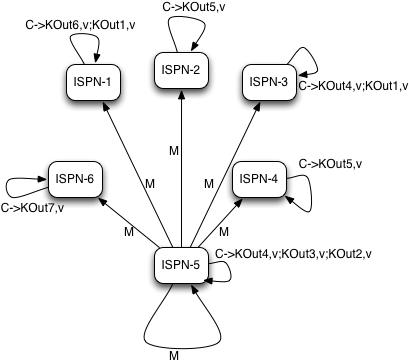 |
|---|
Map and Combine phase |
Results are collected with an Infinispan supplied Collector, and combine phase is initiated. A Combiner, if specified, takes KOut keys and immediately invokes reduce phase on keys. The result of mapping phase executed on each node is KOut/VOut map. There will be one resulting map per execution node N per launched MapReduceTask.
Intermediate KOut/VOut migration phase **
In order to proceed with reduce phase, all intermediate keys and values need to be grouped by intermediate KOut keys. More specifically, as map phases around the cluster can produce identical intermediate keys, all those identical intermediate keys and their values need to be grouped before reduce is executed on any particular intermediate key.
Therefore at the end of combine phase, instead of returning map with intermediate keys and values to the master task node, we instead hash each intermediate key KOut and migrate it with its VOut values to Infinispan node where keys KOut are hashed to. We achieve this using a temporary DIST cache and underlying consistent hashing mechanism. Using DeltaAware cache insertion we effectively collect all VOut values under each KOut for all executed map functions across the cluster.
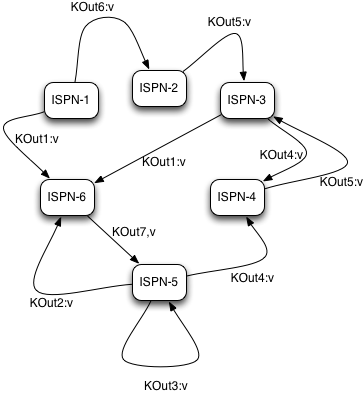 |
|---|
Intermediate KOut/VOut grouping phase |
At this point, map and combine phase have finished its execution; list of KOut keys is returned to a master node and its initiating MapReduceTask. We do not return VOut values as we do not need them at master task node. MapReduceTask is ready to start with reduce phase.
Reduce phase
Reduce phase is easy to accomplish now as Infinispan’s consistent hashing already finished all the hard lifting for us. To complete reduce phase, MapReduceTask groups KOut keys by execution node N they are hashed to. For each node N and its grouped input KOut keys, MapReduceTask sends a reduce command to a node N where KOut keys are hashed. Once reduce command arrives on target execution node, it looks up temporary cache belonging to MapReduce task - and for each KOut key, grabs a list of VOut values, wraps it with an Iterator and invokes reduce on it.
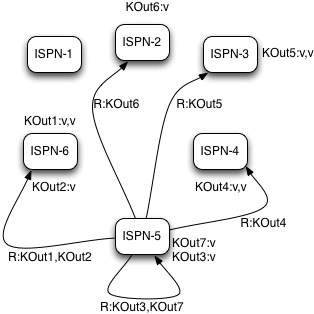 |
|---|
Reduce phase |
A result of each reduce is a map where each key is KOut and value is VOut. Each Infinispan execution node N returns one map with KOut/VOut result values. As all initiated reduce commands return to a calling node, MapReduceTask simply combines all resulting maps into map M and returns M as a result of MapReduceTask.
Distributed reduce phase is turned on by using a MapReduceTask constructor specifying cache to use as input data for the task and boolean parameter distributeReducePhase set to true. Map/Reduce API javadoc and demos are included in distribution.
Moving forward * * For Infinispan 5.2.0 final release we want to make sure the execution of intermediate migration key/value phase is as effective as possible and proven to be lock free for large input tasks as it was in our functional tests. We are also, as always, looking forward to your feedback and suggestions - especially if you have large data input sets ready for our latest MapReduceTask.
Cheers, Vladimir
*If no keys are specified, entire cache key set will be used as in input.
Tags: map reduce
Monday, 23 July 2012
Infinispan 5.2.0.ALPHA2 is here!
Infinispan 5.2.0.ALPHA2 was released last Friday with several additions for those that like to test Infinispan’s bleeding edge capabilities. In this case, it’s out Map/Reduce functionality that’s the star of the show:
Vladimir Blagojevic, one of our Infinispan developers, will be explaining all about these features in a blog post coming right up, so stay tuned! :)
Finally Adrian Nistor, the latest addition to the Infinispan team, has been working on reducing the size of our distribution files by avoiding duplication of jars.
Cheers,
Galder
Tags: release alpha map reduce cache store
Wednesday, 19 January 2011
Introducing distributed execution and MapReduce framework
In case you did not pay attention to the area of large scale distributed computing – there is a revolution going on! It is becoming increasingly evident that the software ecosystems built around so called Big Data are at the forefront of cloud computing innovation. Unfortunately, there has been more debate around determining how big Big Data actually is rather than defining common set of requirements for the large scale Big Data computational platforms.
Stephen O’Grady of RedMonk summarized this phenomena succinctly: “Big Data, like NoSQL, has become a liability in most contexts. Setting aside the lack of a consistent definition, the term is of little utility because it is single-dimensional. Larger dataset sizes present unique computational challenges. But the structure, workload, accessibility and even location of the data may prove equally challenging.”
Zack Urlocker, an advisor and board member to several startup companies in the area of SaaS was equally vocal in his criticism regarding complexity of the existing systems : “You pretty much gotta be near genius level to build systems on top of Cassandra, Hadoop and the like today. These are powerful tools, but very low-level, equivalent to programming client server applications in assembly language. When it works its [sic] great, but the effort is significant and it’s probably beyond the scope of mainstream IT organizations.”
This is exactly where we are positioning Infinispan’s roadmap as we are announcing initial steps into the area of distributed execution and MapReduce framework built on top of Infinispan. Infinispan’s distributed data grid is a most natural fit for such a platform. We have already built an infrastructure for essentially unlimited linear in-memory data scaling. However, having such a data grid without an ability to execute large scale computation on it is like having a Ferrari without a drivers licence. Listening to the criticism regarding the lack of direction in Big Data field and complexity of the existing distributed execution frameworks our focus was primarily on simplicity without sacrificing power and a rich feature set such a framework should have.
Simple distributed execution model
The main interfaces for simple distributed task execution are DistributedCallable and DistributedExecutorService. DistributedCallable is essentially a version of the existing Callable from java.util.concurrent package except that DistributedCallable can be executed in remote JVM and receive input from Infinispan cache. Tasks' main algorithm is essentially unchanged, only the input source is changed. Exisiting Callable implementation most likely gets its input in a form of some Java object/primitive while DistributedCallable gets its input from Infinispan cache. Therefore, users who have already implemented Callable interface to describe their task units would simply extend DistributedCallable and use keys from Infinispan execution environment as input for the task. Implentation of DistributedCallable can in fact continue to support implementation of an already existing Callable while simultaneously be ready for distribited execution by extending DistributedCallable.
public interface DistributedCallable extends Callable {
/**
* Invoked by execution environment after DistributedCallable
* has been migrated for execution to
* a specific Infinispan node.
*
* @param cache
* cache whose keys are used as input data for
* this DistributedCallable task
* @param inputKeys
* keys used as input for this DistributedCallable task
*/
public void setEnvironment(Cache cache, Set inputKeys);
}DistributedExecutorService is an simple extension of a familiar ExecutorService from java.util.concurrent package. However, the advantages of DistributedExecutorService are not to be overlooked. For the existing Callable tasks users would submit to ExecutorService there is an option to submit them for an execution on Infinispan cluster. Infinispan execution environment would migrate this task to an execution node, run the task and return the results to the calling node. Of course, not all Callable task would benefit from this feature. Excellent candidates are long running and computationally intensive tasks.
The second advantage of the DistributedExecutorService is that it allows a quick and simple implementation of tasks that take input from Infinispan cache nodes, execute certain computation and return results to the caller. Users would specify which keys to use as input for specified DistributedCallable and submit that callable for execution on Infinispan cluster. Infinispan runtime would locate the appriate keys, migrate DistributedCallable to target execution node(s) and finally return a list of results for each executed Callable. Of course, users can omit specifying input keys in which case Infinispan would execute DistributedCallable on all keys for a specified cache.
MapReduce model
Infinispan’s own MapReduce model is an adaptation of Google’s original MapReduce. There are four main components in each map reduce task: Mapper, Reducer, Collator and MapReduceTask.
Implementation of a Mapper class is a component of a MapReduceTask invoked once for each input entry K,V. Every Mapper instance migrated to an Infinispan node, given a cache entry K,V input pair transforms that input pair into a result T. Intermediate result T is further reduced using a Reducer.
public interface Mapper {
/**
* Invoked once for each input cache entry
* K,V transforms that input into a result T.
*
* @param key
* the kay
* @param value
* the value
* @return result T
*/
T map(K key, V value);
}Reducer, as its name implies, reduces a list of results T from map phase of MapReduceTask. Infinispan distributed execution environment creates one instance of Reducer per execution node.
public interface Reducer {
/**
* Reduces a result T from map phase and return R.
* Assume that on Infinispan node N, an instance
* of Mapper was mapped and invoked on k many
* key/value pairs. Each T(i) in the list of all
* T's returned from map phase executed on
* Infinispan node N is passed to reducer along
* with previsouly computed R(i-1). Finally the last
* invocation of reducer on T(k), R is returned to a
* distributed task that originated map/reduce
* request.
*
* @param mapResult
* result T of map phase
* @param previouslyReduced
* previously accumulated reduced result
* @return result R
*
*/
R reduce(T mapResult, R previouslyReduced);
}Collator coordinates results from Reducers executed on Infinispan cluster and assembles a final result returned to an invoker of MapReduceTask. #[.cm] #
public interface Collator {
/**
* Collates all results added so far and
* returns result R to invoker of distributed task.
*
* @return final result of distributed task computation
*/
R collate();
/**
* Invoked by runtime every time reduced result
* R is received from executed Reducer on remote
* nodes.
*
* @param remoteNode
* address of the node where reduce phase occurred
* @param remoteResult
* the result R of reduce phase
*/
void reducedResultReceived(Address remoteNode, R remoteResult);
}[.cm]#Finally, MapReduceTask is a distributed task uniting Mapper, Reducer and Collator into a cohesive large scale computation to be transparently parallelized across Infinispan cluster nodes. Users of MapReduceTask need to provide a cache whose data is used as input for this task. Infinispan execution environment will instantiate and migrate instances of provided mappers and reducers seamlessly across Infinispan nodes. Unless otherwise specified using onKeys method input keys filter all available key value pairs of a specified cache will be used as input data for this task. #
[.cm]#MapReduceTask implements a slightly different execution model from the original MapReduce proposed by Google. Here is the pseudocode of the MapReduceTask. #
mapped = list()
for entry in cache.entries:
t = mapper.map(entry.key, entry.value)
mapped.add(t)
r = null
for t in mapped:
r = reducer.reduce(t, r)
return r to Infinispan node that invoked the task
On Infinispan node invoking this task:
reduced_results = invoke map reduce task on all nodes, retrieve map{address:result}
for r in reduced_results.entries:
remote_address = r.key
remote_reduced_result = r.value
collator.add(remote_address, remote_reduced_result)
return collator.collate()Examples
In order to get a better feel for MapReduce framework lets have a look at the example related to Infinispan’s grid file system. How would we calculate total size of all files in the system using MapReduce framework? Easy! Have a look at GridFileSizeExample.
public class GridFileSizeExample {
public static void main(String arg[]) throws Exception {
Cache cache = null;
MapReduceTask task =
new MapReduceTask(cache);
Long result = task.mappedWith(new Mapper() {
@Override
public Long map(String key, GridFile.Metadata value) {
return (long) value.getLength();
}
}).reducedWith(new Reducer() {
@Override
public Long reduce(Long mapResult, Long previouslyReduced) {
return previouslyReduced == null ? mapResult : mapResult + previouslyReduced;
}
}).collate(new Collator(){
private Long result = 0L;
@Override
public Long collate() {
return result;
}
@Override
public void reducedResultReceived(Address remoteNode, Long remoteResult) {
result += remoteResult;
}});
System.out.println("Total filesystem size is " + result + " bytes");
}
}In conclusion, this is not a perfect and final distributed execution and MapReduce API that can satisfy requirements of all users but it is a good start. As we push forward and make it more feature rich while keeping it simple we are continuously looking for your feedback. Together we can reach the ambitious goals set out in the beginning of this article.
Tags: distributed executors map reduce API