Wednesday, 07 March 2018
REST with HTTP/2
HTTP has become one of the most successful and heavily used network protocols around the world. Version 1.0 was created in 1996 and received a minor update 3 years later. But it took more than a decade to create HTTP/2 (which was approved in 2015). Why did it take so long? Well, I wouldn’t tell you all the truth if I didn’t mention an experimental protocol, called SPDY. SPDY was primarily focused on improving performance. The initial results were very promising and inside Google’s lab, the developers measured 55% speed improvement. This work and experience was converted into HTTP/2 proposal back in 2012. A few years later, we can all use HTTP/2 (sometimes called h2) along with its older brother - HTTP/1.1.
Main differences between HTTP/1.1 and HTTP/2

HTTP/1.1 is a text-based protocol. Sometimes this is very convenient, since you can use low level tools, such as Telnet, for hacking. But it doesn’t work very well for transporting large, binary payloads. HTTP/2 solves this problem by using a completely redesigned architecture. Each HTTP message (a request or a response) consists of one or more frames. A frame is the smallest portion of data travelling through a TCP connection. A set of messages is aggregated into a, so called stream.

HTTP/2 allows to lower the number of physical connections between the server and the client by multiplexing logical connections into one TCP connection. Streams allow the server to recognize, which frame belongs to which conversation.
How to connect using HTTP/2?
There are two ways for starting an HTTP/2 conversation.
The first one, and the most commonly used one, is TLS/ALPN. During TLS handshake the server and the client negotiate protocol for further communication. Unfortunately JDK below 9 doesn’t support it by default (there are a couple of workarounds but please refer to your favorite HTTP client’s manual to find some suggestions).
The second one, much less popular, is so called plain text upgrade. During HTTP/1.1 conversation, the client issues an HTTP/1.1 Upgrade header and proposes new conversation protocol. If the server agrees, they start using it. If not, they stick with HTTP/1.1.
The good news is that Infinispan supports both those upgrade paths. Thanks to the ALPN Hack Engine (the credit goes to Stuart Douglas from the Wildfly Team), we support TLS/ALPN without any bootstrap classpath modification.
Configuring Infinispan server for HTTP/2
Infinispan’s REST server already supports plain text upgrades out of the box. TLS/ALPN however, requires additional configuration since the server needs to use a Keystore. In order to make it even more convenient, we support generating keystores automatically when needed. Here’s an example showing how to configure a security realm:
The next step is to bind the security realm to a REST endpoint:
You may also use one of our configuration examples. The easiest way to get it working is to use our Docker image:
Let’s explain a couple of things from the command above:
-
-e "APP_USER=test" - This is a user name we will be used for REST authentication.
-
-e "APP_PASS=test" - Corresponding password.
-
../../docs/examples/configs/standalone-rest-ssl.xml - Here is a ready-to-go configuration with REST and TLS/ALPN support
Unfortunately, HTTP/2 functionality has been broken in 9.2.0.Final. But we promise to fix it as soon as we can :) Please use 9.1.5.Final in the meantime.
Testing using CURL
Curl is one of my favorite tools. It’s very simple, powerful, and… it supports HTTP/2. Assuming that you already started Infinispan server using docker run command, you can put something into the cache:
Once, it’s there, let’s try to get it back:
Let’s analyze CURL switches one by one:
-
-k - Ignores certificate validation. All automatically generated certificates and self-signed and not trusted by default.
-
-v - Debug logging.
-
-u test:test - Username and password for authentication.
-
-d test - This is the payload when invoking HTTP POST.
-
-H “Accept: text/plain” - This tells the server what type of data we’d like to get in return.
Conclusions and links
I hope you enjoyed this small tutorial about HTTP/2. I highly encourage you to have a look at the links below to learn some more things about this topic. You may also measure the performance of your app when using HTTP/1.1 and HTTP/2. You will be surprised!
-
High Performance Browser Networking - One of the best books about HTTP and network performance. Most of the graphics in this article has been copied from that book. I highly recommend it!
Tags: docker server http/2 rest
Tuesday, 12 December 2017
First steps with Vert.x and Infinispan REST API (Part 1)
Welcome to the first in a multi-part series of blog posts about creating Eclipse Vert.x applications with Infinispan. The purpose of this first tutorial is to showcase how to create a REST API.
All the code of this tutorial is available in this GitHub repository. The backend is a Java project using Maven, so all the needed dependencies can be found in the pom.xml.
==
What is Vert.x ?
Vert.x is a tool-kit for building reactive applications on the JVM. It’s an event driven and non blocking tool-kit. It is based on the Reactor Pattern, like Node.js, but unlike Node it can easily use all the cores of your machine so you can create highly concurrent and performant applications. Code examples can be found in this repository.
==
REST API
Let’s start creating a simple endpoint that will display a welcome message on '/'. In Vert.x this is done by creating a Verticle. A verticle is a unit of deployment and processes incoming events over an event-loop. Event-loops are used in asynchronous programming models. I won’t spend more time here explaining these concepts as this is very well done in this Devoxx Vert.x talk or in the documentation available here.
We need to override the start method, create a 'router' so '/' requests can be handled, and finally create a http server.
The most important thing to remember about vert.x, is that we can NEVER EVER call blocking code (we will see how to deal with blocking API’s just after). If we do so, we will block the event loop and we won’t be able to serve incoming requests properly.
Run the main method, go to your browser to http://localhost:8081/ and we see the welcome message !
Connecting with Infinispan
Now we are going to create a REST API that uses Infinispan. The purpose here is to post and get names by id. We are going to use the default cache in Infinispan for this example, and we will connect to it remotely. To do that, we are going to use the Infinispan hotrod protocol, which is the recommended way to do it (but we could use REST or Memcached protocol too)
Start Infinispan locally
The first thing we are going to do is to run an Infinispan Server locally. We download the Infinispan Server from here, unzip the downloaded file and run ./bin/standalone.sh.
If you are using Docker on Linux, you can use the Ihttps://hub.docker.com/r/jboss/infinispan-server/[nfinispan Docker Image Available] easily. If you are using Docker for Mac, at the time of this writing there is an issue with internal IP addresses and they can’t be called externally. Different workarounds exist to solve the problem, but the easiest thing for this example is simply downloading and running the standalone server locally. We will see how to use the docker image in Openshift just after.
The hotrod server is listening in localhost:11222.
Connect the client to the server
The code we need to connect with Infinispan from our java application is the following :
This code is blocking. As I said before, we can’t block the event loop and this will happen if we directly call these API’s from a verticle. The code must be called using vertx.executeBlocking method, and passing a Handler. The code in the handler will be executed from a worker thread pool and will pass the result back asynchronously. Instead of overriding the start method, we are going to override start(Future<Void> startFuture). This way, we are going to be able to handle errors.
To stop the client, the API supplies a non blocking method that can be called when the verticle is stopped, so we are safe on that.
We are going to create an abstract CacheAccessVerticle where we will initialise the manager and get default cache. When everything is correct and the defautCache variable is initialised, we will log a message and execute the initSuccess abstract method.
REST API to create names
We are going to add 3 new endpoints.
-
GET /api displays the API name
-
POST /api/cutenames creates a new name
-
GET /api/cutenames/id displays a name by id
CuteNamesRestAPI verticle can now extend this class and override the initSuccess method instead of the start method.
POST
Our goal is to use a curl to create a name like this :
curl -X POST \ -H "Content-Type: application/json" \ -d '\{"name":"Oihana"}' "http://localhost:8081/api/cutenames"
For those that are not familiar with basques names, Oihana means 'rainforest' and is a super cute name. Those who know me will confirm that I’m absolutely not biased making this statement.
To read the body content, we need to add a body handler to the route, otherwise the body won’t be parsed. This is done by calling router.route().handler(BodyHandler.create()).
The handler that will handle the post method in '/api/cutenames' is a RoutingContext handler. We want to create a new name in the default cache. For that, we will call putAsync method from the defaultCache.
The server responds 201 when the name is correctly created, and 400 when the request is not correct.
GET by id
To create a get endpoint by id, we need to declare a route that will take a parameter :id. In the route handler, we are going to call getAsync method.
If we run the main, we can POST and GET names using curl !
curl -X POST -H "Content-Type: application/json" \ -d '\{"id":"42", "name":"Oihana"}' \ "http://localhost:8081/api/cutenames"
Cute name added
curl -X GET -H "Content-Type: application/json" \ "http://localhost:8081/api/cutenames/42" * \{"name":"Oihana"}*
==
Wrap up
We have learned how to create a REST API with Vert.x, powered by Infinispan. The repository has some unit tests using the web client. Feedback is more than welcome to improve the code and the provided examples. I hope you enjoyed this tutorial ! On the next tutorial you will learn how to create a PUSH API.
Tags: vert.x rest API
Sunday, 10 September 2017
Multi-tenancy - Infinispan as a Service (also on OpenShift)
In recent years Software as a Service concept has gained a lot of traction. I’m pretty sure you’ve used it many times before. Let’s take a look at a practical example and explain what’s going on behind the scenes.
Practical example - photo album application
Imagine a very simple photo album application hosted within the cloud. Upon the first usage you are asked to create an account. Once you sign up, a new tenant is created for you in the application with all necessary details and some dedicated storage just for you. Starting from this point you can start using the album - download and upload photos.
The software provider that created the photo album application can also celebrate. They have a new client! But with a new client the system needs to increase its capacity to ensure it can store all those lovely photos. There are also other concerns - how to prevent leaking photos and other data from one account into another? And finally, since all the content will be transferred through the Internet, how to secure transmission?
As you can see, multi-tenancy is not that easy as it would seem. The good news is that if it’s properly configured and secured, it might be beneficial both for the client and for the software provider.
Multi-tenancy in Infinispan
Let’s think again about our photo album application for a moment. Whenever a new client signs up we need to create a new account for him and dedicate some storage. Translating that into Infinispan concepts this would mean creating a new CacheContainer. Within a CacheContainer we can create multiple Caches for user details, metadata and photos. You might be wondering why creating a new Cache is not sufficient? It turns out that when a Hot Rod client connects to a cluster, it connects to a CacheContainer exposed via a Hot Rod Endpoint. Such a client has access to all Caches. Considering our example, your friends could possibly see your photos. That’s definitely not good! So we need to create a CacheContainer per tenant. Before we introduced Multi-tenancy, you could expose each CacheContainer using a separate port (using separate Hot Rod Endpoint for each of them). In many scenarios this is impractical because of proliferation of ports. For this reason we introduced the Router concept. It allows multiple clients to access their own CacheContainers through a single endpoint and also prevents them from accessing data which doesn’t belong to them. The final piece of the puzzle is transmitting sensitive data through an unsecured channel such as the Internet. The use of TLS encryption solves this problem. The final outcome should look like the following:
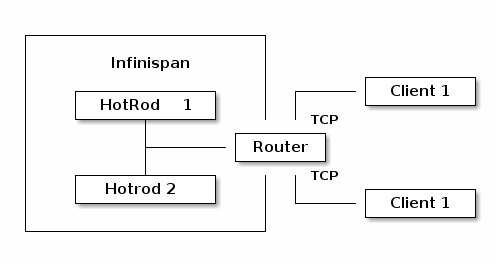
The Router component on the diagram above is responsible for recognizing data from each client and redirecting it to the appropriate Hot Rod endpoint. As the name implies, the router inspects incoming traffic and reroutes it to the appropriate underlying CacheContainer. To do this it can use two different strategies depending on the protocol: TLS/SNI for the Hot Rod protocol, matching each server certificate to a specific cache container and path prefixes for REST. The SNI strategy detects the SNI Host Name (which is used as tenant) and also requires TLS certificates to match. By creating proper trust stores we can match which tenant can access which CacheContainers. URL path prefix is very easy to understand, but it is also less secure unless you enable authentication. For this reason it should not be used in production unless you know what you are doing (the SNI strategy for the REST endpoint will be implemented in the near future). Each client has its own unique REST path prefix that needs to be used for accessing the data (e.g. http://127.0.0.1:8080/rest/client1/fotos/2).
Confused? Let’s clarify this with an example.
Foto application sample configuration
The first step is to generate proper key/trust stores for the server and client:
The next step is to configure the server. The snippet below shows only the most important parts:
Let’s analyze the most critical lines:
-
7, 15 - We need to add generated key stores to the server identities
-
25, 30 - It is highly recommended to use separate CacheContainers
-
38, 39 - A Hot Rod connector (but without socket binding) is required to provide proper mapping to CacheContainer. You can also use many useful settings on this level (like ignored caches or authentication).
-
42 - Router definition which binds into default Hot Rod and REST ports.
-
44 - 46 - The most important bit which states that only a client using SSLRealm1 (which uses trust store corresponding to client_1_server_keystore.jks) and TLS/SNI Host name client-1 can access Hot Rod endpoint named multi-tenant-hotrod-1 (which points to CacheContainer multi-tenancy-1).
Improving the application by using OpenShift
Hint: You might be interested in looking at our previous blog posts about hosting Infinispan on OpenShift. You may find them at the bottom of the page.
So far we’ve learned how to create and configure a new CacheContainer per tenant. But we also need to remember that system capacity needs to be increased with each new tenant. OpenShift is a perfect tool for scaling the system up and down. The configuration we created in the previous step almost matches our needs but needs some tuning.
As we mentioned earlier, we need to encrypt transport between the client and the server. The main disadvantage is that OpenShift Router will not be able to inspect it and take routing decisions. A passthrough Route fits perfectly in this scenario but requires creating TLS/SNI Host Names as Fully Qualified Application Names. So if you start OpenShift locally (using oc cluster up) the tenant names will look like the following: client-1-fotoalbum.192.168.0.17.nip.io.
We also need to think how to store generated key stores. The easiest way is to use Secrets:
Finally, a full DeploymentConfiguration:
If you’re interested in playing with the demo by yourself, you might find a working example here. It mainly targets OpenShift but the concept and configuration are also applicable for local deployment.
Tags: security hotrod server multi-tenancy rest
Tuesday, 21 March 2017
Docker image security changes

In the latest 9.0.0.CR3 version, the Infinispan REST endpoint is secured by default, and in order to facilitate remote access, the Docker image has some changes related to the security.
The image now creates a default user login upon start; this user can be changed via environment variables if desired:
You can check if the settings are in place by manipulating data via REST. Trying to do a curl without credentials should lead to a 401 response:
So make sure to always include the credentials from now on when interacting with the Rest endpoint! If using curl, this is the syntax:
And that’s all for this post. To find out more about the Infinispan Docker image, check the documentation, give it a try and let us know if you have any issues or suggestions!
Tags: docker security server rest
Monday, 09 September 2013
Infinispan 6.0.0.Alpha4 out with new CacheLoader/CacheWriter API!
Infinispan 6.0.0.Alpha4 is now with a few very important changes, particularly around cache stores. We’ve completely revamped the cache store/loader API to align it a bit better with JSR-107 (old CacheStore has become CacheWriter) and to simplify creation of new implementations. The new CacheLoader and CacheWriter should help implementors focus on the important operations and reduce the coding time. We’ve also created AdvancedCacheLoader and AdvancedCacheWriter in order to separate for bulk operations or purging for those implementations that wish optionally implement them. Expect a blog post from Mircea in the next few days providing many more details on this topic.
This new Infinispan version comes with other important goodies:
-
Rolling upgrades of a Infinsipan REST cluster
-
Support for Cache-Control headers for REST operations
-
Remote querying server modules and Hot Rod client update
-
REST and LevelDB stores added to Infinispan Server
-
KeyFilters can now be applied to Cache listeners
-
Allow Cache listener events to be invoked only on the primary data owner
For a complete list of features and fixes included in this release please refer to the release notes. Visit our downloads section to find the latest release and if you have any questions please check our forums, our mailing lists or ping us directly on IRC.
Cheers,
Galder
Tags: release leveldb listeners alpha rest cache store query
Thursday, 23 May 2013
Interoperability between Embedded and Server Endpoints is here!
As mentioned by Mircea in the Infinispan 5.3.0.Beta2 release blog post, interoperability between embedded Infinispan and remote Infinispan modes, including Hot Rod, Memcached and REST is now here!
What this means is that you should be able to store data via one of the endpoints and retrieve data from a different one. So, I can store an Java object using the Java Hot Rod client, and I can retrieve it using the embedded interface.
Documentation for this new interoperability, or compatibility mode, can be found here, including the key aspects of this new functionality, configuration and links to some examples.
As we head towards the later part of the Infinispan 5.3 series, if you’re interested in accessing data in multiple ways, give it a go and let us know what you think!
Cheers, Galder
Tags: hotrod interoperability memcached rest
Thursday, 13 May 2010
Client/Server architectures strike back, Infinispan 4.1.0.Beta1 is out!
I’m delighted to announce the release of Infinispan 4.1.0.BETA1. For this, our first beta release of the 4.1 series, we’ve finished Hot Rod and Memcached based server implementations and a Java-based Hot Rod client has been developed as a reference implementation. Starting with 4.1.0.BETA1 as well, thanks to help of Tom Fenelly, Infinispan caches can be exposed over a WebSocket.
A detailed change log is available and the release is downloadable from the usual place.
For the rest of the blog post, we’d like to share some of the objectives of Infinispan 4.1 with the community. Here at ‘chez Infinispan’ we’ve been repeating the same story over and over again: http://www.parleys.com/sl=1&st=5&id=1589[‘Memory is the new Disk, Disk is the new Tape’] and this release is yet another step to educate the community on this fact. Client/Server architectures based around [#SPELLING_ERROR_12 .blsp-spelling-error]#Infinispan data grids are key to enabling this reality but in case you might be wondering, why would someone use Infinispan in a client/server mode compared to using it as peer-to-peer (p2p) mode? How does the client/server architecture enable memory to become the new disk?
Broadly speaking, there three areas where a Infinispan client/server architecture might be chosen over p2p one:
1. Access to Infinispan from a non-JVM environment
Infinispan’s roots can be traced back to JBoss Cache, a caching library developed to provide J2[SPELLING_ERROR_19 .blsp-spelling-error]#EE application servers with data replication. As such, the primary way of accessing Infinispan or JBoss Cache has always been via direct calls coming from the same JVM. However, as we have repeated it before, Infinispan’s goal is to provide much more than that, it aims to provide data grid access to any software application that you can think of and this obviously requires Infinispan to enable access from non-Java environments.
Infinispan comes with a series of server modules that enable that precisely. All you have to do is decide which API suits your environment best. Do you want to enable access direct access to Infinispan via HTTP? Just use our REST or WebSocket modules. Or is it the case that you’re looking to expand the capabilities of your Memcached based applications? Start an Infinispan-backed and your existing Memcached clients will be able to talk to it immediately. Or maybe even you’re interested in accessing Infinispan via Hot Rod? Then, gives us a hand developing non-Java clients that can talk the Hot Rod protocol! :).
2. Infinispan as a dedicated data tier
Quite often applications running running a p2p environment have caching requirements larger than the heap size in which case it makes a lot of sense to separate caching into a separate dedicated tier.
It’s also very common to find businesses with varying work loads overtime where there’s a need to start business processing servers to deal with increased load, or stop them when work load is reduced to lower power consumption. When Infinispan data grid instances are deployed alongside business processing servers, starting/stopping these can be a slow process due to state transfer, or rehashing, particularly when large data sets are used. Separating Infinispan into a dedicated tier provides faster and more predictable server start/stop procedures – ideal for modern cloud-based deployments where elasticity in your application tier is important.
It’s common knowledge that optimizations for large memory usage systems compared to optimizations for CPU intensive systems are very different. If you mix both your data grid and business logic under the same roof, finding a balanced set of optimizations that keeps both sides happy is difficult. Once again, separating the data and business tiers can alleviate this problem.
You might be wondering that if Infinispan is moved to a separate tier, access to data now requires a network call and hence will hurt your performance in terms of time per call. However, separating tiers gives you a much more scalable architecture and your data is never more than 1 network call away. Even if the dedicated Infinispan data grid is configured with distribution, a Hot Rod smart-client implementation - such as the Java reference implementation shipped with Infinispan 4.1.0.BETA1 - can determine where a particular key is located and hit a server that contains it directly.
3. Data-as-a-Service (DaaS)
Increasingly, we see scenarios where environments host a multitude of applications that share the need for data storage, for example in Plattform-as-a-Service cloud-style environments (whether public or internal). In such configurations, you don’t want to be launching a data grid per each application since it’d be a nightmare to maintain – not to mention resource-wasteful. Instead you want deployments or applications to start processing as soon as possible. In these cases, it’d make a lot of sense to keep a pool of Infinispan data grid nodes acting as a shared storage tier. Isolated cache access could easily achieved by making sure each application uses a different cache name (i.e. the application name could be used as cache name). This can easily achieved with protocols such as Hot Rod where each operation requires a cache name to be provided.
Regardless of the scenarios explained above, there’re some common benefits to separating an Infinispan data grid from the business logic that accesses it. In fact, these are very similar to the benefits achieved when application servers and databases don’t run under the same roof. By separating the layers, you can manage each layer independently, which means that adding/removing nodes, maintenance, upgrades…etc can be handled independently. In other words, if you wanna upgrade your application server or servlet container, you don’t need to bring down your data layer.
All of this is available to you now, but the story does not end here. Bearing in mind that these client/server modules are based around reliable TCP/IP, using Netty, they could also in the future form the base of new functionality. For example, client/server modules could be linked together to connect geographically separated Infinispan data grids and enable different disaster recovery strategies.
So, download Infinispan 4.1.0.BETA1 righty, give a try to these new modules and let us know your thoughts.
Finally, don’t forget that we’ll be talking about Hot Rod in Boston at the end of June for the first ever JUDCon. Don’t miss out!
Cheers,
Galder
Tags: hotrod websocket memcached rest cloud storage
Friday, 12 February 2010
Poll: How do you interact with Infinispan?
While discussing the different ways to interact with Infinispan, we decided to open up a poll so that people tell us how they expect to be using Infinispan. Do you use Infinispan directly on the same VM? Or do you use REST? Are you planning to interact via memcached or Hot Rod interface?
The poll can be found here. Please make sure that if you vote, you add a comment indicating the reasons why you chosen that option.
Cheers, Galder
Tags: hotrod memcached rest
Tuesday, 15 September 2009
Introducing the Infinispan (REST) server
Introducing the Infinispan RESTful server !

The Infinispan RESTful server combines the whole grain goodness of RESTEasy (JAX-RS, or JSR-311) with Infinispan to provide a web-ready RESTful data grid.
Recently I (Michael) spoke to Manik about an interesting use case, and he indicated great interest in such a server. It wasn’t a huge amount of work to do the initial version - given that JAX-RS is designed to make things easy.
For those that don’t know: RESTful design is using the well proven and established http/web standards for providing services (as a simple alternative to WS-*) - if that still isn’t enough, you can read more here. So for Infinispan that means that any type of client can place data in the Infinispan grid.
So what would you use it for? For non java clients, or clients where you need to use HTTP as the transport mechanism for caching/data grid needs. A content delivery network (?) - push data into the grid, let Infinispan spread it around and serve it out via the nearest server. See here for details on using http and URLs with it.
In terms of clients - you only need HTTP - no binary dependencies or libraries needed (the wiki page has some samples in ruby/python, also in the project source).
Where does it live? The server is a module in Infinispan under /server/rest (for the moment, we may re-arrange the sources at a later date).
Getting it. Currently you can download the war from the wiki page, or build it yourself (as it is still new, early days). This is at present a war file (tested on JBoss AS and Jetty) which should work in most containers - we plan to deliver a stand alone server (with an embedded JBoss AS) Real Soon Now.
Questions: (find me on the dev list, or poke around the wiki).

 Implemented in scala: After chatting with Manik and co, we decided this would serve as a good test bed to "test the waters" on Scala - so this module is written in scala - it worked just fine with RESTEasy, and Infinispan (which one would reasonably expect, but nice when things do work as advertised !).
Implemented in scala: After chatting with Manik and co, we decided this would serve as a good test bed to "test the waters" on Scala - so this module is written in scala - it worked just fine with RESTEasy, and Infinispan (which one would reasonably expect, but nice when things do work as advertised !).
Tags: rest server